




Code Assistant Made Easy by Dell Enterprise Hub


Overview
With the rise of large language models (LLMs) as powerful code assistants, LLMs are proving to be invaluable tools for developers. Code, after all, is a language – a precise expression of intent understood by compilers and programs. Since LLMs excel at understanding and manipulating language, it's no wonder they excel as code assistants, especially when trained on vast amounts of code in various languages like C, Python, and Ruby.
The recently-released Llama 3 8B model surpasses even CodeLlama, a previous generation model specifically designed for code generation. This blog delves into a method for implementing a powerful code assistant leveraging Llama 3 models.
Implementation
Architecture
Visual Studio Code—or VS Code for short—is a lightweight but powerful code editor that runs on windows, Mac, and Linux. It supports many languages, extensions, debugging and Git integrations, and more. As such, it made sense for us to build this Llama3-powered code assistant to integrate into VS Code. The continue extension of VS Code will be the communication path between VS Code and Llama 3.
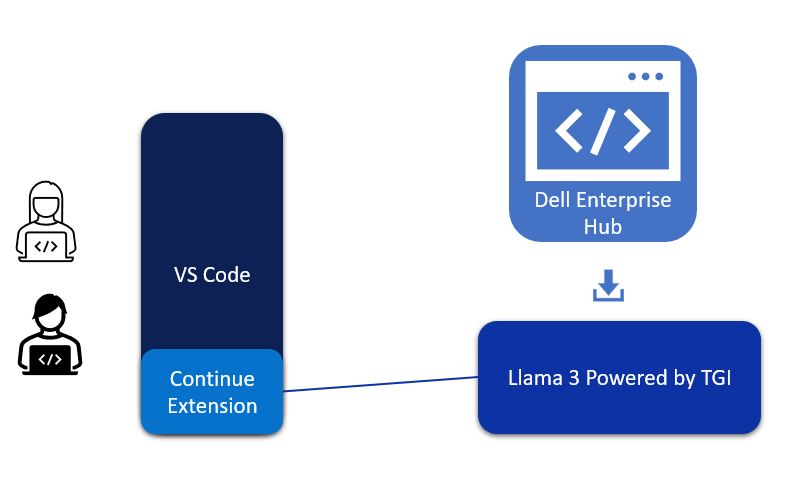
Figure 1. Architectural diagram of VS Code, Continue Extension, and Llama 3 deployed on-premise by Dell Enterprise Hub to create a powerful code assistant
The continue extension takes user requests and converts them into RESTful API calls to the Hugging Face TGI (Text Generation Inference) inference endpoint, which is running Llama 3 from Dell Enterprise Hub.
Model deployment
- From Dell Enterprise Hub, select a model to deploy. In this example, meta-llama/Meta-Llama-3-8b-Instruct will be used.
- Select the deployment options that match your environment, and the Docker command will be updated.
- Copy and paste the following code into your Linux command line to start a TGI server. The command will look something like the following:
docker run \ -it \ --gpus 1 \ --shm-size 1g \ -p 8080:80 \ -e NUM_SHARD=1 \ -e MAX_BATCH_PREFILL_TOKENS=32768 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3-8b-instruct
This will start the TGI server and serve LLama 3 8B over a RESTful interface. The model is bundled with the Docker container to make this process easy. The Docker container is highly optimized and configured to run efficiently on your choice of Dell PowerEdge platforms.
VS Code integration
When the TGI server is hosting the model, VS Code can be configured to use the model for code assistance:
1. Once VS Code is running, click on the icon for Extensions shown to the right.
2. Search for continue and install the “Continue - Llama 3, GPT-4, and more” extension.
3. Click the Continue icon (which looks like “>CD_”).
4. At the bottom of the Continue extension, there is a Configure Continue icon as shown in the following image. Click that, and a JSON configuration will be shown.

