
pixstor Solution with HDMD (without ME484s capacity expansion)
pixstor Solution with HDMD (without ME484s capacity expansion)
-
For this benchmark, we used results of the large configuration (two PowerEdge R750 servers connected to four ME4084 arrays) with the optional HDMD module (two PowerEdge R750 servers) using a single ME4024 array from the release in November 2021. Since then, the optional HDMD module (a pair of PowerEdge R750 servers with one or more ME4024 arrays) was replaced with NVMe server pairs handling the metadata. This section provides the ME4024 benchmark information as a reference, but with a new performance section for HDMD NVMe. Table 2 and Table 3 list the software versions used on the servers and clients respectively.
Sequential IOzone performance N clients to N files
Sequential N clients to N files performance was measured with IOzone version 3.492. The tests that we ran varied from a single thread up to 1024 threads.
We used files large enough to minimize caching effects, with a total data size of 8 TiB, more than twice the total memory size of the servers and clients. Note that GPFS sets the tunable page pool to the maximum amount of memory used for caching data, regardless of the amount of RAM that is installed and free (set to 32 GiB on clients and 96 GiB on servers to allow I/O optimizations). While other Dell HPC solutions used the block size for large sequential transfers as 1 MiB, GPFS was formatted with a block size of 8 MiB; therefore, use that value or its multiples on the benchmark for optimal performance. A block size of 8 MiB might seem too large and waste too much space when using small files, but GPFS uses subblock allocation to prevent this situation. In the current configuration, each block was subdivided into 512 subblocks of 16 KiB each.
The following commands were used to run the benchmark for write and read operations, where Threads was the variable with the number of threads used (1 to 512 incremented in powers of 2), and threadlist was the file that allocated each thread on a different node, using the round robin method to spread them homogeneously across the 16 compute nodes. The FileSize variable has the result of 8192 (GiB)/Threads to divide the total data size evenly among all threads used. A transfer size of 16 MiB was used for this performance characterization.
./iozone -i0 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 16M -s ${FileSize}G -t $Threads -+n -+m ./threadlist
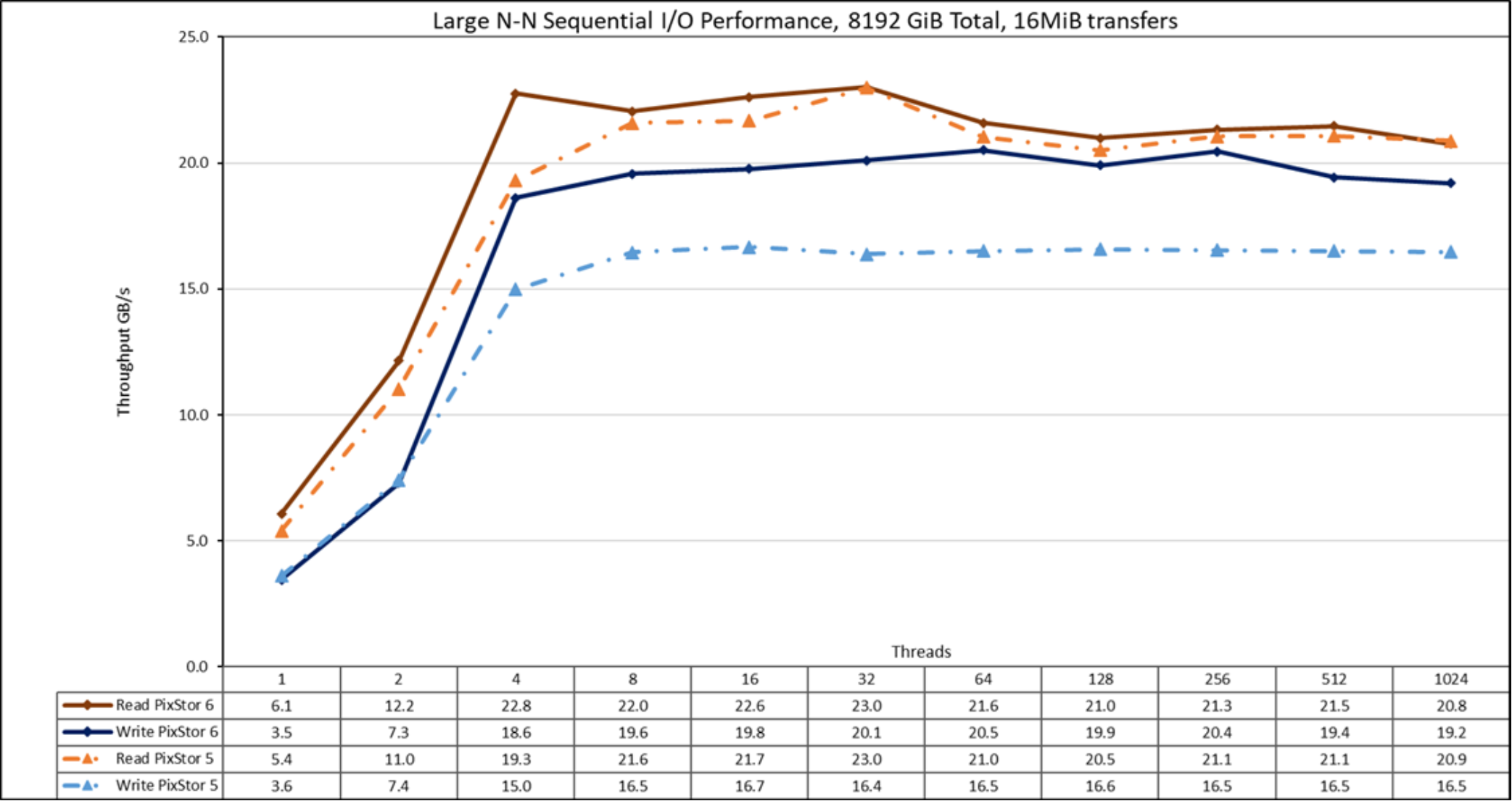
Figure 17. N to N sequential performance
