
Inferencing performance
Inferencing performance
-
Use cases
Evaluating LLM inference performance necessitates first distilling what technical requirements are associated with the use cases being pursued. Many modern LLMs such as GPT 4, Claude 3.5, Mistral, and Llama 3 are built for next-token inference. The solutions (and their configurations) that can be built around these LLMs are impacted by the possible variability of the:
- Input Sequence Length (ISL)─The length of the text provided to the model as input.
- Output Sequence Length (OSL)─The length of the text generated by the model as output.
There are four common combinations of Input Token-Sequence Length and Output Token-Sequence Length pairings that we used to categorize many common LLM inference use cases:
- Short input, medium-length output
- Long input, medium-length output
- Medium-length input, short output
- Short input, short output
The following sections describe these use cases, categorized by these types of input/output length combinations.
Short input, medium-length output
This category generates longer content from brief inputs:
Creative writing─LLMs can generate short stories, poems, or creative narratives based on brief prompts. For example, given a prompt such as "A mysterious door in an abandoned house," the model can craft a 1000-word story exploring the concept. This application is useful for writers seeking inspiration or for generating content for creative writing workshops, allowing for creative exploration with minimal input.
Email drafting─From a short summary or bullet points, LLMs can compose professional, well-structured email messages. This application is useful for busy professionals who need to communicate complex ideas efficiently. The model can expand on key points, maintain a consistent tone, and ensure that all necessary information is in the email message, streamlining communication in corporate settings.
Code generation─LLMs can create code snippets or entire functions based on concise descriptions of functionality. For instance, "Create a Python function to sort a list of dictionaries by a specific key" can result in a fully implemented and documented function. This application can significantly accelerate development processes and assist programmers to address complex coding tasks, aiding developers in rapid prototyping.
Marketing content─Given a brief outline or key points about a product or service, LLMs can generate compelling marketing copy, including product descriptions, ad text, or social media posts. The model can adapt its writing style to suit different platforms and target audiences, ensuring consistent brand messaging across various channels and enhancing content creation workflows.
FAQ creation─From a few user questions, LLMs can develop comprehensive FAQ sections, anticipating related questions and providing detailed answers. This application is invaluable for businesses looking to improve their customer support resources or creating educational materials, improving customer support resources.
Visual storytelling─LLMs can generate detailed stories or descriptions based on a series of images, bridging the gap between visual and textual content. This application is useful in fields like digital marketing, journalism, or eCommerce, where compelling narratives need to be created around visual content, combining text and visuals to tell compelling stories.
Product recommendation─By analyzing short text descriptions and images of products, LLMs can provide personalized product recommendations, complete with reasoning and comparisons. This application enhances the shopping experience by offering tailored suggestions based on user preferences and product features, improving eCommerce experiences.
Long input, medium-length output
This category processes and summarizes large amounts of information:
Long-form article summarization─LLMs can distill extensive articles or research papers into concise, informative overviews, capturing key points and main arguments. This application is useful for researchers, students, or professionals who need to grasp the essence of lengthy documents quickly, saving time for readers.
Legal document analysis─By processing lengthy legal documents, LLMs engage in multiturn discussions with legal professionals. They use chain-of-thought reasoning to clarify complex legal concepts, extract and summarize key points, identify potential issues, and provide a high-level overview of complex legal matters. This application can reduce the time that lawyers and paralegals spend on document review and analysis, aiding legal professionals in quick decision-making.
Research paper review─LLMs can analyze comprehensive research papers, providing critiques, identifying strengths and weaknesses, and suggesting areas for further research. This application assists researchers in literature reviews and helps journal editors in the peer review process, aiding academics in their evaluations.
RAG for educational content─LLMs can use RAG to retrieve relevant information from a database of textbooks and articles. The model engages in multiturn conversations with students, answering questions based on retrieved content and providing detailed explanations.
Medical diagnosis assistance─LLMs can analyze comprehensive patient records, including text notes and medical images. The model summarizes the patient's history and engages in a multiturn conversation with healthcare providers, using RAG to retrieve relevant medical literature for informed decision-making.
Medium-length input, short output
This category addresses medium-length inputs with concise outputs:
Medium-length summarization─LLMs can summarize articles or reports into brief, informative paragraphs, distilling key information for quick consumption. This application is ideal for creating abstracts, executive summaries, or brief overviews of longer content, useful for quick information consumption.
Chatbot interactions─LLMs can engage in multiturn conversations, maintaining context and providing relevant, concise responses to user queries. This application enables more natural and effective human-computer interactions in customer support, virtual assistants, or interactive learning environments, enhancing user experience in customer support.
Contextual Q&A─Given a medium-length context, LLMs can answer specific questions accurately and concisely, making them ideal for information retrieval systems. This application is useful in educational settings, customer support, or any scenario where quick, accurate answers are needed based on a given context, facilitating knowledge retrieval in conversational settings.
