




Deep Learning Training Performance on Dell EMC PowerEdge R7525 Servers with NVIDIA A100 GPUs
Mon, 21 Jun 2021 20:03:09 -0000
|Read Time: 0 minutes
Overview
The Dell EMC PowerEdge R7525 server, which was recently released, supports NVIDIA A100 Tensor Core GPUs. It is a two-socket, 2U rack-based server that is designed to run complex workloads using highly scalable memory, I/O capacity, and network options. The system is based on the 2nd Gen AMD EPYC processor (up to 64 cores), has up to 32 DIMMs, and has PCI Express (PCIe) 4.0-enabled expansion slots. The server supports SATA, SAS, and NVMe drives and up to three double-wide 300 W or six single-wide 75 W accelerators.
The following figure shows the front view of the server:
Figure 1: Dell EMC PowerEdge R7525 server
This blog focuses on the deep learning training performance of a single PowerEdge R7525 server with two NVIDIA A100-PCIe GPUs. The results of using two NVIDIA V100S GPUs in the same PowerEdge R7525 system are presented as reference data. We also present results from the cuBLAS GEMM test and the ResNet-50 model form the MLPerf Training v0.7 benchmark.
The following table provides the configuration details of the PowerEdge R7525 system under test:
Component | Description |
Processor | AMD EPYC 7502 32-core processor |
Memory | 512 GB (32 GB 3200 MT/s * 16) |
Local disk | 2 x 1.8 TB SSD (No RAID) |
Operating system | RedHat Enterprise Linux Server 8.2 |
GPU | Either of the following:
|
CUDA driver | 450.51.05 |
CUDA toolkit | 11.0 |
Processor Settings > Logical Processors | Disabled |
System profiles | Performance |
CUDA Basic Linear Algebra
The CUDA Basic Linear Algebra (cuBLAS) library is the CUDA version of standard basic linear algebra subroutines, part of CUDA-X. NVIDIA provides the cublasMatmulBench binary, which can be used to test the performance of general matrix multiplication (GEMM) on a single GPU. The results of this test reflect the performance of an ideal application that only runs matrix multiplication in the form of the peak TFLOPS that the GPU can deliver. Although GEMM benchmark results might not represent real-world application performance, it is still a good benchmark to demonstrate the performance capability of different GPUs.
Precision formats such as FP64 and FP32 are important to HPC workloads; precision formats such as INT8 and FP16 are important for deep learning inference. We plan to discuss these observed performances in our upcoming HPC and inference blogs.
Because FP16, FP32, and TF32 precision formats are imperative to deep learning training performance, the blog focuses on these formats.
The following figure shows the results that we observed:
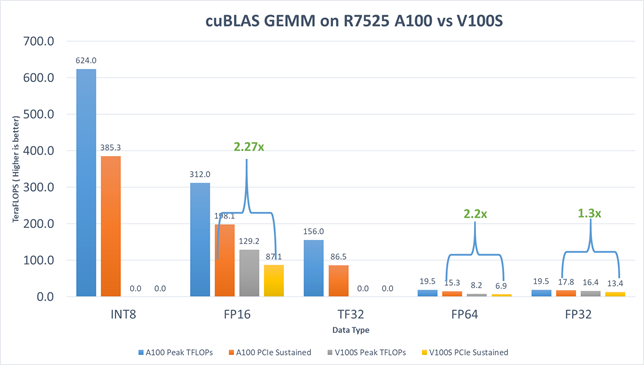
Figure 2: cuBLAS GEMM performance on the PowerEdge R7525 server with NVIDIA V100S-PCIe-32G and NVIDIA A100-PCIe-40G GPUs
The results include:
- For FP16, the HGEMM TFLOPs of the NVIDIA A100 GPU is 2.27 times faster than the NVIDIA V100S GPU.
- For FP32, the SGEMM TFLOPs of the NVIDIA A100 GPU is 1.3 times faster than the NVIDIA V100S GPU.
- For TF32, performance improvement is expected without code changes for deep learning applications on the new NVIDIA A100 GPUs. This expectation is because math operations are run on NVIDIA A100 Tensor Cores GPUs with the new TF32 precision format. Although TF32 reduces the precision by a small margin, it preserves the range of FP32 and strikes an excellent balance between speed and accuracy. Matrix multiplication gained a sizable boost from 13.4 TFLOPS (FP32 on the NVIDIA V100S GPU) to 86.5 TFLOPS (TF32 on the NVIDIA A100 GPU).
MLPerf Training v0.7 ResNet-50
MLPerf is a benchmarking suite that measures the performance of machine learning (ML) workloads. The MLPerf Training benchmark suite measures how fast a system can train ML models.
The following figure shows the performance results of the ResNet-50 under the MLPerf Training v0.7 benchmark:

Figure 3: MLPerf Training v0.7 ResNet-50 performance on the PowerEdge R7525 server with NVIDIA V100S-PCIe-32G and NVIDIA A100-PCIe-40G GPUs
The metric for the ResNet-50 training is the minutes that the system under test spends to train the dataset to achieve 75.9 percent accuracy. Both runs using two NVIDIA A100 GPUs and two NVIDIA V100S GPUs converged at the 40th epoch. The NVIDIA A100 run took 166 minutes to converge, which is 1.8 times faster than the NVIDIA V100S run. Regarding throughput, two NVIDIA A100 GPUs can process 5240 images per second, which is also 1.8 times faster than the two NVIDIA V100S GPUs.
Conclusion
The Dell EMC PowerEdge R7525 server with two NVIDIA A100-PCIe GPUs demonstrates optimal performance for deep learning training workloads. The NVIDIA A100 GPU shows a greater performance improvement over the NVIDIA V100S GPU.
To evaluate deep learning and HPC workload and application performance with the PowerEdge R7525 server powered by NVIDIA GPUs, contact the HPC & AI Innovation Lab.
Next steps
We plan to provide performance studies on:
- Three NVIDIA A100 GPUs in a PowerEdge R7525 server
- Results of other deep learning models in the MLPerf Training v0.7 benchmark
- Training scalability results on multiple PowerEdge R7525 servers