From the results, we see that read performance is higher than the previous release at low thread counts (>10%) peaking at four threads where it was almost 18 percent higher than pixstor 5. After that, it is only marginally higher than what observed with pixstor 5, with a small drop in performance at 1024 threads. Write performance was almost the same for one and two threads. At four threads, it was 24 percent higher than pixstor 5. A plateau was reached and remained about 20 percent higher than pixstor 5 until the maximum number of threads allowed by IOzone was reached and performance dropped slightly at 1024 threads (because there are only 640 cores in the nodes, this result might be due to oversubscription overhead). Note that the peak read performance was 23 GB/s at 32 threads and the peak write performance of 20.5 was reached at 64 threads. The significant improvement in write performance (compared to pixstor 5) was an unexpected but good result. This result might be due to Block IO improvements in Red Hat Enterprise Linux 8.x or to hardware and driver improvements for the new HBA335e (a PCIe 4 adapter). Because of the total data size of 8 TiB, it cannot be due to any cache effects from servers, clients, or a combination of both.
Remember that for GPFS, the preferred mode of operation is scattered, and the solution was formatted to use it. In this mode, blocks are allocated right after file system creation in a pseudorandom fashion, spreading data across the whole surface of each HDD. While the obvious disadvantage is a lower initial maximum performance, performance remains constant regardless of how much space is used on the file system. This result is in contrast to other parallel file systems that initially use the outer tracks that can hold more data (sectors) per disk revolution. Therefore, these file systems have the highest possible performance the HDDs can provide, but as the system uses more space, inner tracks with less data per HDD revolution are used, with the consequent reduction of performance. GPFS also supports that allocation method (referred to as clustered), but it is only used on the pixstor solution as an exception in deployments under special conditions.
Sequential IOR Performance N clients to 1 file
Sequential N clients to a single shared file performance was measured with IOR version 3.3.0, with OpenMPI v4.1.2A1 to run the benchmark over the 16 compute nodes. The tests that we ran varied from a single thread up to 512 threads because there are not enough cores for 1024 threads (the 16 clients have a total of 16 x2 x 20 = 640 cores). Also, oversubscription overhead seemed to affect IOzone results at 1024 threads.
Caching effects were minimized by setting the GPFS page pool tunable value to 32 GiB on the clients and 96 GiB on the servers, and using a total data size of 8 TiB, more than twice the RAM size from servers and clients combined. A transfer size of 16 MiB was used for this performance characterization. For a complete explanation, see Sequential IOzone Performance N clients to N files.
