
Microbenchmarking
Microbenchmarking
-
Numerous microbenchmark tools are available from the ROCm, AMD, and other repositories on GitHub. We highlight a few tools that demonstrate the performance of MI300X accelerators and increased speeds from MI210 accelerators to MI300X accelerators.
Memory bandwidth
BabelStream is a synthetic GPU benchmark measuring memory transfer rates to and from global device memory. Formerly known as GPU-STREAM, it is based on the STREAM benchmark for CPUs that the High-Performance Computing Group at the University of Bristol maintains. See https://github.com/UoB-HPC/BabelStream or the official repository.
Running BabelStream
The following commands perform the compiling steps:
git clone https://github.com/UoB-HPC/BabelStream.git
cd BabelStream
CXX=hipcc cmake -Bbuild -H. -DMODEL=hip -DHIP_ROOT_DIR=/opt/rocm-6.1.0 -DUSE_CUDA=OFF -DUSE_ROCM=ON -DHIP_PATH=/opt/rocm-6.1.0
cmake --build buildThe following command runs the benchmark:
./build/hip-stream
Interpreting results
The HBM3 memory in the MI300X accelerator primarily drives the memory performance. Because the MI210 accelerator uses HBM2e memory, and the memory capacity of the MI300X shows an increase from the MI210 accelerator’s 64 GB to 192 GB. We observed a 2.9 to 3.4 times faster memory throughput, which aligns with the 3.3 times improvement in specifications. The increased memory capacity and throughput are crucial for training, inference, and fine-tuning LLMs and other generative AI models such as Stable Diffusion, as they enable handling larger parameters, datasets, and caches more efficiently.
Table 16. Comparison of BabelStream benchmarking on MI300X and MI210X accelerators
Benchmark Function
R760xa_MI210 (in TB/s)
XE9680_MI300X (in TB/s)
Speedup of MI300X over MI210
Peak bandwidth
1.6
5.3
3.31x
Copy
1.36
4.01
2.95x
Mul
1.37
3.99
2.91x
Add
1.25
4.09
3.27x
Triad
1.24
4.03
3.25x
Dot
1.27
4.32
3.40x
High Performance Linpack for Accelerator Introspection
High Performance Linpack for Accelerator Introspection (HPL-MxP) is a benchmark that highlights the convergence of HPC and AI workloads by solving a system of linear equations using novel, mixed-precision algorithms. See https://hpl-mxp.org/ for more information about HPL-MxP and https://github.com/ROCm/rocHPL-MxP for compiling instructions and requirements.
Run the following command to perform the benchmark on eight MI300X accelerators:
./mpirun_rochplmxp -P 4 -Q 2 -N 614400 --NB 2560
The following table shows the performance results that are tested under ROCm 6.1.1. The results for MI300X per card are about 2.5 times faster than for the MI210 accelerator.
Table 17. HPL-MxP performance results
Number of GPUs
R750xa_MI210 (in GFLOPs)
XE9680_MI300X (in GFLOPs)
Speedup of MI300X over MI210
1
1.33E+05
3.45E+05
2.59
2
2.78E+05
6.86E+05
2.46
4
5.68E+05
1.39E+06
2.44
8
Did not run
2.82E+06
N/A
ROCm Communicaiton Collectives Library benchmarking
ROCm Communication Collectives Library (RCCL) is a stand-alone library of standard collective communication routines for AMD GPUs. RCCL facilitates multi-GPU and multinode communication for GPUs and networking. RCCL is topology aware of not only the internal GPU connectivity, but also of the internal PCIe topology along with the network architecture. See https://github.com/ROCm/rccl-tests for the rccl-tests source code, including compiling instructions.
