
Approaches
Approaches
-
Clustering algorithm
Clustering is an ML approach that identifies groups or personas based on the similarities and common attributes in the data (Figure 2). When we apply a clustering algorithm, we separate customers into different groups (clusters) based on demographic details and behaviors. Customers in a cluster are likely to prefer similar service offers. By assigning customers to unique clusters, we can derive insights from each cluster and provide appropriate recommendations to the customer based on the cluster information. For example, Customer A and Customer B have similar personas and are assigned to Cluster 1. If Customer A likes and purchases service offer X, Customer B might also like the same service offer X. Dell Technologies provides recommendations to each customer based on cluster analysis.
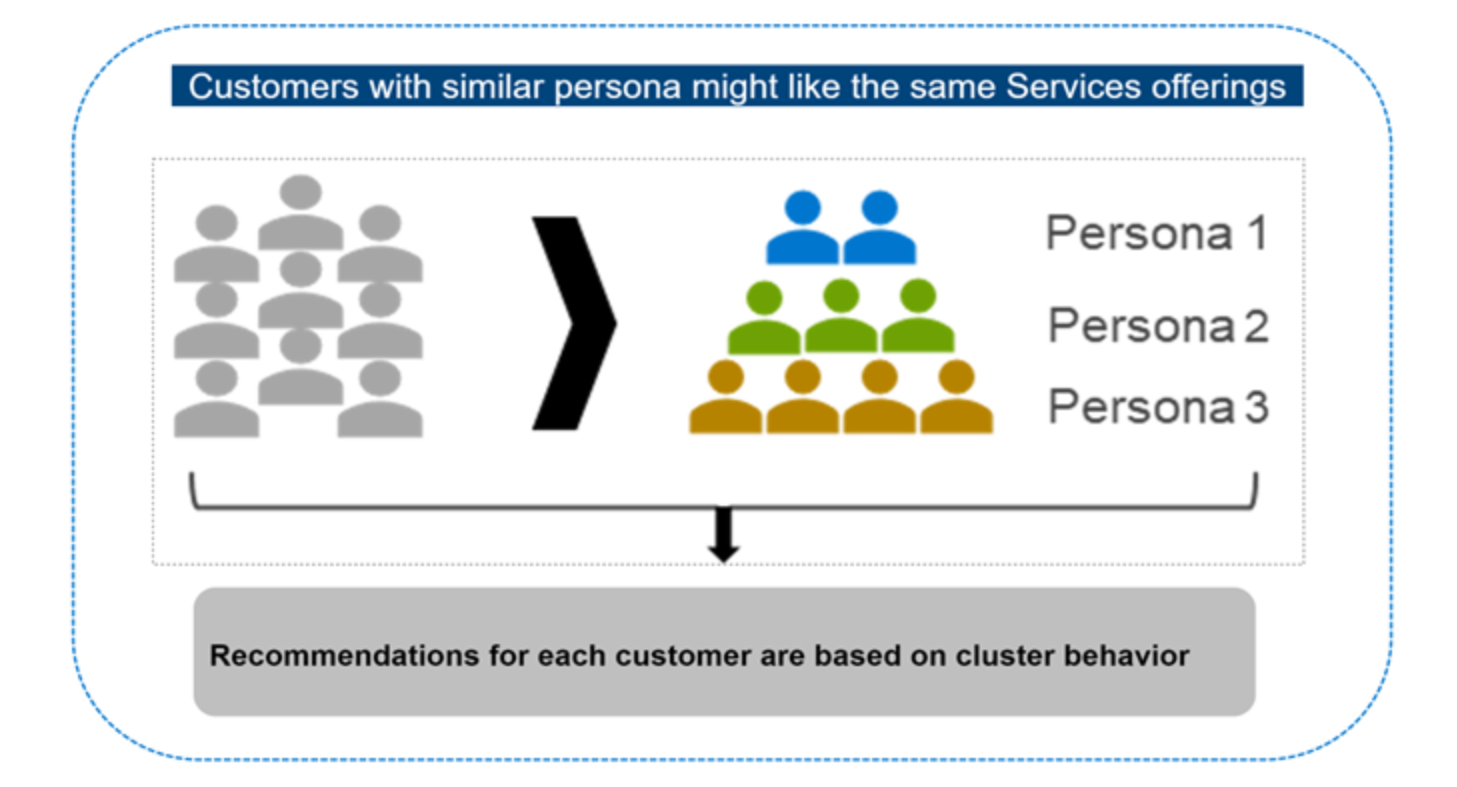
Figure 2. Clustering to find similar customers
Dell Technologies Service Product Recommender uses K-Means clustering for customer segmentation. The K-Means clustering algorithm categorizes similar customer data into K clusters.
