




Deep Learning Performance on MLPerf™ Training v1.0 with Dell EMC DSS 8440 Servers
Mon, 16 Aug 2021 19:23:48 -0000
|Read Time: 0 minutes
Abstract
This blog provides MLPerf™ Training v1.0 data center closed results for Dell EMC DSS 8440 servers running the MLPerf training benchmarks. Our results show optimal training performance for the DSS 8440 configurations on which we chose to run training benchmarks. Also, we can expect higher performance gains by upgrading to the NVIDIA A100 accelerators running the deep learning workload on DSS 8440 servers.
Background
The DSS 8440 server allows up to 10 double-wide GPUs in the PCIe. This configuration makes it an aptly suited server for high compute that is required to run workloads such as deep learning training.
MLPerf Training v1.0 benchmark models address problems such as image classification, medical image segmentation, light weight and heavy weight object detection, speech recognition, natural language processing (NLP), and recommendation and reinforcement learning.
As of June 2021, MLPerf Training has become more mature and has successfully completed v1.0, which is the fourth submission round of MLPerf training. See this blog for new features of the MLPerf Training v1.0 benchmark.
Testbed
The results for the models that are submitted with the DSS 8440 server include:
- 1 x DSS 8440 (x8 A100-PCIE-40GB)—All eight models, which include ResNet50, SSD, MaskRCNN, U-Net3D, BERT, DLRM, Minigo, and RNN-T
- 2 x DSS 8440 (x16 A100-PCIE-40GB)—Two-nodes ResNet50
- 3 x DSS 8440 (x24 A100-PCIe-40GB)—Three-nodes ResNet50
- 1 x DSS 8440 (x8 A100-PCIE-40GB, connected with NVLink Bridges)—BERT
We chose BERT with NVLink Bridge because BERT has plenty of card-to-card communication that allows NVLink Bridge benefits.
The following table shows a single node DSS8440 hardware configuration and software environment:
Table 1: DSS 8440 node specification
Hardware | |
Platform | DSS 8440 |
CPUs per node | 2 x Intel Xeon Gold 6248R CPU @ 3.00 GHz |
Memory per node | 768 GB (24 x 32 GB) |
GPU | 8 x NVIDIA A100-PCIE-40GB (250 W) |
Host storage | 1x 1.5 TB NVMe + 2x 512 GB SSD |
Host network | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software | |
Operating system | CentOS Linux release 8.2.2004 (Core) |
GPU driver | 460.32.03 |
OFED | 5.1-2.5.8.0 |
CUDA | 11.2 |