The following commands were used to run the benchmark, where Threads is the number of threads used (1 to 512 incremented in powers of 2), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes. The FileSize variable has the result of 8192 (GiB)/Threads to divide the total data size evenly among all threads used.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -w -s 1 -t 16m -b ${FileSize}G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/ior/tst.file -r -s 1 -t 16m -b ${FileSize}G
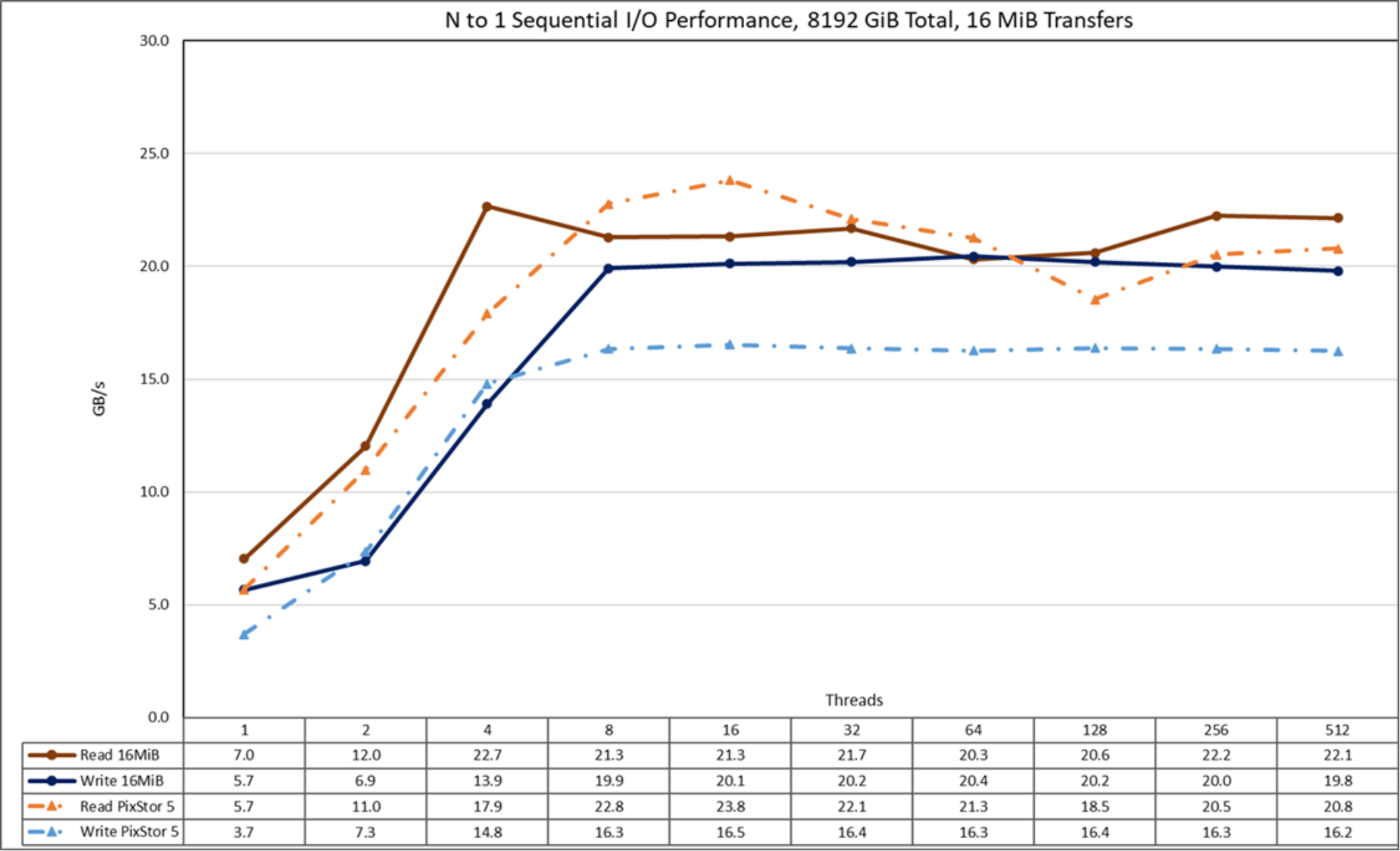
Figure 18. N to 1 sequential performance
From the results, we see that pixstor 6 has similar read performance and better write performance than the results seen in pixstor 5. However, in this case, the performance rises quickly for read operations with the number of clients used. It then reaches a plateau that is semistable for read operations and stable for write operations up to the maximum number of threads used on this test. Therefore, large, single-shared file sequential performance is stable even for 512 concurrent threads. Note that the maximum read performance was 23.8 GB/s at 16 threads. Furthermore, read performance decreased from that value until reaching the plateau at approximately 21 GB/s, with a momentary decrease below 21 GB/s at 64 and 128 threads. Similarly, note that the maximum write performance of 20.4 was reached at 64 threads and surpasses pixstor 5 results by storing 8 TiB of data that cannot be the result of cached data.