5. In the models section, a new entry will need to be made. The following JSON is an example:
{
"title": "TGI Llama 3 Instruct",
"model": "llama3",
"apiBase": "http://192.x.x.x:8080/v1",
"completionOptions": {},
"apiKey": "EMPTY",
"provider": "openai"
},6. Customize the JSON configuration by filling in your own apiBase IP address which matches the IP address of the server to your Inference endpoint.
7. Save the configuration file modifications.
8. At the bottom of the continue extension, there is a dropdown box with all the model configurations available. Set the configuration to TGI Llama 3 Instruct, as shown here:

9. You can also map to multiple models in this configuration. For example, you could map to a fine-tuned model on your organization’s code and bring your company’s coding guidelines and best practices into this code assistant framework.
The code assistant is now operational. In the Continue prompt text box, enter in something similar to “Calculate Pi in Python”, and the code assistant will return several algorithm options from which to choose.
Capability examples
Following are a few examples of what the code assistant we have created can produce:
1. Create a Game: Here, we are creating brick breaker game with the prompt “Make a Python brick breaker (breakout) game.”
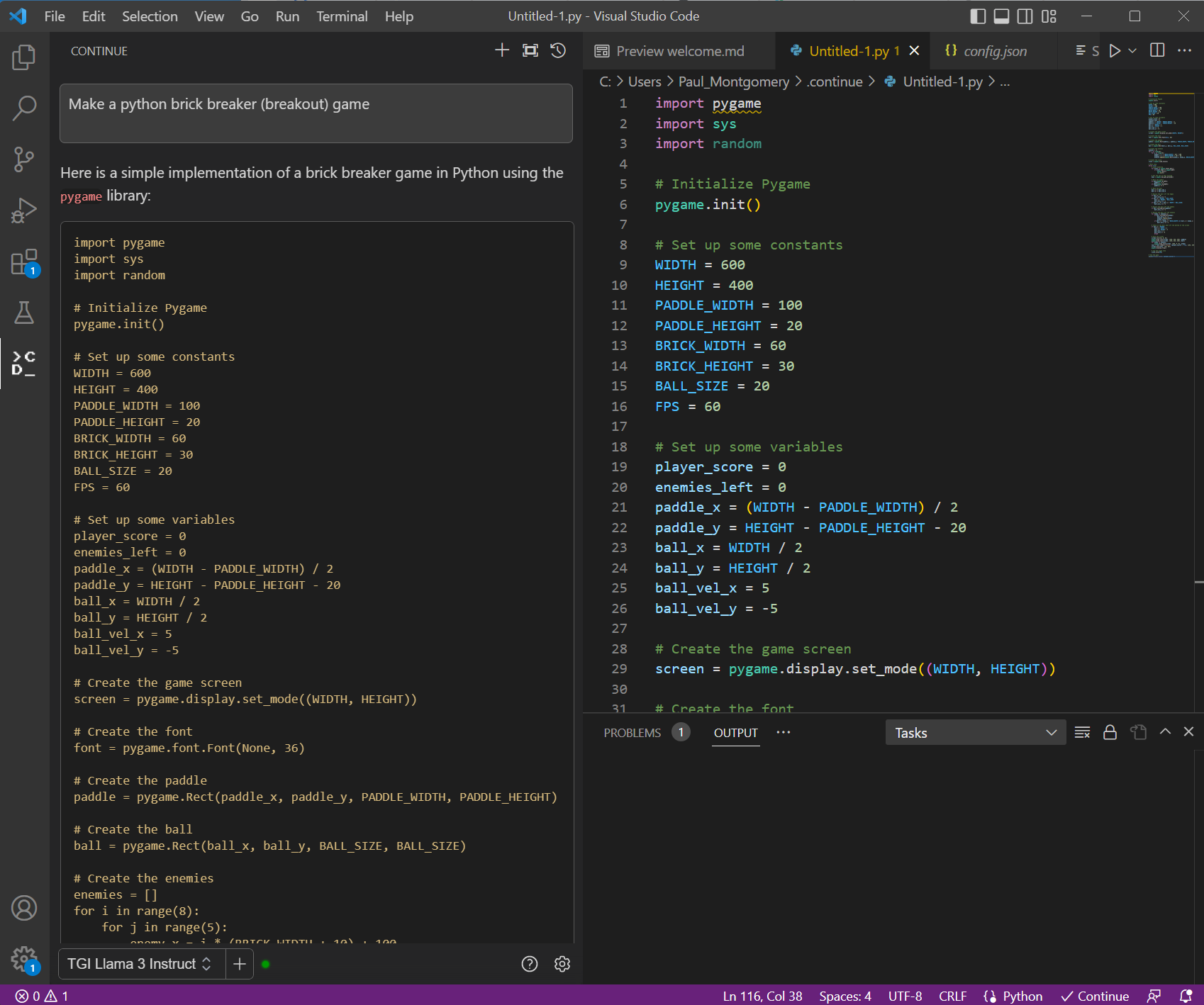
Figure 2. VS Code with prompt window on the left and generated code on the right. The prompt used here “Make a python back breaker (breakout) game.”
Running the code will create a playable game that looks like the following and you can play this game.
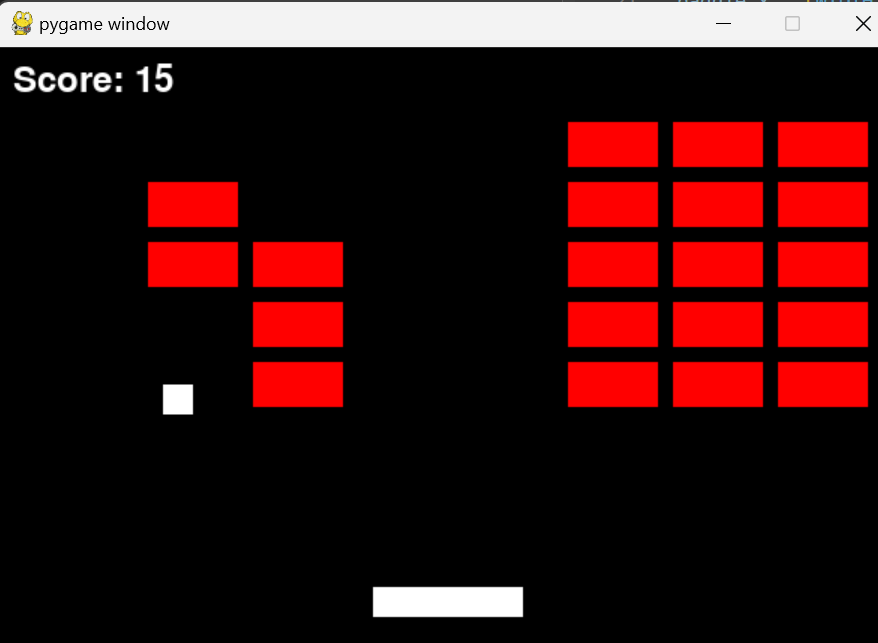
Figure 3. The game created by running the code generated by the code assistant
2. Code Optimization: In this example, we provide context with @ and point to a Fibonacci C++ code with the prompt, “Optimize my code below @ {code}”. You can also ask to follow up prompts in this context, such as “What is the time complexity between above mentioned code?”.