Meeting notes─LLMs can process longer meeting transcripts and generate concise, actionable notes, highlighting key decisions and action items. This application saves time in postmeeting documentation and ensures that important points are not missed, improving postmeeting productivity.
Multimodal news summarization─By analyzing news articles along with accompanying images and infographics, LLMs can generate concise summaries that capture the essence of the news story. This application is valuable for news aggregators, media monitoring services, or individuals looking to stay informed about current events, providing a quick overview of current events.
Multimodal customer support─LLMs can provide personalized support by understanding and responding to customer queries that include text, images, or screenshots, offering concise solutions. This application enhances customer support efficiency by quickly addressing issues that might require visual context, improving customer satisfaction.
Multimodal event recaps─LLMs can generate brief summaries of events or conferences, combining key takeaways from presentations, speaker information, and relevant visual content. This application is useful for attendees, organizers, or people who could not attend but want a quick overview of the event, aiding event participants.
Short input, short output
This category addresses quick, concise tasks with both short inputs and outputs.
Language translation─LLMs can accurately translate short phrases or sentences between languages, maintaining context and nuance. This application is useful for quick translations in travel applications, multilingual customer support, or international business communications, enabling quick communication across language barriers.
Code refactoring─Given a short code snippet, LLMs can suggest improvements or simplifications while preserving functionality, enhancing code readability and efficiency. This application assists developers to maintain clean, optimized code bases, aiding developers in maintaining clean codebases.
Keyword extraction─LLMs can identify and summarize key terms from short documents, useful for SEO optimization, content tagging, or quick document classification. This application aids in content management and improves searchability of digital assets, useful for indexing and search optimization.
Microblogging─LLMs can generate or optimize short posts for platforms like Twitter, ensuring maximum impact within character limits. This application helps social media managers and marketers create engaging, concise content, enabling quick content creation.
Multimodal language translation─LLMs can translate text while considering accompanying images or diagrams, ensuring that the translation preserves the overall meaning and context. This application is useful for translating infographics, memes, or other visual content with text, enhancing cross-language communication.
Multimodal code generation─By analyzing both text descriptions and visual representations (such as flowcharts), LLMs can generate short, effective code snippets. This application bridges the gap between conceptual design and implementation in software development, aiding in complex development tasks.
Multimodal fraud detection─LLMs can quickly analyze transactions or documents that include text, images, and signatures, identifying potential fraud or anomalies in a concise report. This application enhances security measures in financial transactions, document verification, or identity authentication processes.
The following table shows the input/output lengths that we used for performance testing for each use case combination:
Table 9. Input/output lengths
Use case category
Input token-sequence length
Output token-sequence length
Long input, medium-length output
7000
1000
Medium-length input, short output
2000
200
Short Input, medium-length output
200
1000
Short input, short output
200
200
Note: These token-sequence lengths are chosen for benchmarking purposes. They are used to simulate use cases representative of certain realistic scenarios. They are not universally representative of all scenarios that might fall under the corresponding use cases.
Key performance metrics and factors impacting performance
To understand the performance of an LLM, you can measure several metrics, each of which is relevant for assessing different aspects of the model's performance. The following list describes how each metric contributes to understanding LLM performance:
- Time Per Output Token (TPOT)─This metric, also known as Inter-Token Latency (ITL), indicates the time taken to generate each output token for a user query. It reflects the perceived “speed” of the model. A lower TPOT means that the model can generate tokens quickly, enhancing the overall responsiveness and efficiency of the system.
- Throughput─This metric measures the throughput of the model, indicating how many tokens the model can generate per second on average. It provides insight into the overall speed of the model and its ability to process input data efficiently.
- Time To First Token (TTFT) ─This metric measures the time it takes for the model to generate the first token of a response after receiving an input prompt. It reflects the initial processing time and is crucial for real-time applications for which low latency is essential.
- Latency─This metric measures the total time required for the model to generate a complete response to a given input prompt. It includes the time for processing the entire input sequence and generating the output sequence, providing a comprehensive view of the end-to-end latency experienced by users.
The following factors impact the performance of the LLM model inference:
- Model size (number of model parameters)─This parameter is the size of a model, measured by the number of parameters, which directly influences its memory use and computational demands. Larger models with more parameters typically need more powerful hardware to perform inference efficiently.
- Input token-sequence length and output token-sequence length─These parameters influence both GPU memory use and computation time. Longer input and output token-sequences demand more memory. Processing and generating these longer token-sequences increase the computational load, resulting in longer inference times.
- Batch size─This parameter specifies the number of input sequences processed simultaneously during inference. Larger batch sizes require more memory to store each sequence and the corresponding computations. Certain LLM deployment configurations can potentially improve throughput by processing multiple input sequences in parallel, fully using the GPUs. However, while larger batch sizes improve throughput, they might also increase latency when handling many requests in a single batch. While this approach is useful for offline benchmarking purposes, for online scenarios vLLM provides strategies such as continuous batching managed by its scheduler, to handle batches of requests automatically based on the current load and the configured maximum number of batched tokens.
