




AMD Instinct MI300X Accelerators on PowerEdge XE9680 serving Cohere’s Command R+ model using vLLM


Overview
Cohere’s Command R+ model is an open weights research release of a 104B model with highly advanced capabilities including retrieval augmented generation (RAG) and tool use to automate sophisticated tasks. The tool use in this model generation enables multi-step tool use, which allows the model to combine multiple tools over multiple steps to accomplish difficult tasks. Command R+ is a multilingual model evaluated in ten languages for performance, including English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Arabic, and Simplified Chinese. Command R+ is optimized for a variety of use cases, including reasoning, summarization, and question answering. It also has a remarkably high context window of 128K, suitable for RAG applications.
The Dell PowerEdge XE9680 with AMD Instinct MI300X accelerators offers high-performance capabilities designed for enterprises utilizing generative AI. The Dell PowerEdge XE9680 with AMD features eight MI300X accelerators, a combined 1.5 TB of HBM3 memory, and 42 petaFLOPS of peak theoretical FP8 with sparsity precision performance to ensure enterprises have an optimized combination of compute and memory for their AI workloads.

In this blog, we will demonstrate how we ran Cohere’s Command R+ model on the Dell PowerEdge XE9680 with AMD MI300X. We also used AMD’s quark framework to quantize the model and will compare its performance with the original model.
Software stack
- OS: Ubuntu 22.04.5 LTS
- Kernel version: 5.15.0-122-generic
- Docker version: Docker Version 24.0.7
Hardware stack
- AMD ROCm version: 6.2
- Server: Dell PowerEdge XE9680 Server
- GPU: 8x AMD Instinct MI300X Accelerators
Deploying Cohere’s Command R+ (104B) model using vLLM
Server setup:
- Install Ubuntu 22.04.05
- Install ROCm 6.2 following the ROCm installation for Linux
- Install Docker
Once the server is set up, download command-r-plus from Hugging Face. Note that this is a gated model, and the user must agree to the usage terms before downloading.
Next, download the AMD optimized vLLM container:
docker pull powderluv/vllm_dev_channel:latest
Finally, launch the vLLM container:
docker run -it --rm --ipc=host --network=host --privileged --cap-add=CAP_SYS_ADMIN \ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --group-add video \ --device=/dev/kfd --device=/dev/dri -v <path-to-model>:/app/model \ powderluv/vllm_dev_channel:latest
See the AMD documentation of running ROCm Docker containers for details of passing AMD GPUs to docker containers.
Once the container was running, we applied the following optimized settings in the container:
export DISABLE_ADDMM_HIP_LT=0 export VLLM_WORKER_MULTIPROC_METHOD=spawn export HIP_FORCE_DEV_KERNARG=1 export VLLM_USE_ROCM_CUSTOM_PAGED_ATTN=1 export VLLM_USE_TRITON_FLASH_ATTN=0 export VLLM_INSTALL_PUNICA_KERNELS=1 export TOKENIZERS_PARALLELISM=false export RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES=1 export TORCH_NCCL_HIGH_PRIORITY=1 export GPU_MAX_HW_QUEUES=2 export NCCL_MIN_NCHANNELS=112
At this point, you can do offline benchmarking using the scripts included in the vLLM benchmarking tool as shown here:
cd /app/vllm/benchmarks/ python3 benchmark_throughput.py -tp 4 --input-len 480 --output-len 100 --model \ CohereForAI/c4ai-command-r-plus --num-prompts 512 --gpu-memory-utilization 0.9 \ --max-num-batched-tokens 65536 --num-scheduler-steps 10
Following is the start truncated output:
<..> Processed prompts: 100%|█████████████████████████████████████████████████████████████████| 128/128 [00:16<00:00, 7.86it/s, est. speed input: 3774.58 toks/s, output: 786.37 toks/s] INFO 10-04 17:44:20 multiproc_worker_utils.py:137] Terminating local vLLM worker processes (VllmWorkerProcess pid=1809) INFO 10-04 17:44:20 multiproc_worker_utils.py:244] Worker exiting (VllmWorkerProcess pid=1807) INFO 10-04 17:44:20 multiproc_worker_utils.py:244] Worker exiting (VllmWorkerProcess pid=1808) INFO 10-04 17:44:20 multiproc_worker_utils.py:244] Worker exiting Throughput: 7.83 requests/s, 4542.98 tokens/s
Note: The tokens/s rate shown is the total token rate of both input and output tokens.
