



Choosing a PowerEdge Server and NVIDIA GPUs for AI Inference at the Edge

Dell Technologies submitted several benchmark results for the latest MLCommonsTM Inference v3.0 benchmark suite. An objective was to provide information to help customers choose a favorable server and GPU combination for their workload. This blog reviews the Edge benchmark results and provides information about how to determine the best server and GPU configuration for different types of ML applications.
Results overview
For computer vision workloads, which are widely used in security systems, industrial applications, and even in self-driven cars, ResNet and RetinaNet results were submitted. ResNet is an image classification task and RetinaNet is an object detection task. The following figures show that for intensive processing, the NVIDIA A30 GPU, which is a double-wide card, provides the best performance with almost two times more images per second than the NVIDIA L4 GPU. However, the NVIDIA L4 GPU is a single-wide card that requires only 43 percent of the energy consumption of the NVIDIA A30 GPU, considering nominal Thermal Design Power (TDP) of each GPU. This low-energy consumption provides a great advantage for applications that need lower power consumption or in environments that are more challenging to cool. The NVIDIA L4 GPU is the replacement for the best-selling NVIDIA T4 GPU, and provides twice the performance with the same form factor. Therefore, we see that this card is the best option for most Edge AI workloads.
Conversely, the NVIDIA A2 GPU exhibits the most economical price (compared to the NVIDIA A30 GPU's price), power consumption (TDP), and performance levels among all available options in the market. Therefore, if the application is compatible with this GPU, it has the potential to deliver the lowest total cost of ownership (TCO).
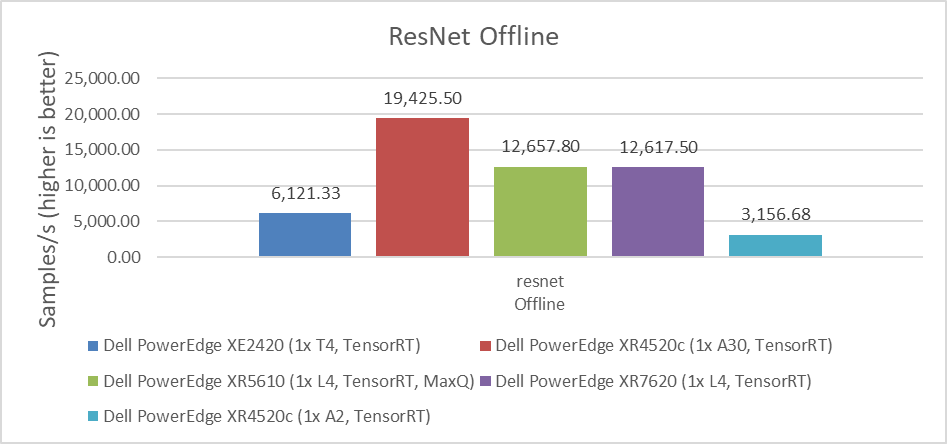
Figure 1: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the ResNet Offline benchmark
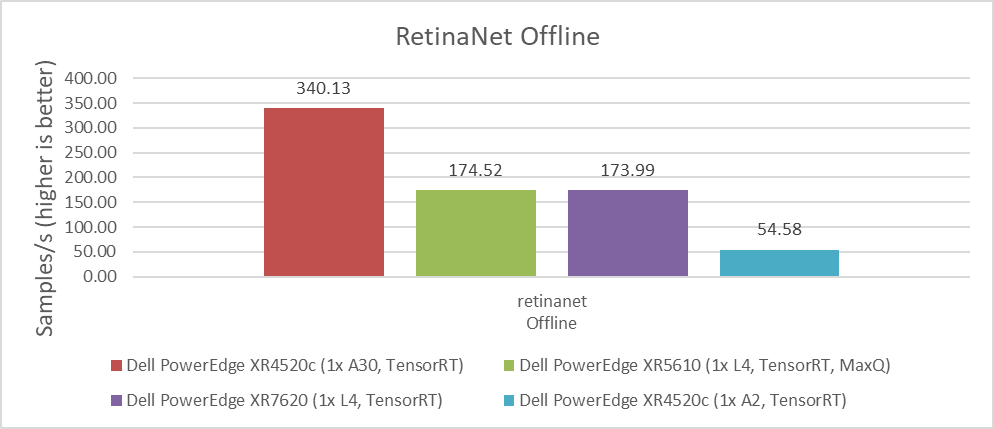
Figure 2: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the RetinaNet Offline benchmark
The 3D-UNet benchmark is the other computer vision image-related benchmark. It uses medical images for volumetric segmentation. We saw the same results for default accuracy and high accuracy. Moreover, the NVIDIA A30 GPU delivered significantly better performance over the NVIDIA L4 GPU. However, the same comparison between energy consumption, space, and cooling capacity discussed previously applies when considering which GPU to use for each application and use case.