- Chunked prefill─This parameter, supported by vLLM, enables the prioritization of decode requests over prefill requests. When chunked prefill is enabled, the vLLM scheduler batches all pending decode requests before scheduling any prefill requests. If a prefill request cannot fit into the available token budget (max_num_batched_tokens), it is chunked into smaller parts. This feature improves inter-token latency (ITL) and generation decode performance by ensuring that decode operations are handled more efficiently, leading to better GPU use.
- Maximum number of batched tokens─This parameter (max_num_batched_tokens) in vLLM controls the maximum number of tokens that can be processed in a single batch. Setting this parameter at a higher value achieves better TTFT, while setting it lower can provide better Inter-Token Latency (ITL).
- Tensor parallel size─This parameter enables the distribution of model weights across multiple GPUs. For example, in a system such as the Dell PowerEdge XE9680 server equipped with eight AMD MI300x GPUs, setting the tensor parallel size to 8 allows each GPU to handle a portion of the model weights. This configuration reduces the memory load on each GPU and permits larger Key-Value (KV) cache sizes, potentially improving inference efficiency.
- GPU memory utilization─This parameter (gpu_memory_utilization) in vLLM represents the ratio (ranging from 0 to 1) of GPU memory allocated for model weights, activations, and KV cache. Increasing this value increases the KV cache size, improving the model’s throughput.
Offline batched inference compared to online (client) inference
When determining the optimal infrastructure configuration and sizing for a use case, consider the kind of inference architecture that an end-user will use. There are two major kinds of inference architectures - offline and online - that affect how the input data is provided to the LLM for inference, and how the inference results are returned to the user.
The following sections describe the differences in implementation between an offline batched inference scenario and an online (client) inference scenario.
Offline Batched Inference
The following figure shows a simplified design to explain the offline batched inference process:
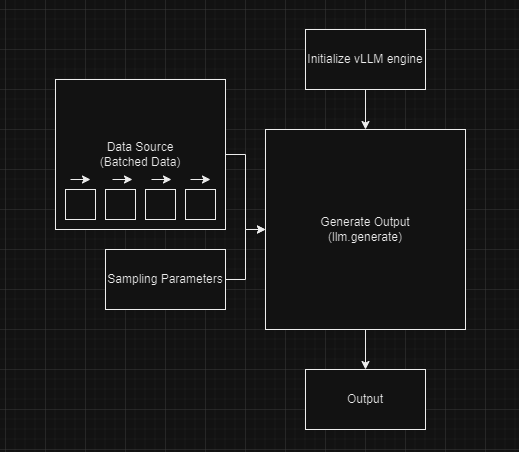
Figure 6. Simplified block diagram - offline batched inference
The components include:
- Data source─This component includes datasets with multiple prompts. They can be stored in various formats such as CSV files, databases, or arrays of tokenized input prompts, and so on. The data is processed in static batches when generating outputs from the model.
- Sampling parameters─These parameters control the behavior of the text generation process. Key parameters include:
- Temperature─This parameter controls the randomness of the model’s output. It is usually set between 0.0 and 1.0. Lower values result in less random and more deterministic outputs, while higher values lead to more creative and diverse outputs. A lower temperature sharpens the probability distribution, making the model more confident in selecting words with higher logits.
- Top-p (nucleus sampling)─This parameter controls the diversity of the generated text. The value is typically between 0.0 and 1.0. For example, a top-p value of 0.9 allows the model to consider the smallest set of tokens whose cumulative probability is at least 90 percent. Lower top-p values restrict the output to the most likely tokens, reducing randomness, while higher values allow for more diverse and potentially creative outputs.
- Initialize vLLM Engine─This step initializes the vLLM engine for offline inference using the LLM class. For example:
llm = LLM(model="/path_to_model/Meta-Llama-3-70B")
initializes the Llama 3 70 B model, which can be used to generate outputs based on the input prompts.
- Generate Output─To generate outputs using the initialized vLLM model, the llm.generate() function is called. This function adds the input prompts to the vLLM engine’s waiting queue and runs the engine to generate the outputs. The outputs are returned as a list of RequestOutput objects, which include the generated tokens.
The following table provides a comparison between offline batched inference and online (client) inference:
Table 10. Offline batched inference and online (client) inference comparison
Component
Offline batched inference
Online inference
Processing
Processes a batch of input prompts all at once. Synchronous in nature.
Processes individual requests in real-time as they arrive. Asynchronous in nature.
Scalability
Scales by handling larger batches.
Scales by managing more concurrent requests, requires load balancing.
Resource use
More efficient for large batches, better resource utilization.
Requires optimization for handling concurrent real-time requests. vLLM supports continuous batching for efficient inferencing.
Online (client) inference
The following figure shows a simplified design of online inferencing with vLLM. vLLM can be deployed as a server that implements the OpenAI API protocol.
