




Accelerating Insights with Distributed Deep Learning
Fri, 12 Jun 2020 12:22:20 -0000
|Read Time: 0 minutes
Originally published on Aug 6, 2018 1:17:46 PM
Artificial intelligence (AI) is transforming the way businesses compete in today’s marketplace. Whether it’s improving business intelligence, streamlining supply chain or operational efficiencies, or creating new products, services, or capabilities for customers, AI should be a strategic component of any company’s digital transformation.
Deep neural networks have demonstrated astonishing abilities to identify objects, detect fraudulent behaviors, predict trends, recommend products, enable enhanced customer support through chatbots, convert voice to text and translate one language to another, and produce a whole host of other benefits for companies and researchers. They can categorize and summarize images, text, and audio recordings with human-level capability, but to do so they first need to be trained.
Deep learning, the process of training a neural network, can sometimes take days, weeks, or months, and effort and expertise is required to produce a neural network of sufficient quality to trust your business or research decisions on its recommendations. Most successful production systems go through many iterations of training, tuning and testing during development. Distributed deep learning can speed up this process, reducing the total time to tune and test so that your data science team can develop the right model faster, but requires a method to allow aggregation of knowledge between systems.
There are several evolving methods for efficiently implementing distributed deep learning, and the way in which you distribute the training of neural networks depends on your technology environment. Whether your compute environment is container native, high performance computing (HPC), or Hadoop/Spark clusters for Big Data analytics, your time to insight can be accelerated by using distributed deep learning. In this article we are going to explain and compare systems that use a centralized or replicated parameter server approach, a peer-to-peer approach, and finally a hybrid of these two developed specifically for Hadoop distributed big data environments.
Distributed Deep Learning in Container Native Environments
Container native (e.g., Kubernetes, Docker Swarm, OpenShift, etc.) have become the standard for many DevOps environments, where rapid, in-production software updates are the norm and bursts of computation may be shifted to public clouds. Most deep learning frameworks support distributed deep learning for these types of environments using a parameter server-based model that allows multiple processes to look at training data simultaneously, while aggregating knowledge into a single, central model.
The process of performing parameter server-based training starts with specifying the number of workers (processes that will look at training data) and parameter servers (processes that will handle the aggregation of error reduction information, backpropagate those adjustments, and update the workers). Additional parameters servers can act as replicas for improved load balancing.
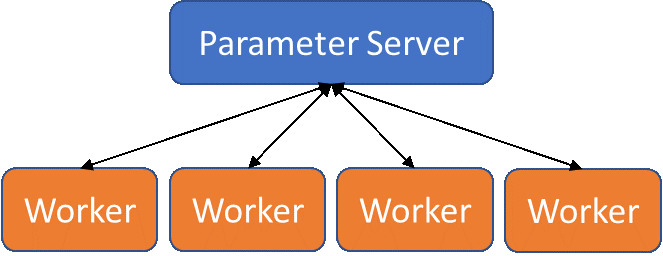 Parameter server model for distributed deep learning
Parameter server model for distributed deep learning
Worker processes are given a mini-batch of training data to test and evaluate, and upon completion of that mini-batch, report the differences (gradients) between produced and expected output back to the parameter server(s). The parameter server(s) will then handle the training of the network and transmitting copies of the updated model back to the workers to use in the next round.
This model is ideal for container native environments, where parameter server processes and worker processes can be naturally separated. Orchestration systems, such as Kubernetes, allow neural network models to be trained in container native environments using multiple hardware resources to improve training time. Additionally, many deep learning frameworks support parameter server-based distributed training, such as TensorFlow, PyTorch, Caffe2, and Cognitive Toolkit.
Distributed Deep Learning in HPC Environments
High performance computing (HPC) environments are generally built to support the execution of multi-node applications that are developed and executed using the single process, multiple data (SPMD) methodology, where data exchange is performed over high-bandwidth, low-latency networks, such as Mellanox InfiniBand and Intel OPA. These multi-node codes take advantage of these networks through the Message Passing Interface (MPI), which abstracts communications into send/receive and collective constructs.
Deep learning can be distributed with MPI using a communication pattern called Ring-AllReduce. In Ring-AllReduce each process is identical, unlike in the parameter-server model where processes are either workers or servers. The Horovod package by Uber (available for TensorFlow, Keras, and PyTorch) and the mpi_collectives contributions from Baidu (available in TensorFlow) use MPI Ring-AllReduce to exchange loss and gradient information between replicas of the neural network being trained. This peer-based approach means that all nodes in the solution are working to train the network, rather than some nodes acting solely as aggregators/distributors (as in the parameter server model). This can potentially lead to faster model convergence.