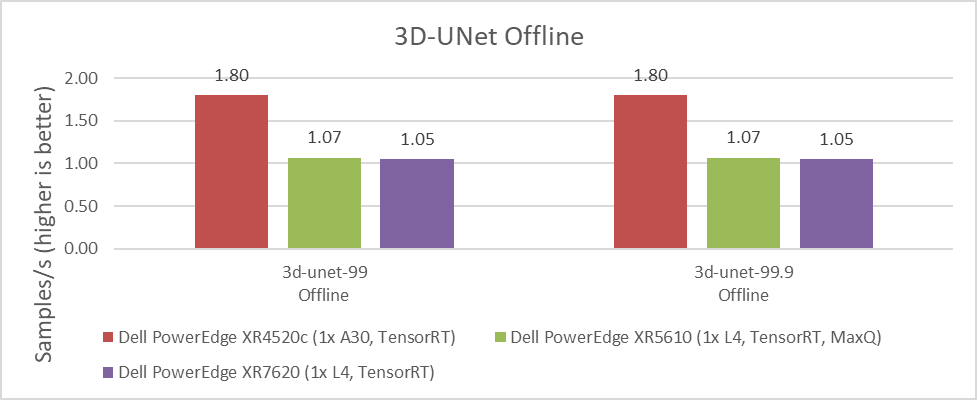
Figure 3: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the 3D-UNet Offline benchmark
Another important benchmark is for BERT, which is a Natural Language Processing model that performs tasks such as question answering and text summarization. We observed similar performance differences between the NVIDIA A30, L4, T4, and A2 GPUs. The higher the value, the better.
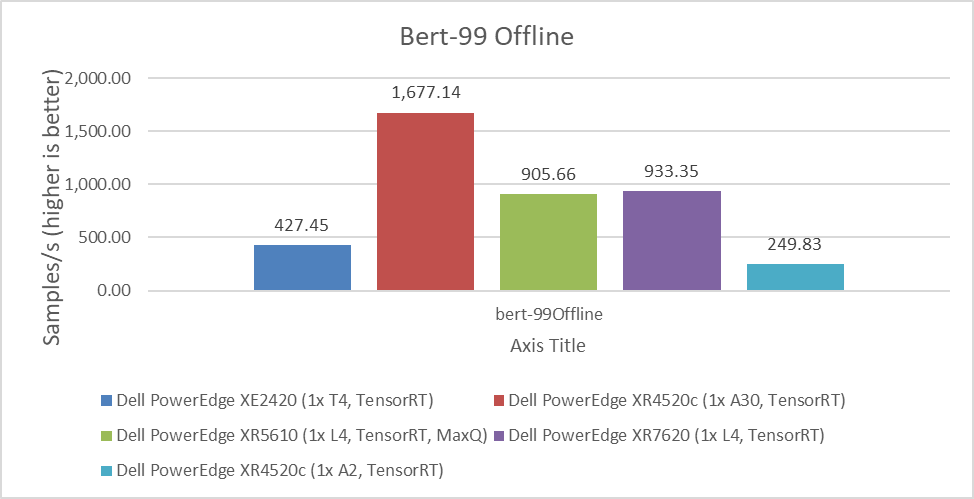
Figure 4: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the BERT Offline benchmark
MLPerf benchmarks also include latency results, which are the time that systems take to process requests. For some use cases, this processing time can be more critical than the number of requests that can be processed per second. For example, if it takes several seconds to respond to a conversational algorithm or an object detection query that needs a real-time response, this time can be particularly impactful on the experience of the user or application.