Random small blocks IOzone Performance N clients to N files
Random N clients to N files performance was measured with IOzone version 3.492. Tests results varied from 16 up to 512 threads, using 4 KiB blocks for emulating small block traffic. Lower thread counts were not used because they provide little information about maximum sustained performance and random reads execution time can take several days for a single data point (IOzone does not offer an option to run separate random writes from reads). The reason for the low random read performance is because there is not enough I/O pressure to promptly schedule read operations, due to the combined effect of the behavior of the mq-deadline I/O scheduler on the Linux operating system and the internal ME4 array controller software, delaying read operations until a threshold is met.
Caching effects were minimized by setting the GPFS page pool tunable to 16 GiB on the clients and 32 GiB on the servers and using at least files twice that size. Sequential IOzone performance N clients to N files provides a complete explanation about why this methodology is effective on GPFS.
The following command was used to run the benchmark in random IO mode for both writes and reads, where Threads was the variable with the number of threads used (from 16 to 512 incremented in powers of 2), and threadlist was the file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes.
./iozone -i0 -c -e -w -r 16M -s ${Size}G -t $Threads -+n -+m ./threadlist
./iozone -i2 -O -w -r 4K -s ${Size}G -t $Threads -+n -+m ./threadlist
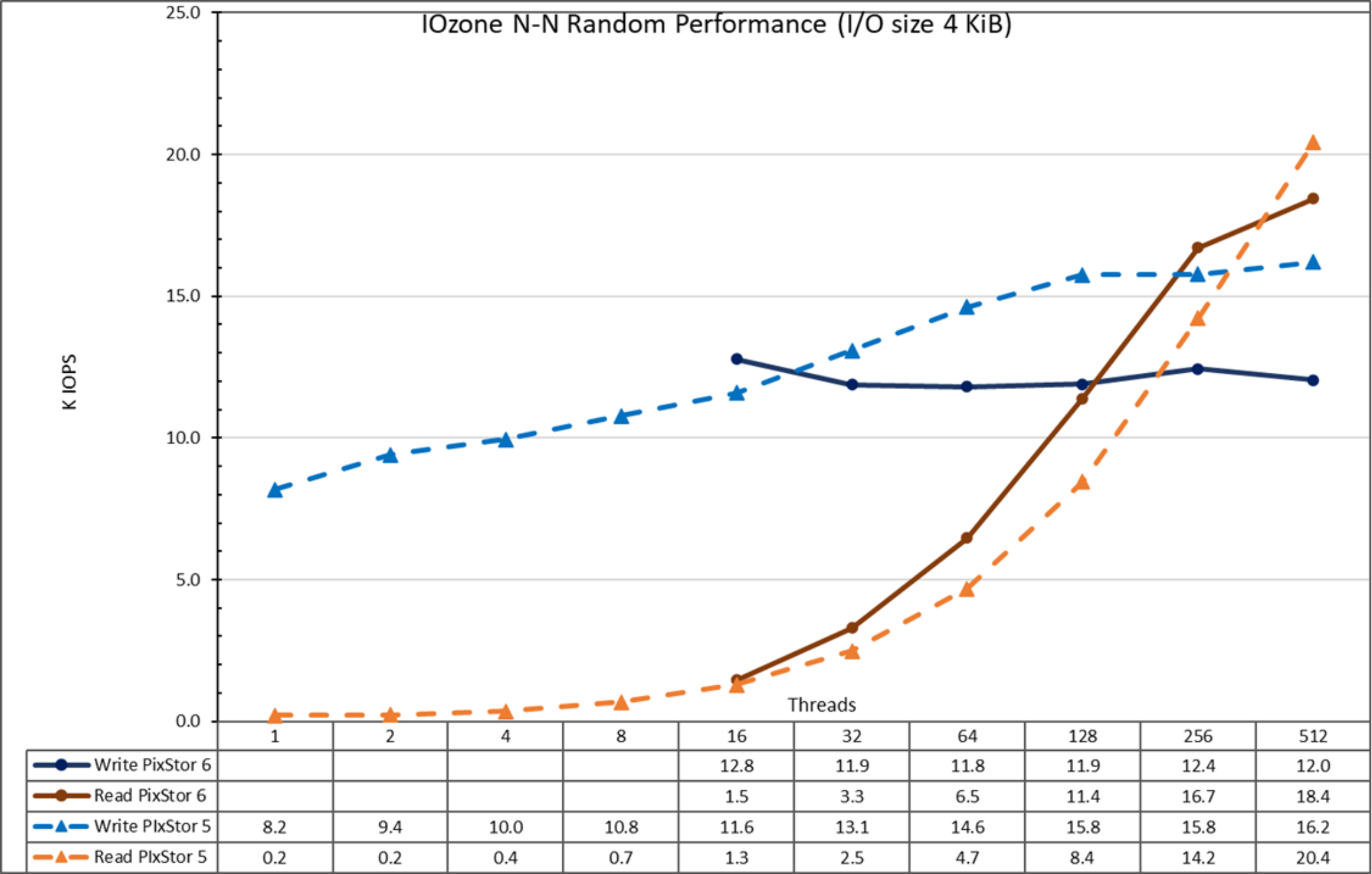
Figure 19. N to N random performance
From the results, we see that write performance starts at a high value of approximately 12.8K IOPS and remains stable above 12K IOPS. Read performance starts at a small value of 1.5K IOPS and increases performance almost linearly with the number of clients used (note that the number of threads is doubled for each data point) until it reaches the maximum performance of 18.4K IOPS at 512 threads, apparently reaching a plateau. As previously explained, using more threads than the number of cores on the current 16 compute nodes (640) might incur more context