MXNet | NGC MXNet 21.05 |
PyTorch | NGC PyTorch 21.05 |
TensorFlow | NGC TensorFlow 21.05-tf1 |
cuBLAS | 11.5.1.101 |
NCCL version | 2.9.8 |
cuDNN | 8.2.0.51 |
TensorRT version | 7.2.3.4 |
Open MPI | 4.1.1rc1 |
Singularity | 3.6.4-1.el8 |
MLPerf Training 1.0 benchmark results
Single node performance
The following figure shows the performance of the DSS 8440 server on all training models:
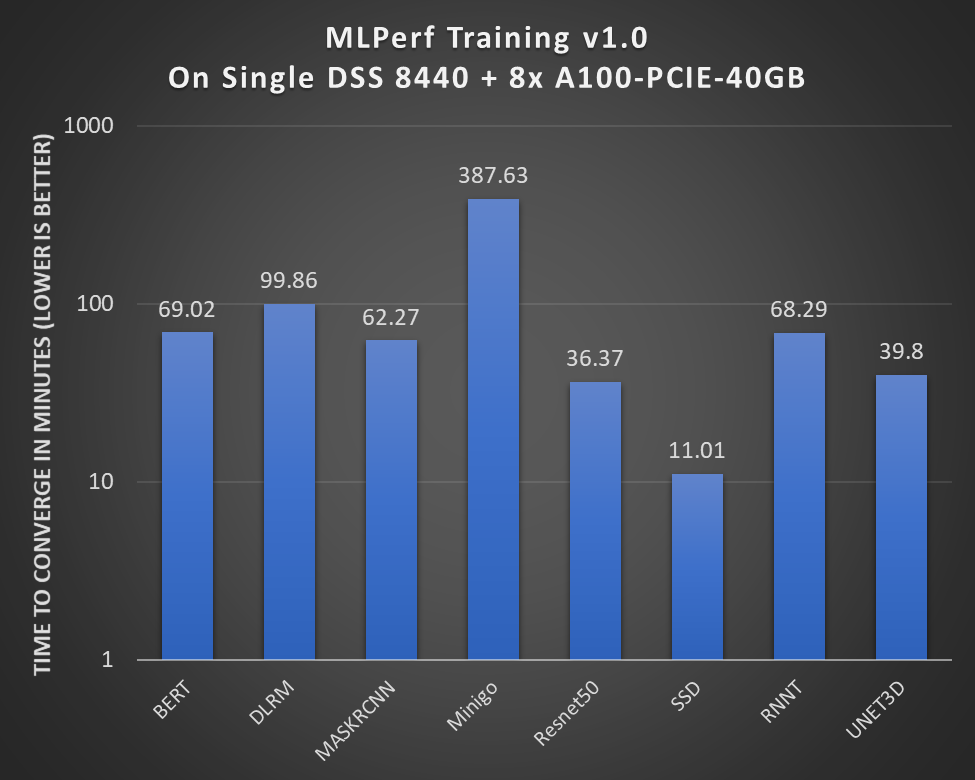
Figure 1: Performance of a single node DSS 8440 with 8 x A100-PCIE-40GB GPUs
The y axis is an exponentially scaled axis. MLPerf training measures the submission by assessing how many minutes it took for a system under test to converge to the target accuracy while meeting all the rules.
Key takeaways include:
- All our results were officially submitted to the MLCommons™ Consortium and are verified.
- The DSS 8440 server was able to run all the models in the MLPerf training v1.0 benchmark across different areas such as vision, language, commerce, and research.
- The DSS8440 server is a good candidate to fit into the high performance per watt category.
- With a thermal design power (TDP) of 250 W, the A100 PCIE 40 GB offers high throughput for all the benchmarks. This throughput, when compared to other GPUs that have a higher TDP, offers almost similar throughputs for many benchmarks (see the results here).
- The DLRM model takes more time to converge because the underlying Merlin HurgeCTR framework implementation is optimized for an SXM4 form factor. Our Dell EMC PowerEdge XE8545 Server supports this form factor.
Overall, by upgrading the accelerator to an NVIDIA A100 PCIE 40 GB, 2.1 to 2.4 times performance improvements can be expected, compared to the previous MLPerf Training v0.7 round that used previous generation NVIDIA V100 PCIe GPUs.
Multinode scaling
Multinode training is critical for large machine learning workloads. It provides a significant amount of compute power, which accelerates the training process linearly. While a single node training certainly converges, multinode training offers higher throughput and converges faster.
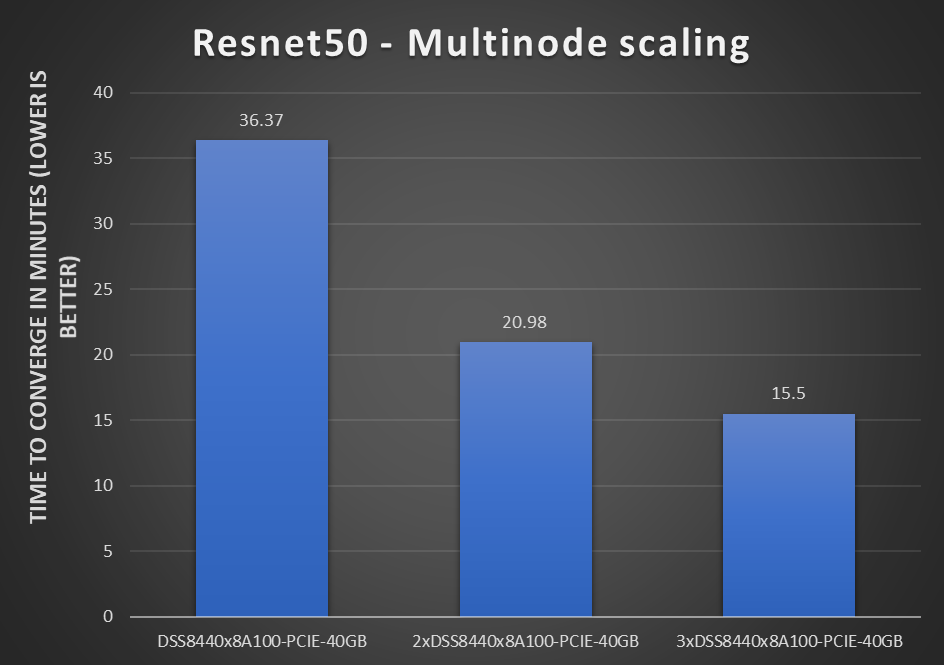
Figure 2: Resnet50 multinode scaling on a DSS8440 server with one, two, and three nodes
These results are for multiple (up to three) DSS 8440 servers that are tested with the Resnet50 model.