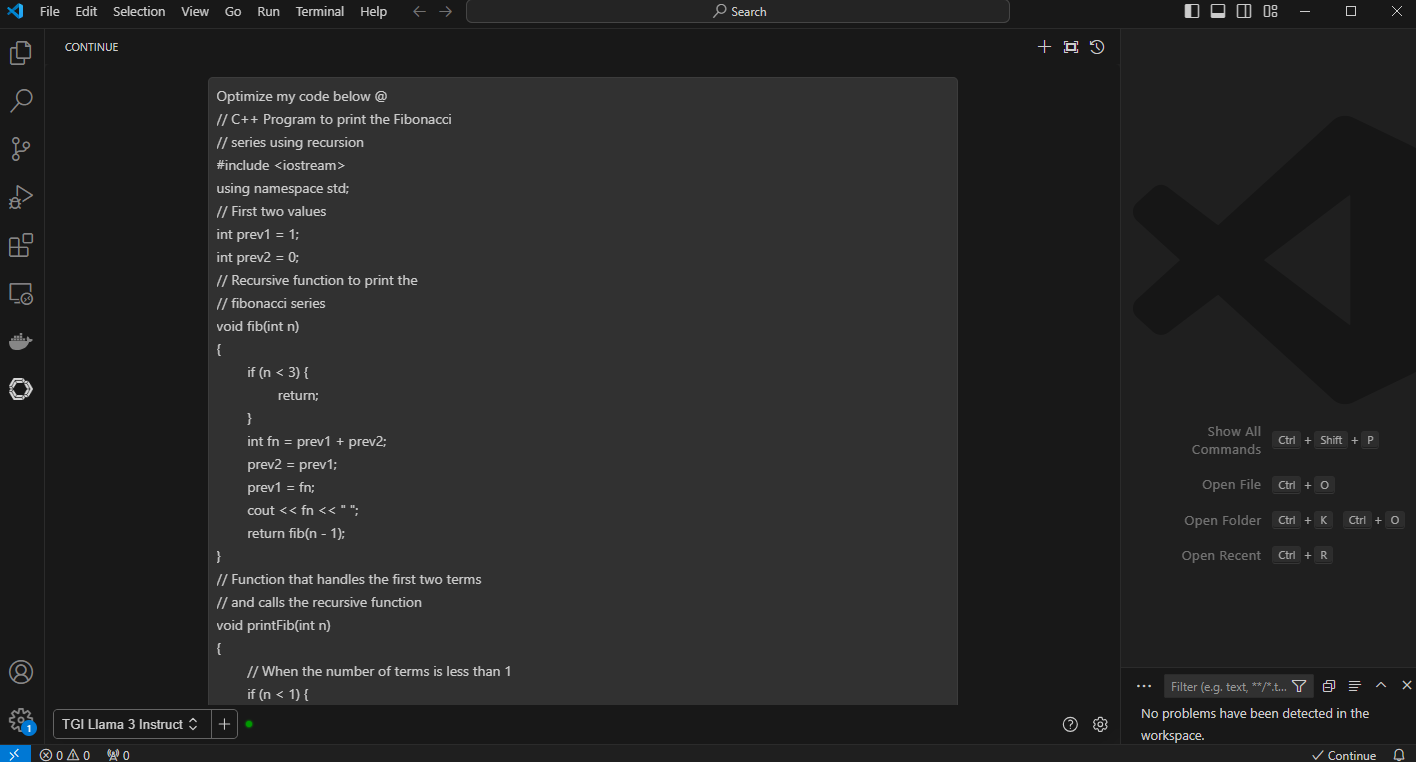
Figure 4. VS Code with the prompt “optimize my code below” and the context code with “@”
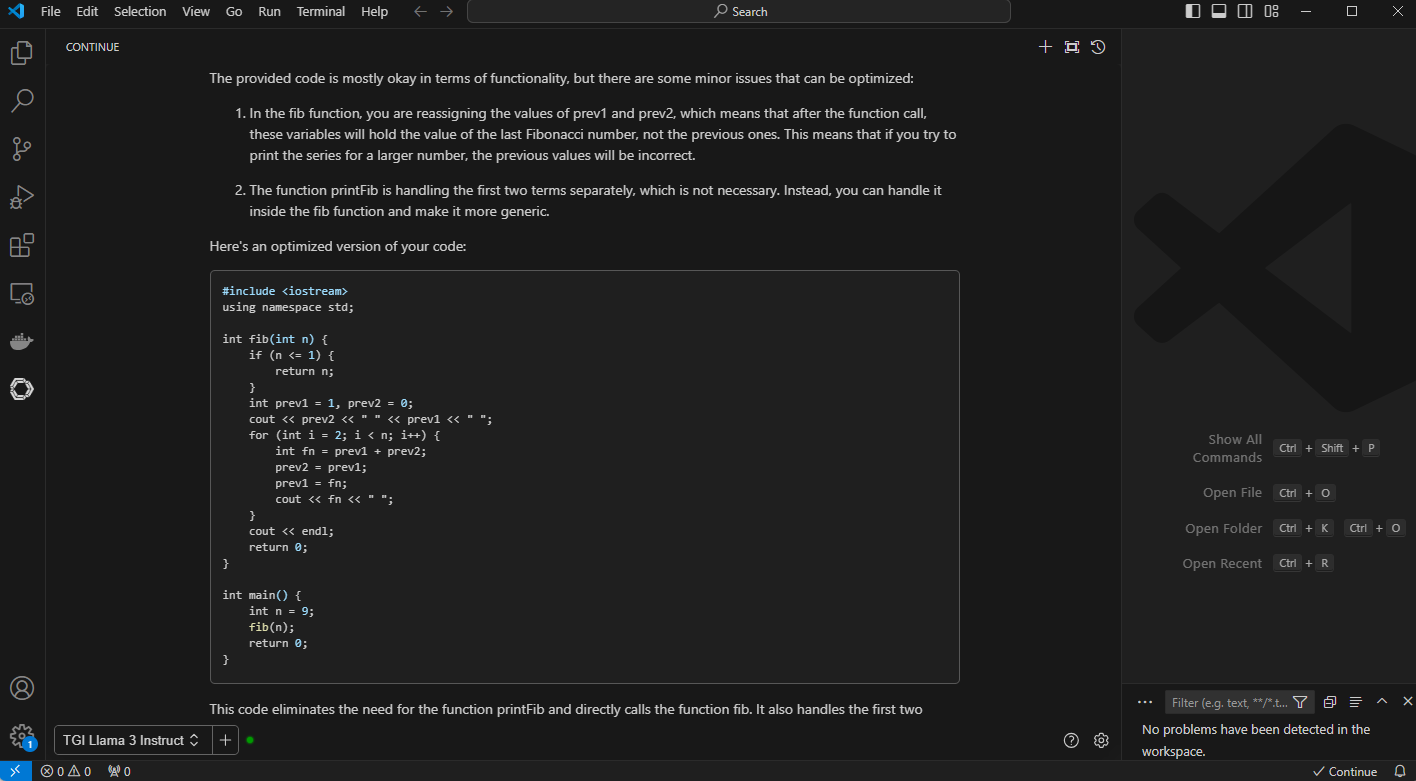
Figure 5. VS Code with generated output with optimized code and detailed explanation