switching and other related issues that might cause a lower apparent performance, where the arrays could in fact maintain the performance. A future test with more compute nodes can check the random read performance that 1024 threads with IOzone can achieve. Also, FIO or IOR can be used to investigate the behavior with more clients and more than 1024 threads.
ME4024 Metadata performance with MDtest using empty files
This section provides information about the metadata performance from the November 2021 release based on HDMD using ME4024 arrays. However, it was decided to replace the HDMD module based on two PowerEdge R750 servers and one or more ME4024 arrays with one or more pairs of NVMe servers based on the PowerEdge R650 server with 10 NVMe direct attached devices. Subsequent sections provide information about metadata performance on this new HDMD NVMe module with other NVMe servers for data. The next solution update of the release will provide information about metadata performance for the new HDMD NVMe module with data on ME-based storage. Chapter 7 and Chapter 8 provide metadata for HDMD NVMe module and data on NVMe tier (PowerEdge R650 and R750 servers).
Metadata performance using the HDMD module with a single ME4024 array was measured with MDtest version 3.3.0, with OpenMPI v4.1.2A1 to run the benchmark over the 16 compute nodes. The tests that we ran varied from a single thread up to 512 threads. The benchmark was used for files only (no directories metadata), getting the number of create, stat, read, and remove operations that the solution can handle.
To properly compare the solution to other Dell HPC storage solutions, the optional HDMD was used, with a single ME4024 array.
This HDMD can support up to four ME4024 arrays, and we suggest increasing the number of ME4024 arrays to four before adding another metadata module. Additional ME4024 arrays are expected to increase the metadata performance linearly with each additional array. An exception to this increase might be stat operations (and read operations for empty files) because their numbers are high and eventually the CPUs become a bottleneck and performance does not continue to increase linearly.