AMD Instinct MI300X Infinity platform architecture
The eight AMD Instinct MI300X accelerators in the PowerEdge XE9680 server are placed on a Universal baseboard (UBB 2.0). There are eight Open Compute Project (OCP) Accelerator Modules (OAMs) that are connected in a mesh topology using AMD Infinity fabric. The AMD infinity fabric provides 128 GB/s bi-directional BW connectivity between each GPU. Each MI300X accelerator connects with its peers through seven XGMI links. The following figure shows an example of an eight-way mesh topology:
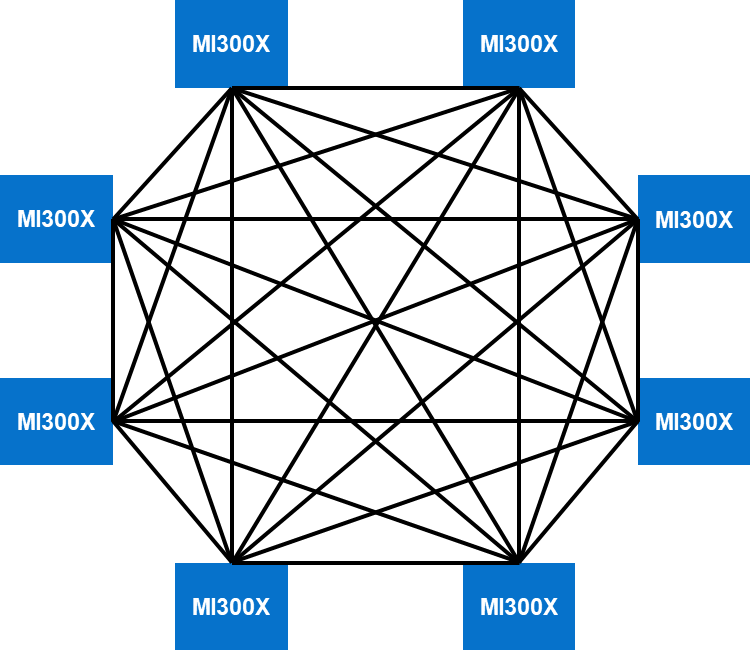
Figure 17. Eight-way mesh topology
Run the following command to run All Reduce performance benchmark on eight MI300X accelerators:
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 8
When running RCCL across all eight GPUs in a single PowerEdge XE9680 node, seven rings are formed. The RCCL test measures the throughput that can be achieved when running the selected collective communication test such as all_reduce across a single GPU. Thus, with each MI300X accelerator connected to seven peer GPUs and when running the all_reduce collective across seven rings, the achieved performance as measured comes to approximately 317 GB/s.
High Performance Linpack
High-Performance Linpack (HPL) is a benchmark that solves a uniformly random system of linear equations and reports a floating-point execution rate using a standard formula for operation count. See https://github.com/amd/InfinityHub-CI/tree/main/rochpl for the compiling instructions and run steps for rocHPL, the ROCm version HPL for AMD.
The following command is used to run HPL benchmark for 8x MI300X:
./mpirun_rochpl -P 2 -Q 4 -N 430080 --NB 512
The following table summarizes the results. These performance results are tested under ROCm 6.1.1. The MI300X accelerator is 2.88 times faster than MI210 accelerator per GPU, and 5.76x faster compared to the PowerEdge R760xa system with four previous generation MI210 GPUs. A single PowerEdge XE9680 server with eight MI300X accelerators can deliver an impressive 415 TFLOPs.
Table 18. HPL performance in TFLOPsNumber of GPUs
R760xa_MI210
XE9680_MI300X
Per GPU
MI300X over MI210 per card
4
72
18
8
430
54
2.88x
Benchmarking caveats
Benchmark results are highly dependent on workload, specific application requirements, and system design and implementation. Relative system performance varies due to these and other factors. Therefore, do not use this workload as a substitute for a specific customer application benchmark when considering critical capacity planning and product evaluation decisions.
All performance data in this report was obtained in a rigorously controlled environment. Results obtained in other operating environments might vary significantly. Dell Technologies does not warrant or represent that a user can or will achieve similar performance results.