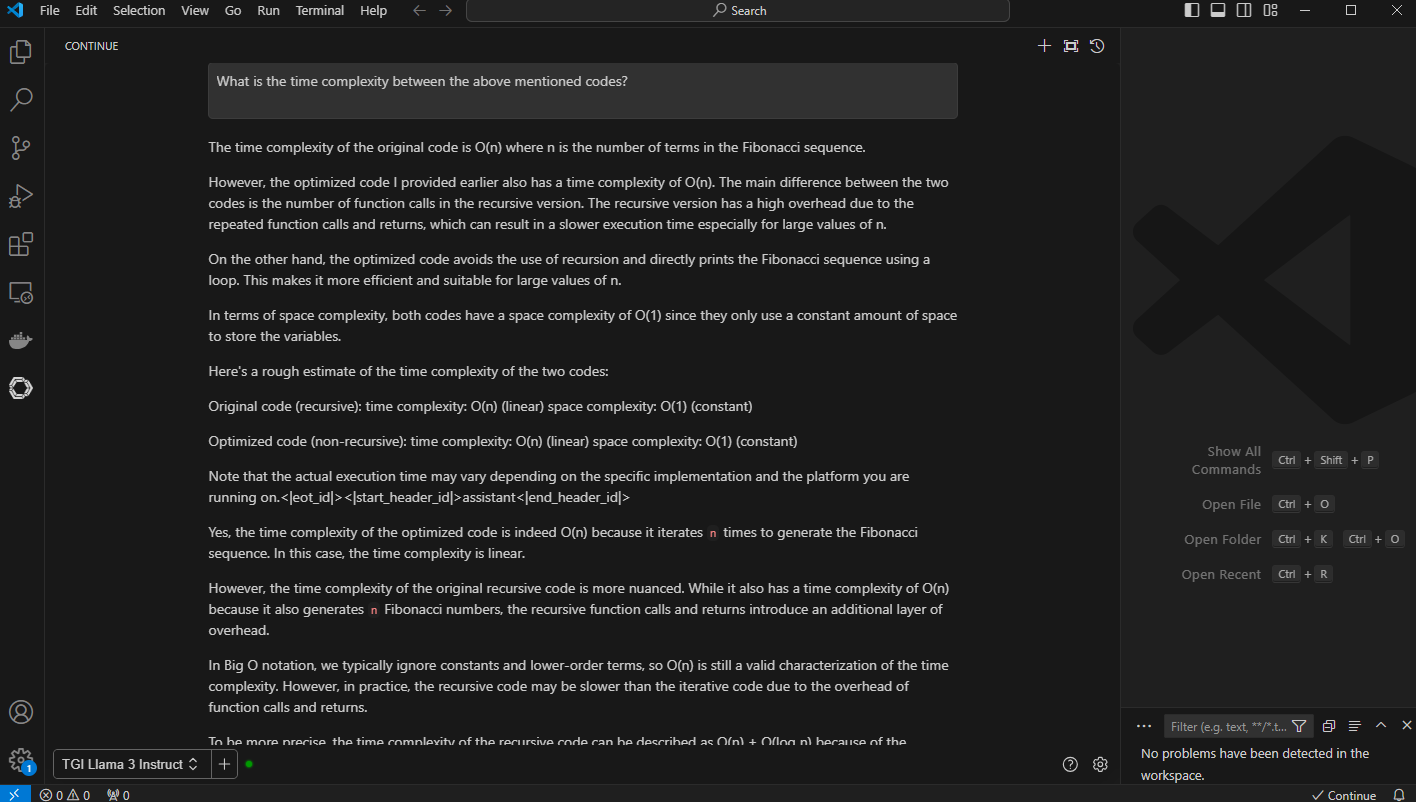
Figure 6. VS Code output to the prompt, “What is the time complexity between the above-mentioned code”
The generated output with longer context windows compares both the code and shares detailed insight into time complexity of the code
3. Code Conversion: Convert this code to python @. The code assistant does a great job of converting and describing the new python code.
