Appendix
Appendix
-
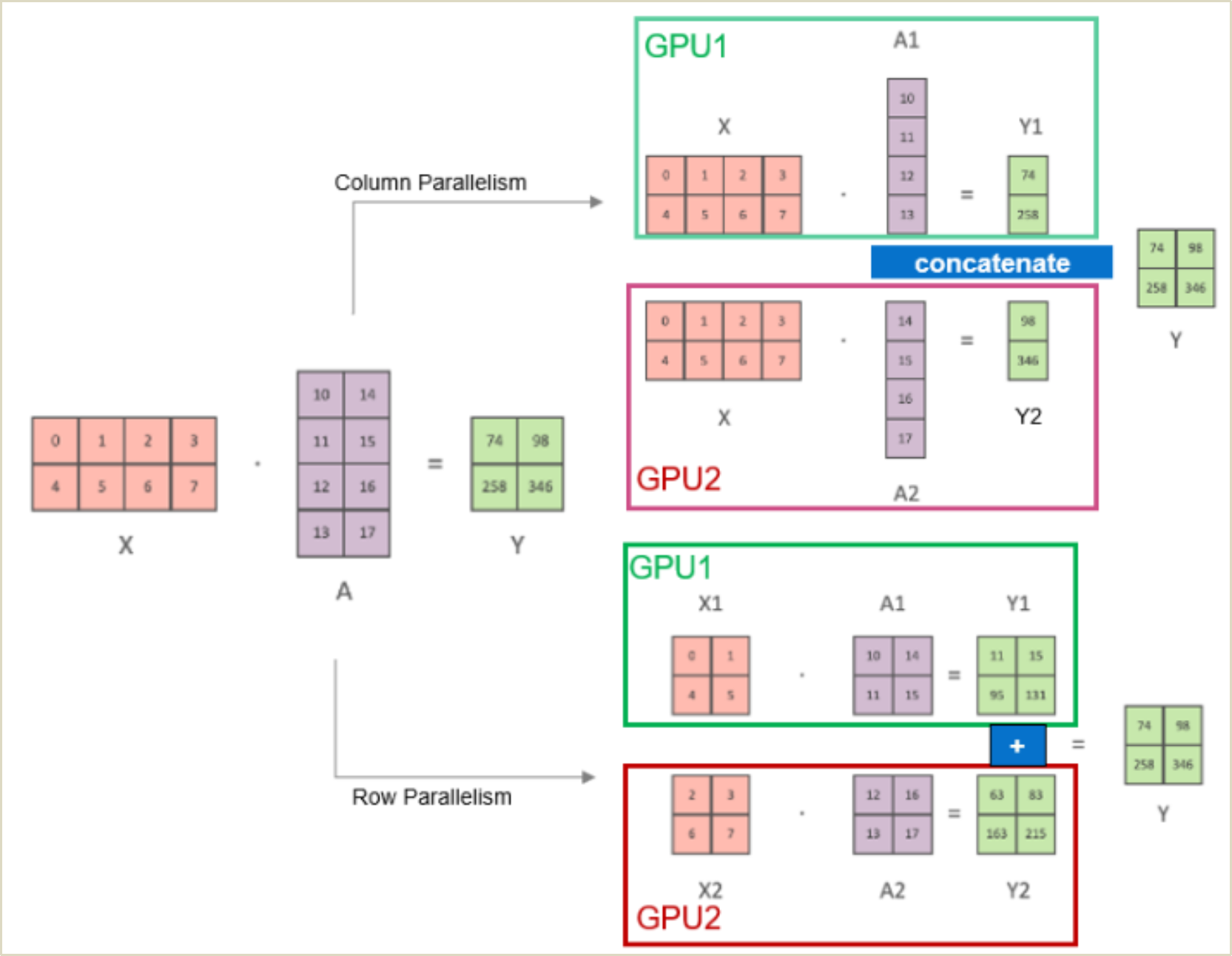
Tensor Parallelism is a parallelization technique that involves distributing tensor operations of model layers across multiple GPUs. It enables effective utilization of multiple GPUs. Each GPU processes a slice of tensor and only aggregates the full tensor for operations that require it. For example, in transformer models the main building block is a fully connected nn.Linear followed by a nonlinear activation GeLU. The dot-product part of GeLU operation can be written as Y = GeLU(XA), where X, Y and A are input, output, and weight matrices. This matrix operation can be split between multiple GPUs, as shown in Figure 17. However, note that tensor operations are not limited to multiplications and can be executed for tensors with dimensions higher than 2.