Euclidean distance is used to calculate the similarities between data points. The algorithm first takes K initial points randomly as cluster centers. All the data points are assigned to the closest cluster centers (one among K) based on the distance computed. Next, the cluster centers are re-computed based on the average of each cluster. Data points are re-assigned based on distances, and this process is repeated until defined stopping criteria are reached. Stopping criteria are met when:
- The maximum number of iterations is reached.
- Cluster centers do not change beyond a threshold.
- Data points are no longer reassigned.
The input features of our clustering model include the following attributes:
- Customer attributes: Country, region, asset count, market segment, line of business (for example, Latitude, Precision, and so on), number of employees, customer buying power
- Product line asset attributes: for example, Latitude 3410, Precision 5520, and so on
The team evaluated multiple clustering models and selected K-Means as the best model based on performance (Figure 3).
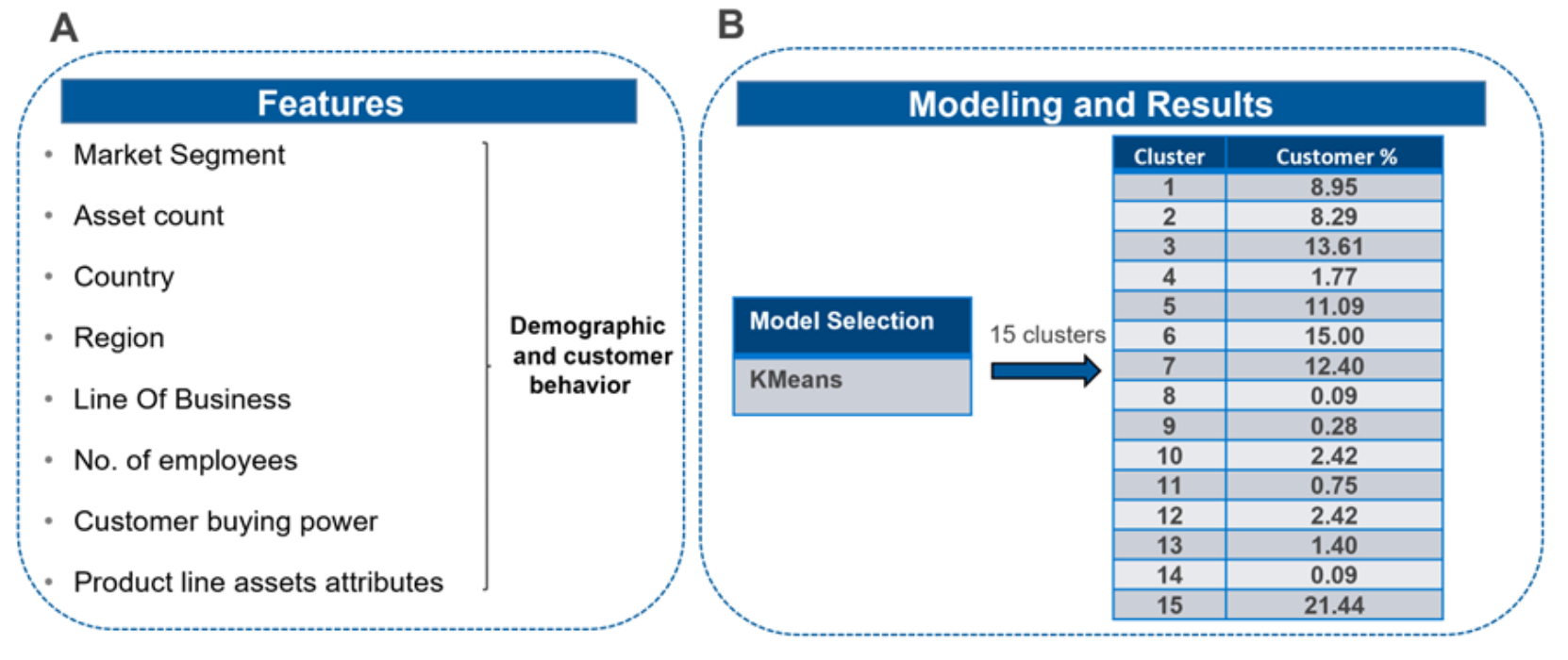
Figure 3. Input features and final cluster number