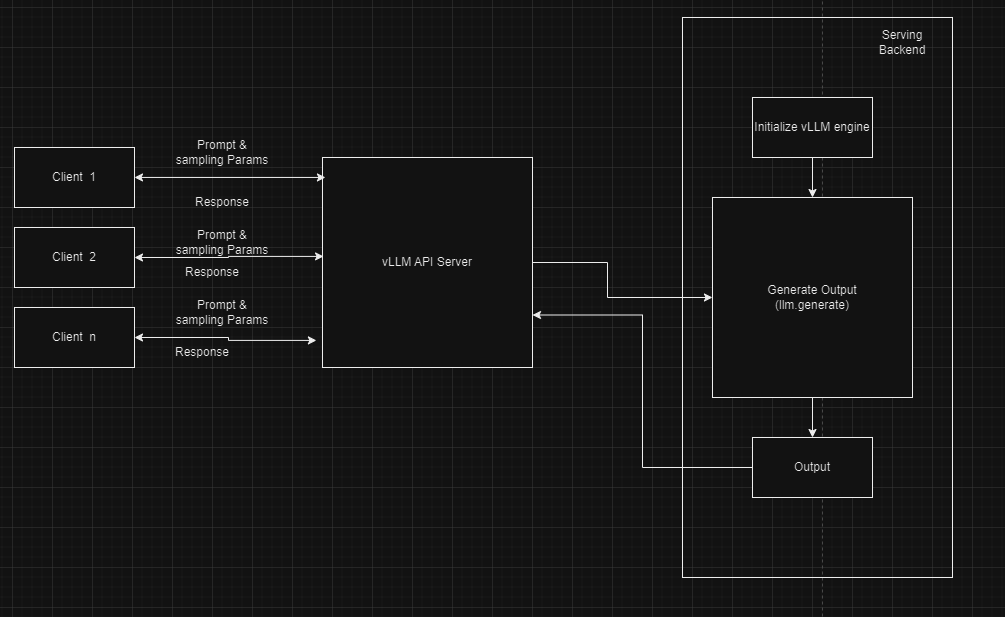
Figure 7. Simplified block diagram - Online inferencing
The components include:
Clients─Multiple clients (for example, Client 1, Client 2, Client n) send requests to the server. Each client provides input prompts and sampling parameters. Clients initiate the inference process by sending their prompts and parameters to the API server. An example is a web application that requires real-time text generation.
Prompts and sampling parameters─Clients provide these inputs. The prompts are the text inputs for which the clients seek generated responses, and the sampling parameters control the behavior of the text generation process.
vLLM API server─The server acts as an intermediary between the clients and the serving backend. The API server handles incoming requests, forwards them to the vLLM engine for processing, and sends the generated outputs back to the clients. For example, in a local environment, clients send requests to the vLLM API server running on http://localhost:8000, which implements the OpenAI API protocol.
Serving backend─The serving backend initializes the LLM model, which occurs when the model is first deployed. When initialized, the model generates outputs based on incoming requests. The processes of model initialization and output generation have been described in detail previously.
Examining throughput and latency with online compared to offline inference scenarios
When considering throughput and latency, consider which inference architecture best serves the use case for the end-user. Real-time inference scenarios, which typically rely on online inference, yield different performance metrics than batched inference scenarios, which typically use offline inference.
Note that higher throughput does not always mean lower latency across both scenarios.
In an online inference architecture, increasing the number of concurrent requests for inference can increase overall throughput of the system, but might result in longer TTFT and inter-token latency for individual requests. If having minimal latency for an end-user is a vital part of a use case solution, it may require a tradeoff with optimal throughput.
In an offline batched inference architecture, a higher throughput might be the main concern when it comes to performance metrics as it suggests that the GPUs might be more fully used towards capacity, lowering the overall cost to run the job. Because batched inference is typically used for less urgent scenarios, latency might be of less concern.
Inference performance on PowerEdge XE9680 server with MI3000X GPUs
To evaluate the inference performance of the LLM, we used a modified version of the benchmarking scripts from the vLLM repository. The benchmarking scripts allow us to capture metrics that are crucial to evaluate the performance of an LLM, as mentioned in the Key performance metrics and factors impacting performance.
For more information about how to run the benchmarks, see the README in AMD's Benchmark | Llama 3 | Inference container at the links provided in the table below.
The following table shows the infrastructure and configuration parameters that we used to test the performance of the Llama 3 8 B and Llama 3 70 B models:
Table 11. Infrastructure and configuration parameters
Parameter
Value
Large Language Model
Llama 3 8 B, Llama 3 70 B
Number of nodes
1 PowerEdge XE9680
Number of GPUs
1 or 8 AMD MI300X
Tensor parallel size
1 or 8
Batch size
1, 2, 4, 8, 16, 32, 64, 128, or 256
Input token-sequence length/output token-sequence length
ISL:200, OSL: 1000
ISL: 7000, OSL: 1000
ISL: 2000, OSL: 200
ISL: 200, OSL: 200
Maximum number of batched tokens
32768
Iterations
10
Data type
float16
We ran all possible permutations of these parameter combinations, and collected metrics for the following: latency, inference time, time to first token (TTFT), time per output token (TPOT), and throughput. The following sections include graphs that show the results of the inference performance tests.