As shown in the following figures, the NVIDIA A30 and NVIDIA L4 GPUs have similar latency results. Depending on the workload, the results can vary due to which GPU provides the lowest latency. For customers planning to replace the NVIDIA T4 GPU or seeking a better response time for their applications, the NVIDIA L4 GPU is an excellent option. The NVIDIA A2 GPU can also be used for applications that require low latency because it performed better than the NVIDIA T4 GPU in single stream workloads. The lower the value, the better.
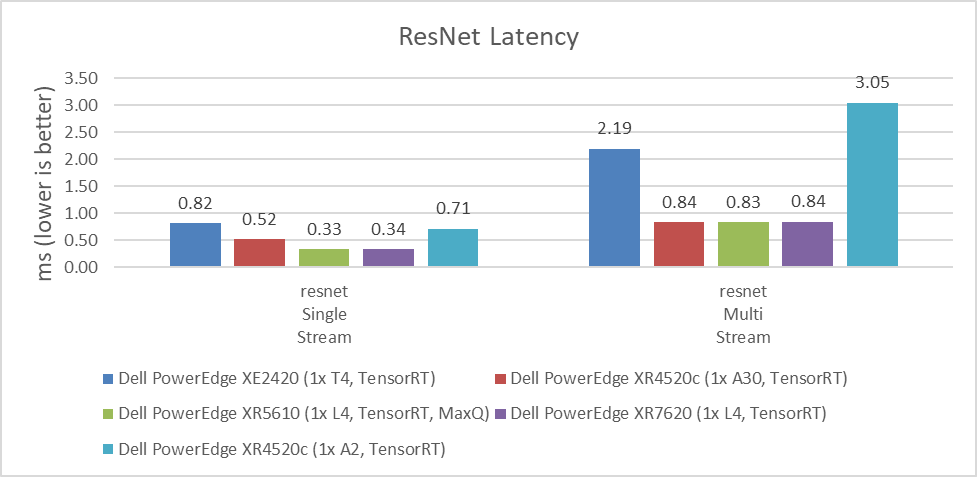
Figure 4: Latency comparison of NVIDIA A30, L4, T4, and A2 GPUs for the ResNet single-stream and multistream benchmark
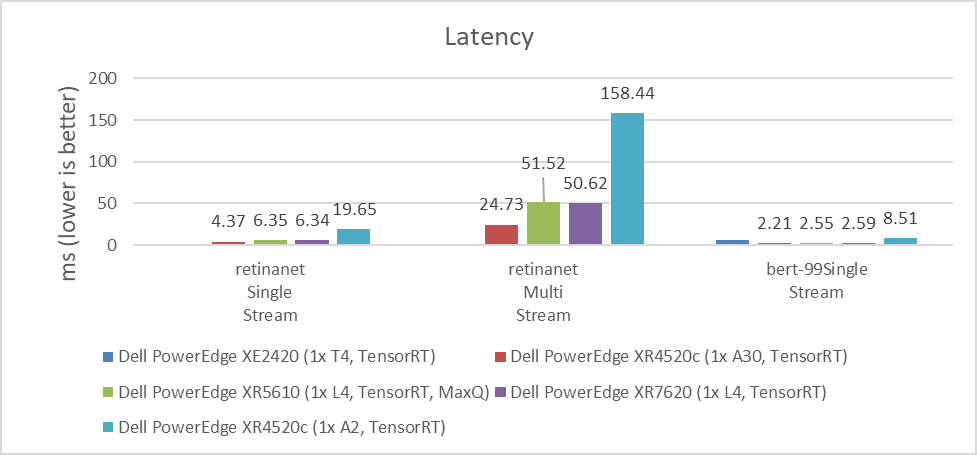
Figure 5: Latency comparison of NVIDIA A30, L4, T4, and A2 GPUs for the RetinaNet single-stream and multistream benchmark and the BERT single-stream benchmark
Dell Technologies submitted to various benchmarks to help understand which configuration is the most environmentally friendly as the data center’s carbon footprint is a concern today. This concern is relevant because some edge locations have power and cooling limitations. Therefore, it is important to understand performance compared to power consumption.