Note the following about these results:
- Adding more nodes to the same training task helps to reduce the overall turnaround time of training. This reduction helps data scientists to adjust their models rapidly. Some larger models might run days on the fastest single GPU server; multinode training can reduce the time to hours or minutes.
- To be comparable and comply with the RCP rules in MLPerf training v1.0, we keep the global batch sizes the same with two and three nodes. This configuration is considered strong scaling as the workload and the global batch sizes do not increase with the GPU numbers for the multinode scaling setting. Because of RCP constraints, we cannot see linear scaling.
- We see higher throughput numbers with larger batch sizes.
- The ResNet50 model scales well on the DSS 8440 server.
In general, adding more DSS 8440 servers to a large deep learning training problem helps to reduce time spent on those training workloads.
NVLink Bridges
NVLINK Bridges are bridge boards that link a pair of GPUs to help workloads that exchange data frequently between GPUs. Those A100 PCIe GPUs on the DSS 8440 server can support three bridges per each GPU pair. The following figure shows the difference for the BERT model with and without NVLink Bridges:
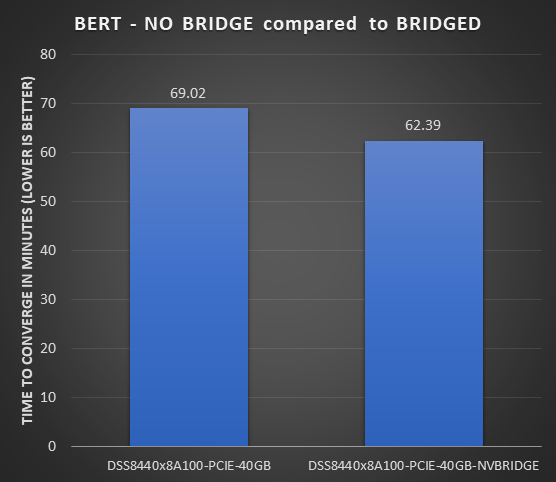
Figure 3: BERT converge-time difference without and with NVLink Bridges on a DSS 8440 server
- An NVLink Bridge offers over 10 percent faster convergence for the BERT model.
- Because the topology of the NVLink Bridge hardware is relatively new, there might be opportunities for this topology to translate into higher performance gains as the supporting software matures.
Conclusion and future work
Dell EMC DSS 8440 servers are an excellent fit for modern deep learning training workloads helping solve different problems spanning image classification, medical image segmentation, light weight and heavy weight object detection, speech recognition, natural language processing (NLP), recommendation and reinforcement learning. These servers offer high throughput and are an excellent scalable medium to run multinode jobs. They offer faster convergence while meeting training constraints. Paring the NVLink Bridge with NVIDIA A100 PCIE accelerators can improve throughput for higher inter-GPU communication models like BERT. Furthermore, data center administrators can expect to improve deep learning training throughput by orders of magnitude by upgrading to NVIDIA A100 accelerators from previous generation accelerators if their data center is already using DSS 8440 servers.
With recent support of the A100-PCIe-80GB GPU on the DSS8440 server, we plan to conduct MLPerf training benchmarks with 10 GPUs in each server, which will allow us to provide a comparison of scale-up and scale-out performance.