Llama 3 latency
The following figures show the latency of Llama 3 models:
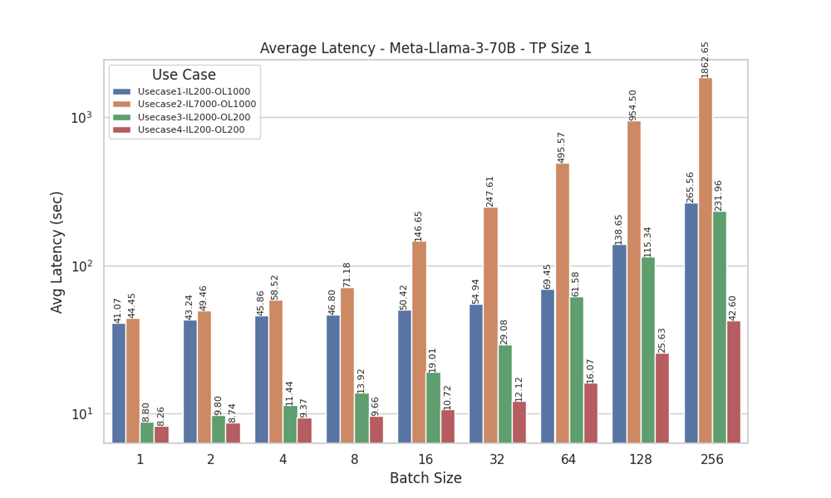
Figure 8. Average Latency for Llama 3 70B model with Tensor Parallelism of 1
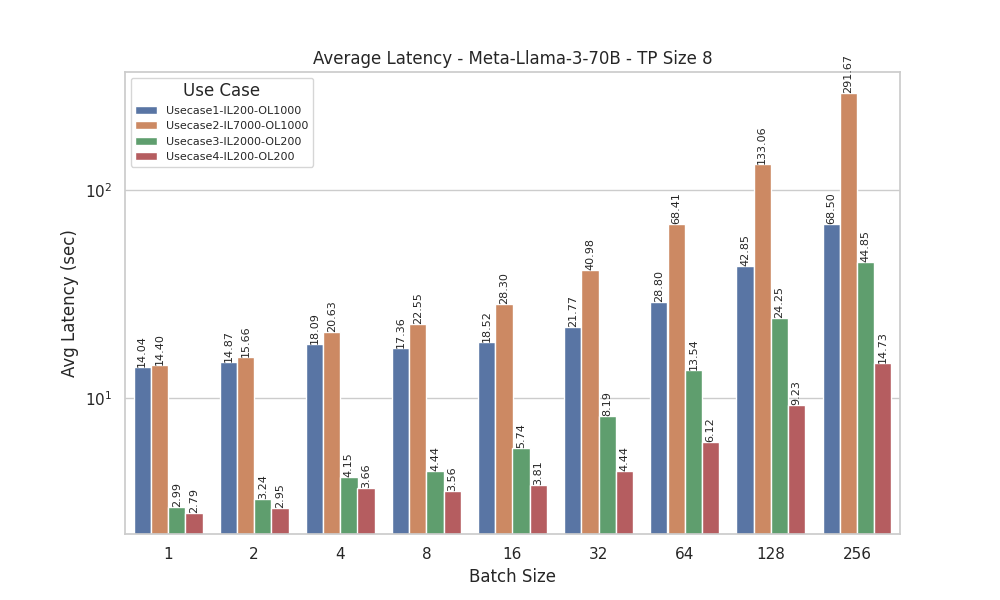
Figure 9. Average Latency for Llama 3 70B model with Tensor Parallelism of 8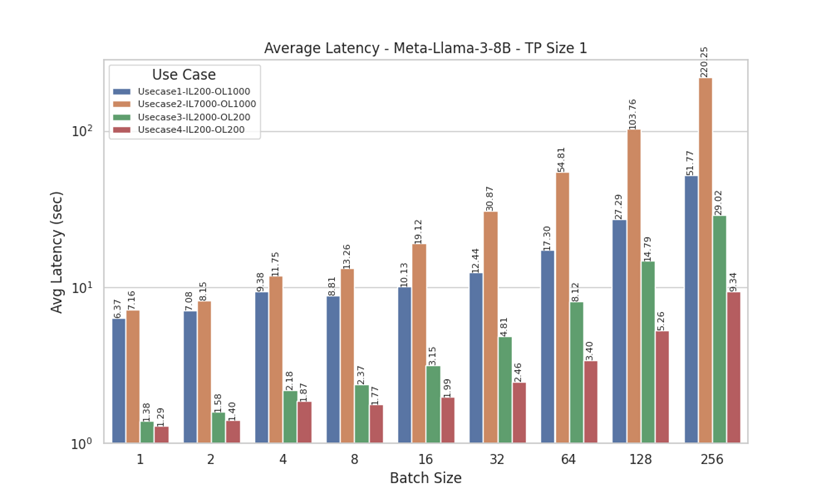
Figure 10. Average Latency for Llama 3 8 B model with Tensor Parallelism of 1
Latency measures the total time required for the model to generate a complete response to a given input. Analyzing the latency results for Meta-Llama-3-70B (with tensor parallel sizes, TP=1 and TP=8) and Meta-Llama-3-8B (TP=1) provides a comprehensive comparison of average latency (in seconds) across various batch sizes and four distinct use cases with different input and output lengths. Notably, UseCase3 (Input Length = 2000, Output Length = 200) and UseCase4 (Input Length = 200, Output Length = 200) exhibit lower latencies, likely due to their smaller output lengths.