Alternately, our preferred way to test is to do online benchmarking where the model is served via a chat or text completion endpoint over HTTP using an inferencing API because it more typically represents how the models are used in production, like how a model would run in a different container or even system from the application—such as a RAG (Retrieval Augmented Generation) application—that is using the model.
To test using an online benchmarking method, we used a python script that uses aiohttp and asyncio to submit prompts to the chat or text completion endpoint to generate load at a specified input/output token size and concurrent number of prompts. Alternate options could be to use tools like ab (Apache HTTP server benchmarking tool) to generate load and measure performance.
Since vLLM supports the ability to run an inferencing API server, we ran “vllm serve” from inside the container:
vllm serve CohereForAI/c4ai-command-r-plus -tp 4 --port 8088 --dtype auto --max-model-len 4096 \ --gpu-memory-utilization 0.90 --max-num-batched-tokens 65536 \ --distributed-executor-backend mp --num-scheduler-steps 10 --max-num-seq 512
Note: vLLM supports a variety of engine arguments (Arguments) that control behaviors and affect the performance of the inferencing server, however that is beyond the scope of this blog.
In this case, we used four of the GPUs of the Dell PowerEdge XE9680 to run the model (i.e. Tensor Parallelism=4) and expose the text-completion endpoint on port 8088. Due to the MI300x’s large memory capacity, it would be possible to run the model on just two GPUs, however concurrent requests would end up being limited due to the limited remaining memory for KV-cache. The large HBM memory provides an advantage for the MI300X for LLMs that have a large input context capability, like the Command R+ 128k context length.
While results will vary depending on a variety of factors including input size, output size, and concurrency, following is a graph showing how the total token rate scales with the number of prompts for a single input token size of 512 tokens and an output token size of 256 tokens.
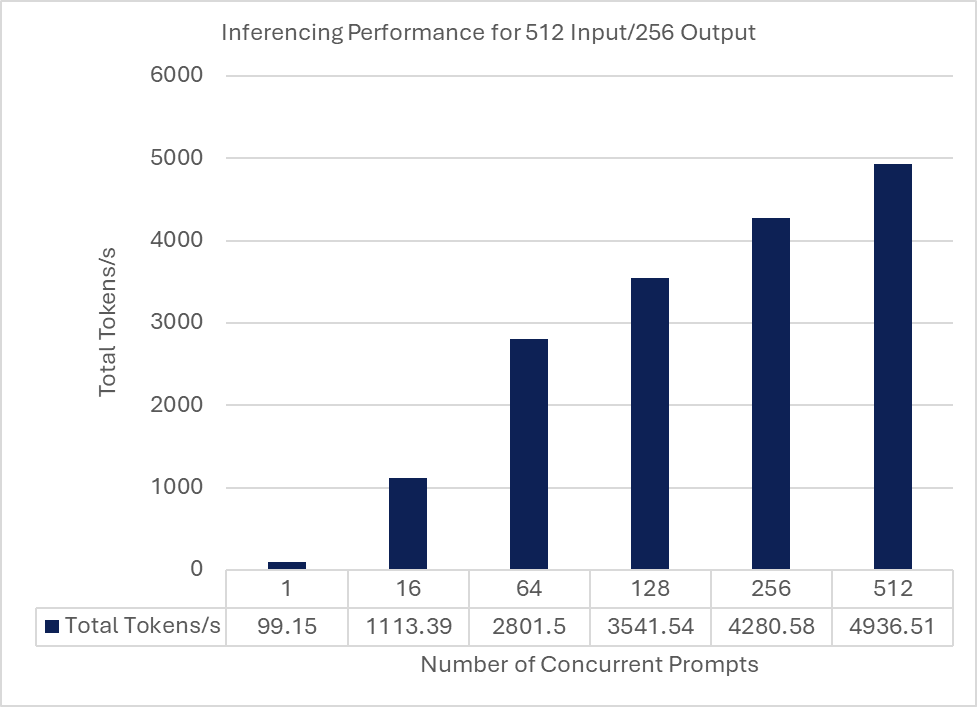
Quantizing and deploying the quantized Command R+
Quantizing a model has two main advantages – a reduction in the model memory requirements and a potential performance increase in terms of token rates if the GPU has hardware support for the quantized data type. Quantization may lead to a reduction in GPU requirements with respect to GPU memory or number of GPUs for an inferencing solution with similar performance but can result in a loss of accuracy, which may be acceptable in certain use cases.