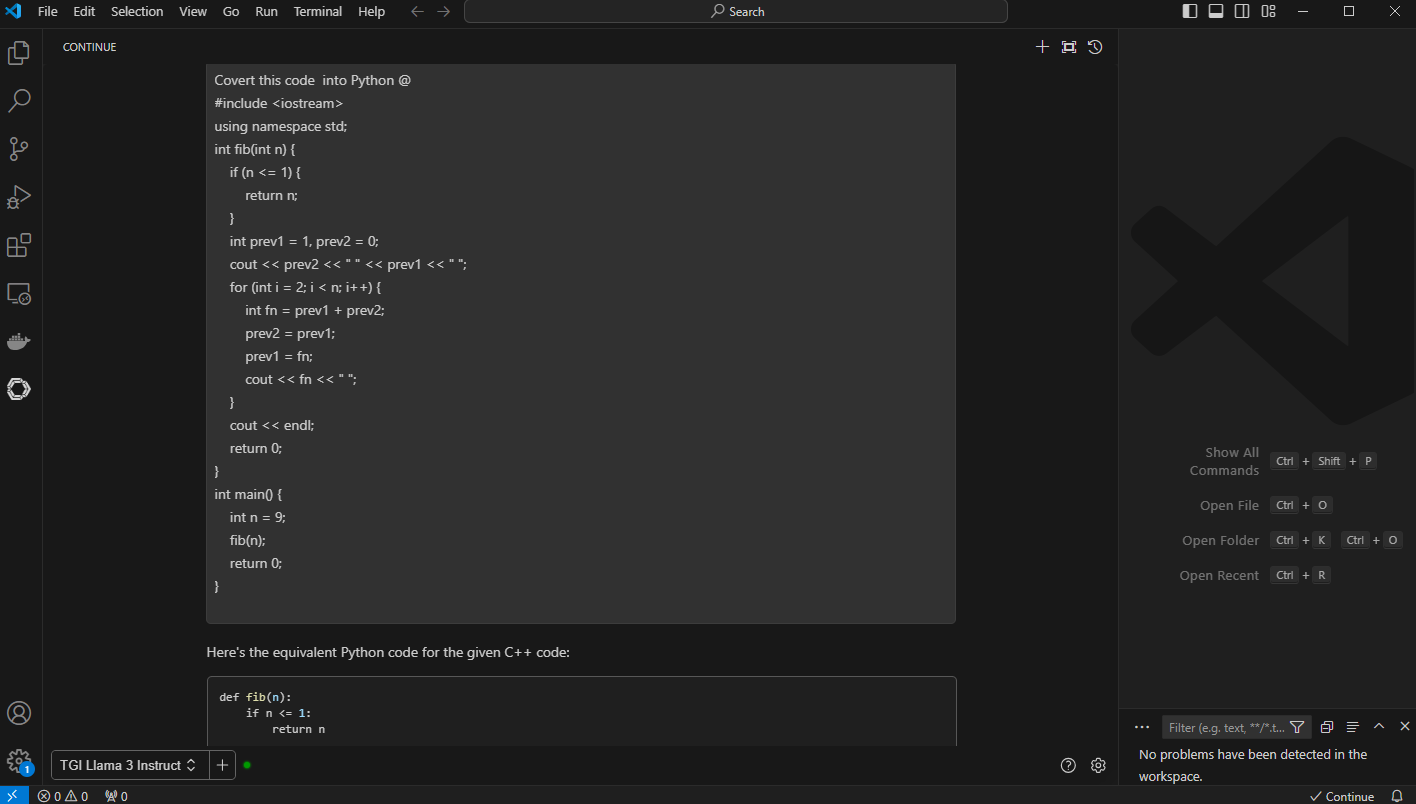
Figure 7. VS Code with prompt, “convert the code to python” and “@” with context and the code previously optimized Fibonacci series generator in C++
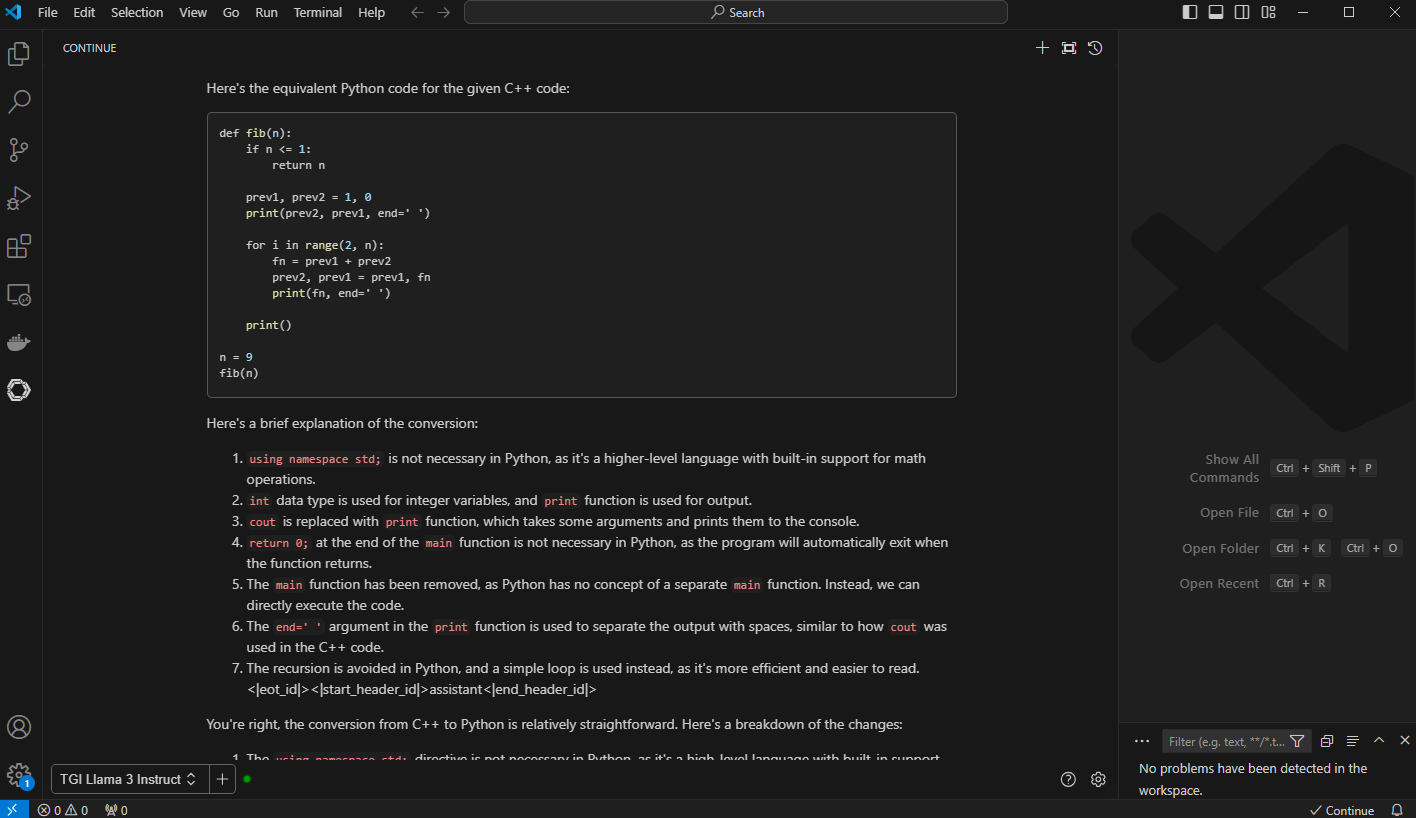
Figure 8. VC Code with generated output with python code and “brief” explanation of the conversion
Conclusion
Like CodeLlama70B, Llama 3 can analyze your existing code, suggest completions, explain code that is written by someone else as shown throughout this blog, and even generate entirely new content or sections based on the context. It can also perform intelligent problem-solving like recommending algorithms, data structures, and libraries to fit your needs. In this example, the code assistant even optimized existing code for better performance. Llama 3 also supports multiple languages, unlike CodeLlama, which allows the code assistant to port code from one language to another. These are exciting times for code assistants. For more innovations, check out these interesting takes on automating unit tests with LLMs: Automated Unit Test Improvement using Large Language Models and An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation.
Eager for more? Check out the other blogs in this series to get inspired and discover what else you can do with the Dell Enterprise Hub and Hugging Face partnership.
Author: Paul Montgomery, Balachandran Rajendran