Additionally, the impact of batch size on performance is evident, with a significant increase in latency observed for larger batch sizes (64 to 256), particularly in UseCase1 (Input Length = 200, Output Length = 1000) and UseCase2 (Input Length = 7000, Output Length = 1000). We see lower latency with TP=8 compared to TP=1, indicating more efficient processing with larger tensor parallel sizes. A similar pattern is observed for Meta-Llama-3-8B with TP Size 1. These findings highlight the importance of optimizing batch sizes for offline inference and understanding specific use case requirements to ensure efficient performance.
Tine To First Token (TTFT)
The following figures show the TTFT for the Llama models
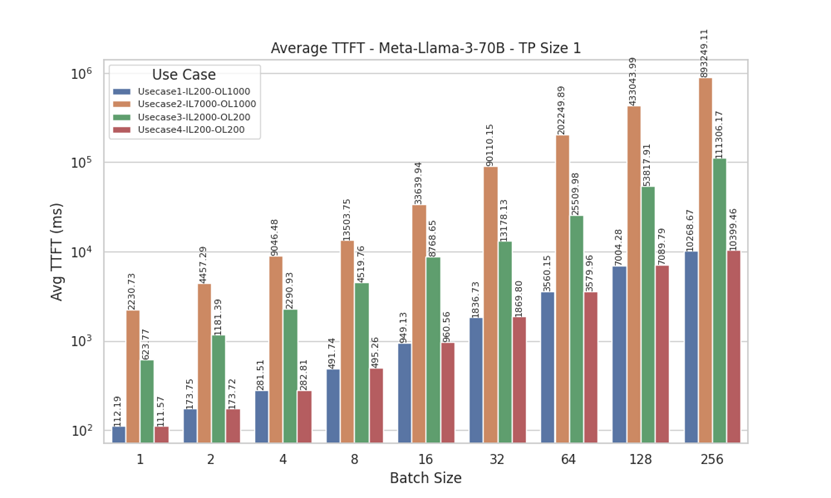
Figure 11. Average TTFT for Llama 3 70 B with Tensor Parallelism of 1
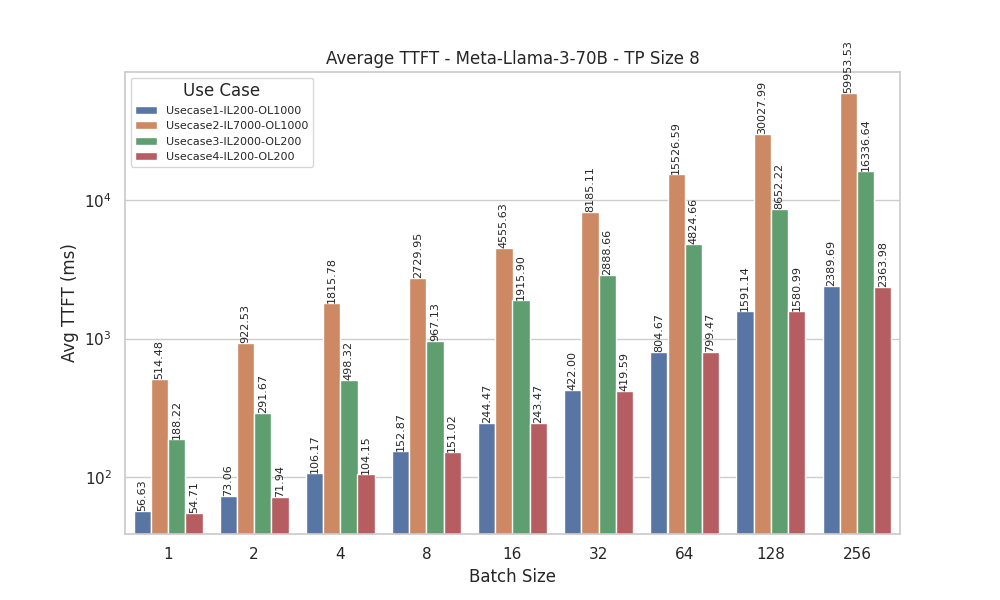
Figure 12. Average TTFT for Llama 3 70 B with Tensor Parallelism of 8
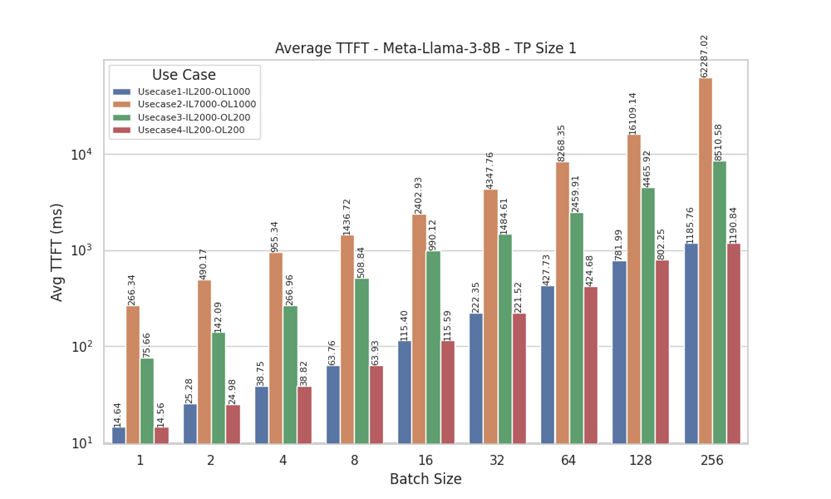
Figure 13. Average TTFT for Llama 3 8 B with Tensor Parallelism of 1
TTFT measures the initial processing time required for a model to generate the first token after receiving the prompts, indicating how quickly the model can start producing output.
From the TTFT results for Meta-Llama-3-70B (with tensor parallel sizes, TP=1 and TP=8) and Meta-Llama-3-8B (TP=1), we observe that for UseCase1 (Input Length = 200, Output Length = 1000) and UseCase4 (Input Length = 200, Output Length = 200), lower batch sizes (batch size 1 and 2) generate the first token quicker. As batch size increases, TTFT gradually rises.
