




Challenges of Large-batch Training of Deep Learning Models
Fri, 12 Jun 2020 12:22:20 -0000
|Read Time: 0 minutes
Originally published on Aug 27, 2018 1:29:28 PM
The process of training a deep neural network is akin to finding the minimum of a function in a very high-dimensional space. Deep neural networks are usually trained using stochastic gradient descent (or one of its variants). A small batch (usually 16-512), randomly sampled from the training set, is used to approximate the gradients of the loss function (the optimization objective) with respect to the weights. The computed gradient is essentially an average of the gradients for each data-point in the batch. The natural way to parallelize the training across multiple nodes/workers is to increase the batch size and have each node compute the gradients on a different chunk of the batch. Distributed deep learning differs from traditional HPC workloads where scaling out only affects how the computation is distributed but not the outcome.
Challenges of large-batch training
It has been consistently observed that the use of large batches leads to poor generalization performance, meaning that models trained with large batches perform poorly on test data. One of the primary reason for this is that large batches tend to converge to sharp minima of the training function, which tend to generalize less well. Small batches tend to favor flat minima that result in better generalization. The stochasticity afforded by small batches encourages the weights to escape the basins of attraction of sharp minima. Also, models trained with small batches are shown to converge farther away from the starting point. Large batches tend to be attracted to the minimum closest to the starting point and lack the exploratory properties of small batches.
The number of gradient updates per pass of the data is reduced when using large batches. This is sometimes compensated by scaling the learning rate with the batch size. But simply using a higher learning rate can destabilize the training. Another approach is to just train the model longer, but this can lead to overfitting. Thus, there’s much more to distributed training than just scaling out to multiple nodes.
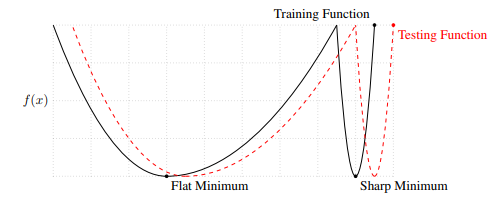 An illustration showing how sharp minima lead to poor generalization. The sharp minimum of the training function corresponds to a maximum of the testing function which hurts the model's performance on test data
An illustration showing how sharp minima lead to poor generalization. The sharp minimum of the training function corresponds to a maximum of the testing function which hurts the model's performance on test data
How can we make large batches work?
There has been a lot of interesting research recently in making large-batch training more feasible. The training time for ImageNet has now been reduced from weeks to minutes by using batches as large as 32K without sacrificing accuracy. The following methods are known to alleviate some of the problems described above:
- Scaling the learning rate
The learning rate is multiplied by k, when the batch size is multiplied by k. However, this rule does not hold in the first few epochs of the training since the weights are changing rapidly. This can be alleviated by using a warm-up phase. The idea is to start with a small value of the learning rate and gradually ramp up to the linearly scaled value. - Layer-wise adaptive rate scaling
A different learning rate is used for each layer. A global learning rate is chosen and it is scaled for each layer by the ratio of the Euclidean norm of the weights to Euclidean norm of the gradients for that layer. - Using regular SGD with momentum rather than Adam
Adam is known to make convergence faster and more stable. It is usually the default optimizer choice when training deep models. However, Adam seems to settle to less optimal minima, especially when using large batches. Using regular SGD with momentum, although more noisy than Adam, has shown improved generalization. - Topologies also make a difference
In a previous blog post, my colleague Luke showed how using VGG16 instead of DenseNet121 considerably sped up the training for a model that identified thoracic pathologies from chest x-rays while improving area under ROC in multiple categories. Shallow models are usually easier to train, especially when using large batches.
Conclusion
Large-batch distributed training can significantly reduce training time but it comes with its own challenges. Improving generalization when using large batches is an active area of research, and as new methods are developed, the time to train a model will keep going down.