We quantized the model and compared the performance with the original FP16 model. We used AMD’s quark to quantize the Command R+ model:
1. Launch rocm/pytorch:rocm6.2_ubuntu22.04_py3.10_pytorch_release_2.3.0 container as a base:
docker run -it --rm --ipc=host --network=host --privileged --cap-add=CAP_SYS_ADMIN \ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --group-add video \ --device=/dev/kfd --device=/dev/dri -v /<path-to-model>:/app/model \ rocm/pytorch:rocm6.2_ubuntu22.04_py3.10_pytorch_release_2.3.0
2. Follow the instructions at Language Model Quantization Using Quark.
3. Install the prerequisites:
pip install onnx pip install onnxruntime pip install onnxruntime-extensions
4. Download quark as a zip–quark.zip–and unzip it:
cd quark-0.5.0+fae64a406/examples/torch/language_modeling/ python3 quantize_quark.py --model_dir <path-to-model> \ --output_dir <path to new quantized model> --quant_scheme w_fp8_a_fp8 \ --num_calib_data 128 --no_weight_matrix_merge --model_export quark_safetensors \ --multi_gpu
This produces an FP8 version of the Cohere Command R+ model at the specified output-dir.
5. Run the same container as prior mapping in the quantized version of the model:
docker run -it --rm --ipc=host --network=host --privileged --cap-add=CAP_SYS_ADMIN \ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --group-add video \ --device=/dev/kfd --device=/dev/dri -v <path-to-quantized-model>:/app/model \ powderluv/vllm_dev_channel:latest
6. This time, run vLLM specifying the quantized version and re-run the benchmark script:
vllm serve /app/model/quantized/json_safetensors/ -tp 4 --port 8088 --dtype auto \ --max-model-len 4096 --gpu-memory-utilization 0.80 --max-num-batched-tokens 65536 \ --distributed-executor-backend mp --num-scheduler-steps 10 --max-num-seq 512
Following is a graph comparing the FP16 and FP8 models at the same 512 Input/256 Output tokens at various prompt concurrencies:
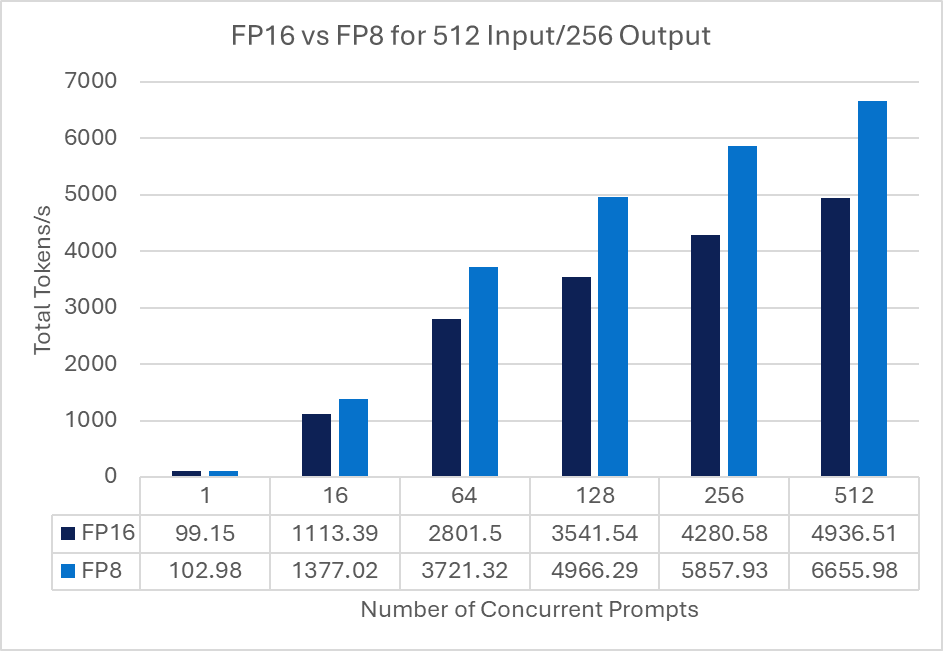
Note: Reduction in accuracy of the model was not investigated.