However, for UseCase2 (Input Length = 7000, Output Length = 1000) and UseCase3 (Input Length = 2000, Output Length = 200), all batch sizes, including smaller ones, exhibit significantly higher TTFT. This result can be attributed to the higher input lengths in these use cases, which require more initial processing time. We observed a similar pattern for the Meta-Llama-3-8B model with TP Size 1, reinforcing the impact of input length on TTFT across different model configurations.
Throughput for Llama 3
The following figures show the throughput of Llama 3 models:
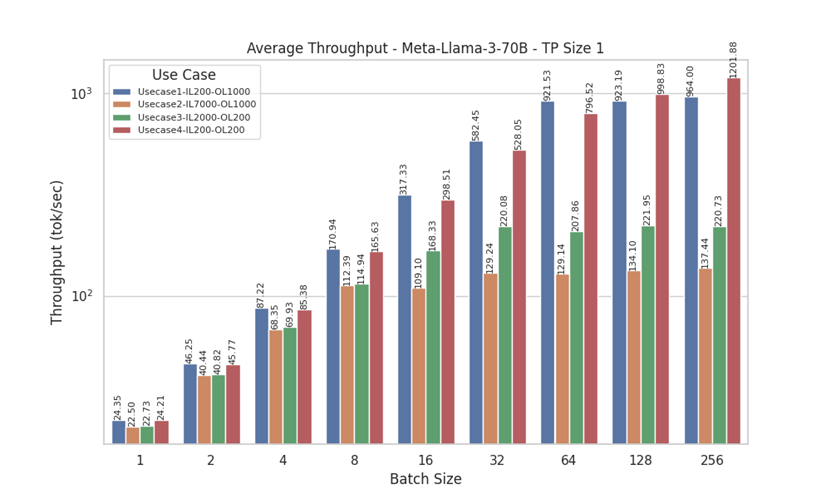
Figure 14. Throughput for Llama 3 70 B with Tensor Parallelism of 1

Figure 15. Throughput for Llama 3 70 B with Tensor Parallelism of 8
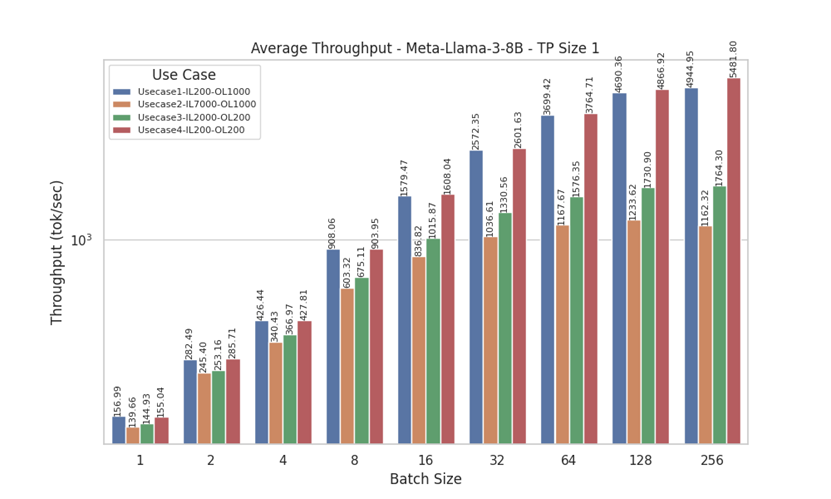
Figure 16. Throughput for Llama 3 8 B with Tensor Parallelism of 1
Analyzing the throughput results for Meta-Llama-3-8B and Meta-Llama-3-70B (with tensor parallel sizes, TP, of 1 and 8), we observe distinct patterns across different use cases. For UseCase2 (Input Length = 7000, Output Length = 1000) and UseCase3 (Input Length = 2000, Output Length = 200), there is minimal to no improvement in throughput beyond a batch size of 32. In contrast, UseCase1 (Input Length = 200, Output Length = 1000) and UseCase4 (Input Length = 200, Output Length = 200) show significant increases in throughput as batch size grows. This pattern can be attributed to the shorter input lengths in UseCase1 and UseCase4, which allow for more efficient processing with larger batch sizes.