The following figure affirms that the NVIDIA L4 GPU has equal or better performance per watt compared to the NVIDIA A2 GPU, even with higher power consumption. For Throughput and Perf/watt values, higher is better; for Power(watt) values, lower is better.
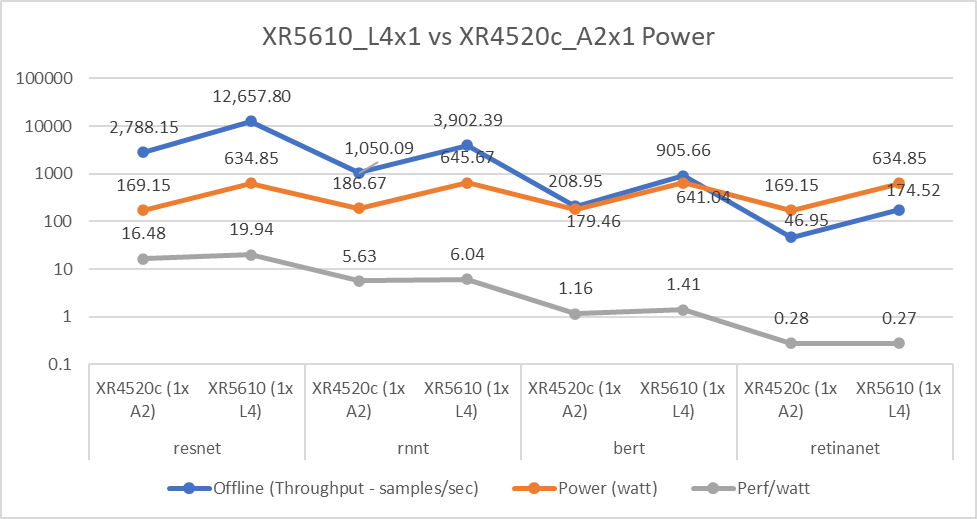
Figure 6: NVIDIA L4 and A2 GPU power consumption comparison
Conclusion
With measured workload benchmarks on MLPerf Inference 3.0, we can conclude that all NVIDIA GPUs tested for Edge workloads have characteristics that address several use cases. Customers must evaluate size, performance, latency, power consumption, and price. When choosing which GPU to use and depending on the requirements of the application, one of the evaluated GPUs will provide a better result for the final use case.
Another important conclusion is that the NVIDIA L4 GPU can be considered as an exceptional upgrade for customers and applications running on NVIDIA T4 GPUs. The migration to this new GPU can help consolidate the amount of equipment, reduce the power consumption, and reduce the TCO; one NVIDIA L4 GPU can provide twice the performance of the NVIDIA T4 GPU for some workloads.
Dell Technologies demonstrates on this benchmark the broad Dell portfolio that provides the infrastructure for any type of customer requirement.
The following blogs provide analyses of other MLPerfTM benchmark results:
- Dell Servers Excel in MLPerf™ Inference 3.0 Performance
- Dell Technologies’ NVIDIA H100 SXM GPU submission to MLPerf™ Inference 3.0
- Empowering Enterprises with Generative AI: How Does MLPerf™ Help Support
- Comparison of Top Accelerators from Dell Technologies’ MLPerf™
References
For more information about Dell Power Edge servers, go to the following links:
- Dell’s PowerEdge XR7620 for Telecom/Edge Compute
- Dell’s PowerEdge XR5610 for Telecom/Edge Compute
- PowerEdge XR4520c Compute Sled specification sheet
- PowerEdge XE2420 Spec Sheet
For more information about NVIDIA GPUs, go to the following links:
MLCommonsTM Inference v3.0 results presented in this document are based on following system IDs:
| ID | Submitter | Availability | System |
|---|---|---|---|
2.1-0005 | Dell Technologies | Available | Dell PowerEdge XE2420 (1x T4, TensorRT) |
2.1-0017 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A2, TensorRT) |
2.1-0018 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A30, TensorRT) |
2.1-0019 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A2, MaxQ, TensorRT) |
2.1-0125 | Dell Technologies | Preview | Dell PowerEdge XR5610 (1x L4, TensorRT, MaxQ) |
2.1-0126 | Dell Technologies | Preview | Dell PowerEdge XR7620 (1x L4, TensorRT) |
Table 1: MLPerfTM system IDs