Reducing tensor parallelism and deploying multiple quantized Command R+ models
Since we quantized the model which reduces its memory requirements, we briefly looked at the performance of running two copies (replicas) of the quantized models with less tensor parallelism—in this case TP=2—for each model. This equates to using four of the eight MI300x GPUs.
For the benchmarking script to use both replicas, a load balancer (e.g., nginx, haproxy, traefik or similar) is used to load balance the prompt requests from the benchmark script and the multiple vLLM serving replicas deployed on the server in two containers.
Each container was assigned two of the GPUs using the method described in AMD's documentation of running ROCm Docker containers. Each container was deployed as specified previously, however the port number was changed and tensor parallelism was set to two instead of four.
We then used haproxy to load balance requests across the two vLLM instances from the benchmark client.
The following chart compares of the same 512 Input/ 256 Output tokens at various prompt concurrencies for both a single quantized model running with TP4 and two replicas, each running with TP2.
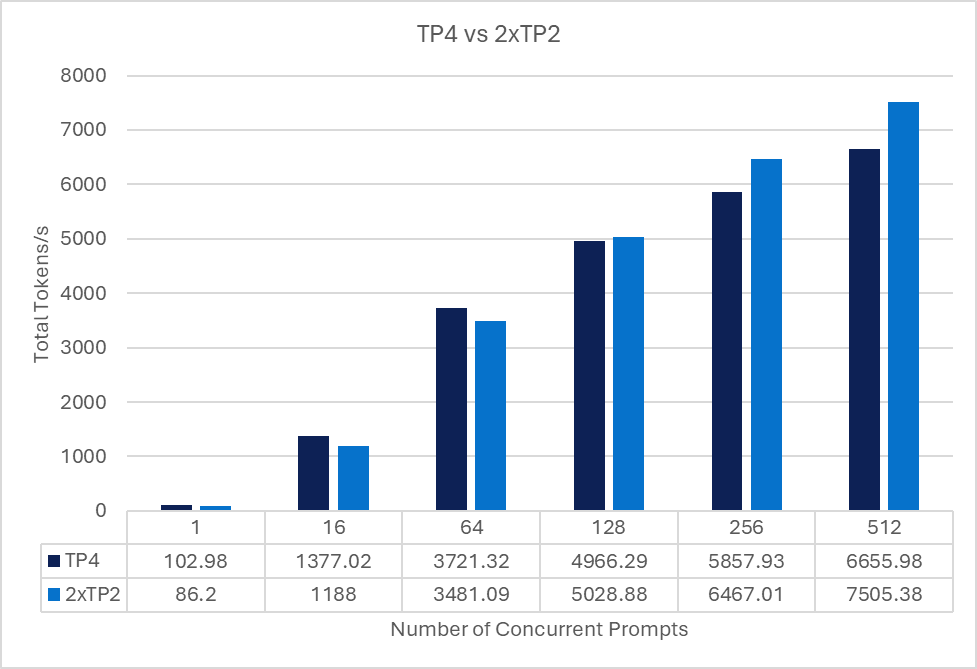
Conclusion
As detailed in this blog, you can quickly get Cohere’s Command R+ model up and running on the Dell PowerEdge XE9680 with AMD MI300X to provide optimized LLM processing based on your use case’s token and user requirements. As a leader in AI ecosystem enablement, Dell Technologies will continue to provide customers with the information, infrastructure, and AI solutions necessary to enable the right AI for you.
Authors: Kevin Marks, Balachandran Rajendran