The Meta-Llama-3-8B model exhibits similar behavior, reinforcing the observation that shorter input lengths benefit more from increased batch sizes. Additionally, comparing the Meta-Llama-3-70B results for TP sizes of 1 and 8, we see that TP Size 8 consistently achieves higher tokens per second. This improvement is due to the more efficient use of all GPUs in the system, highlighting the advantages of larger tensor parallel sizes for enhancing throughput performance.
Inference infrastructure sizing guidelines
In the previous section, we examined the inference performance results for four different input token-sequence and output token-sequence length combinations, simulating many common use cases for LLMs across various enterprises. Now, consider an example LLM use case that requires higher throughput, a scenario that commonly uses offline batched inference.
When designing a system to maximize throughput, tensor parallel size is a consequential variable, as dividing the inference workload to multiple GPUs increases efficiency and allows for more tokens to be processed per second.
To determine which tensor parallel size is optimal for throughput, we designed three categories of experiments:
- Single TP1─This experiment benchmarks offline batched inference using only one (TP1) MI300x GPU in a PowerEdge XE9680 server.
- Single TP8─This experiment benchmarks offline batched inference using all eight (TP8) MI300x GPUs in a PowerEdge XE9680 server.
- Multi TP1─This experiment benchmarks offline batched inference using eight instances of the benchmark workload, each scheduled on one (TP1) MI300x GPU, effectively using all the GPUs in a PowerEdge XE9680 server.
The following table lists the experiment parameters:
Table 12. Experiment parameters
Parameters
Details
LLM
Llama3-70B
Batch size
32 (for TP1), 256 (for TP8)
Input token-sequence length
200
Output token-sequence length
200
We conducted all experiments using the Llama3-70B model. For benchmarking purposes, we chose input and output token-sequence lengths based on the "Short Input, Short Output" use case. To analyze results between TP=1 and TP=8, we set the batch size to 32 for TP=1 experiments and 256 for TP=8 experiments, ensuring each GPU had a similar amount of work during inference.
Table 13. Throughput (Tokens/second) for Llama models with different tensor parallelism size
Scenario
Llama 3 70 B
Llama 3 8 B
Single TP1
532
2601
Single TP8
3608
8000
Multi TP1
4241
18594
The results show that the single TP8 experiment with a batch size of 256 achieved a 6.7 times better throughput compared to the single TP1 experiment.
This improvement can be primarily attributed to the higher batch size and the use of multiple GPUs. However, when comparing the single TP8 experiment to the multi-TP1 experiment, the latter achieved a cumulative throughput of 4241 tokens per second. This result is a 1.1 times improvement in throughput compared to the single TP8 experiment. This comparison highlights the importance of optimizing tensor parallel size to maximize throughput in LLM applications.
We also conducted similar experiments using the Llama3-8B model. Although running a smaller model like Llama3-8B on all eight GPUs (TP8) might underuse the GPU resources, we provide a general comparison for informational purposes.
The results indicate that the single TP8 setup for the "Short Input, Short Output" use case achieved a 3.07 times higher throughput compared to the single TP1 setup. Additionally, when comparing the single TP8 results with the multi-TP1 experiment, we observed that the multi-TP1 setup improved throughput by 2.5 times compared to the single TP8 results.
When designing a system to maximize throughput, the results show that using multiple instances provides near-linear scaling compared to a single instance. For the Llama3-70B model, we observed a 7.9 times improvement in throughput with the multi-TP1 setup over the single TP1 experiment. Similarly, for the Llama3-8B model, there was a 7.8 times improvement. This result demonstrates that using one GPU compared to the cumulative throughput of eight instances of one GPU in a single PowerEdge XE9680 server achieves almost linear scaling.