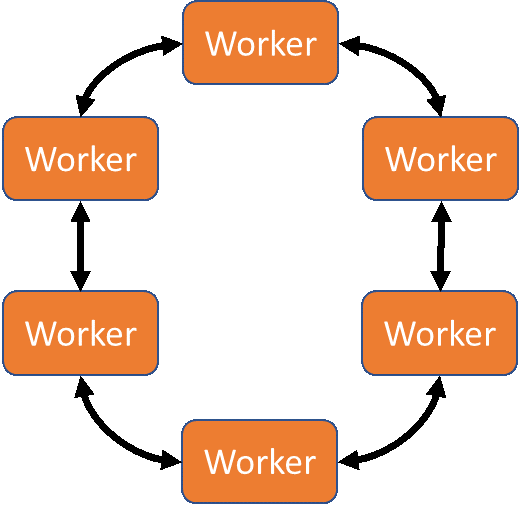 Ring-AllReduce model for distributed deep learning
Ring-AllReduce model for distributed deep learning
The Dell EMC Ready Solutions for AI, Deep Learning with NVIDIA allows users to take advantage of high-bandwidth Mellanox InfiniBand EDR networking, fast Dell EMC Isilon storage, accelerated compute with NVIDIA V100 GPUs, and optimized TensorFlow, Keras, or Pytorch with Horovod frameworks to help produce insights faster.
Distributed Deep Learning in Hadoop/Spark Environments
Hadoop and other Big Data platforms achieve extremely high performance for distributed processing but are not designed to support long running, stateful applications. Several approaches exist for executing distributed training under Apache Spark. Yahoo developed TensorFlowOnSpark, accomplishing the goal with an architecture that leveraged Spark for scheduling Tensorflow operations and RDMA for direct tensor communication between servers.
BigDL is a distributed deep learning library for Apache Spark. Unlike Yahoo’s TensorflowOnSpark, BigDL not only enables distributed training - it is designed from the ground up to work on Big Data systems. To enable efficient distributed training BigDL takes a data-parallel approach to training with synchronous mini-batch SGD (Stochastic Gradient Descent). Training data is partitioned into RDD samples and distributed to each worker. Model training is done in an iterative process that first computes gradients locally on each worker by taking advantage of locally stored partitions of the training data and model to perform in memory transformations. Then an AllReduce function schedules workers with tasks to calculate and update weights. Finally, a broadcast syncs the distributed copies of model with updated weights.
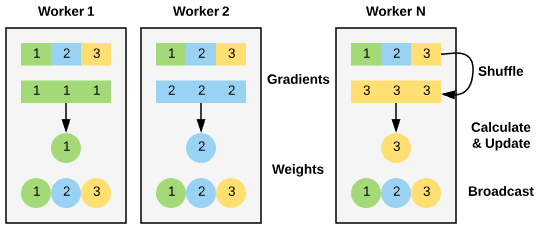 BigDL implementation of AllReduce functionality
BigDL implementation of AllReduce functionality
The Dell EMC Ready Solutions for AI, Machine Learning with Hadoop is configured to allow users to take advantage of the power of distributed deep learning with Intel BigDL and Apache Spark. It supports loading models and weights from other frameworks such as Tensorflow, Caffe and Torch to then be leveraged for training or inferencing. BigDL is a great way for users to quickly begin training neural networks using Apache Spark, widely recognized for how simple it makes data processing.
One more note on Hadoop and Spark environments: The Intel team working on BigDL has built and compiled high-level pipeline APIs, built-in deep learning models, and reference use cases into the Intel Analytics Zoo library. Analytics Zoo is based on BigDL but helps make it even easier to use through these high-level pipeline APIs designed to work with Spark Dataframes and built in models for things like object detection and image classification.
Conclusion
Regardless of whether you preferred server infrastructure is container native, HPC clusters, or Hadoop/Spark-enabled data lakes, distributed deep learning can help your data science team develop neural network models faster. Our Dell EMC Ready Solutions for Artificial Intelligence can work in any of these environments to help jumpstart your business’s AI journey. For more information on the Dell EMC Ready Solutions for Artificial Intelligence, go to dellemc.com/readyforai.
Lucas A. Wilson, Ph.D. is the Chief Data Scientist in Dell EMC's HPC & AI Innovation Lab. (Twitter: @lucasawilson)
Michael Bennett is a Senior Principal Engineer at Dell EMC working on Ready Solutions.