The following command was used to run the benchmark, where the Threads variable is the number of threads used (1 to 512 incremented in powers of 2), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes. Like the Random IO benchmark, the maximum number of threads was limited to 512 because there are not enough cores for 1024 threads and context switching can affect the results, reporting a number lower than the actual performance of the solution.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads –map-by node --mca btl_openib_allow_ib 1 --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/mdtest -v -d /mmfs1/perf/mdtest -P -i 1 -b $Directories -z 1 -L -I 1024 -u -t -F
Because the total number of files, the number of files per directory, and the number of threads can affect performance results, we decided to keep the total number of files fixed at 2 MiB files (2^21 = 2097152), the number of files per directory fixed at 1024, and the number of directories varied, as the number of threads changed as shown in the following table:
Table 4. Distribution of files on directories by MDtest
Number of threads
Number of directories per thread
Total number of files
1
2048
2,097,152
2
1024
2,097,152
4
512
2,097,152
8
256
2,097,152
16
128
2,097,152
32
64
2,097,152
64
32
2,097,152
128
16
2,097,152
256
8
2,097,152
512
4
2,097,152
1024
2
2,097,152
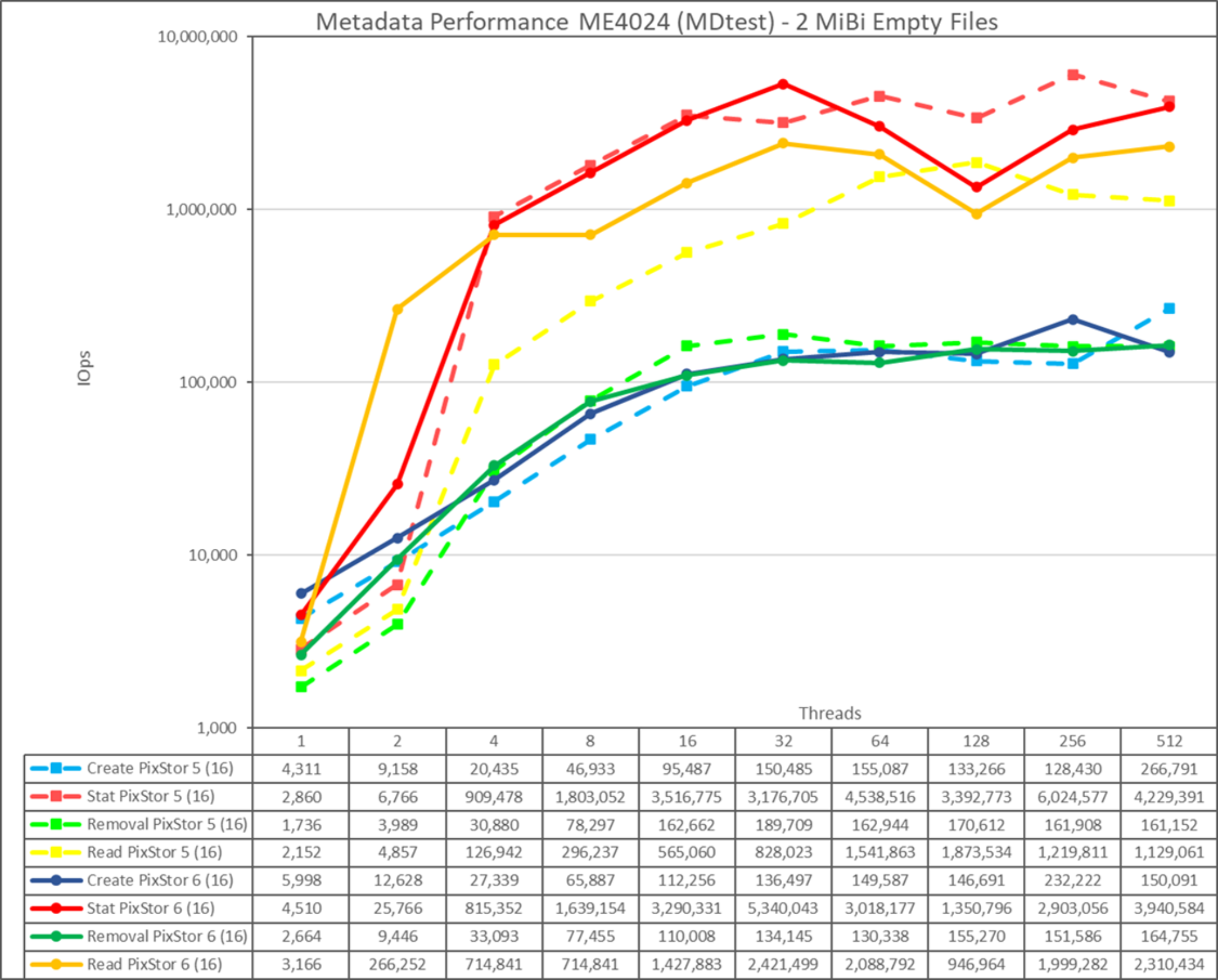
Figure 20. Metadata performance - empty files
Note that the scale chosen was logarithmic with base 10, to allow comparing operations that have differences of several orders of magnitude; otherwise, some of the operations appear like a flat line close to 0 on a normal graph. A log graph with base 2 is more appropriate because the number of threads are increased by powers of 2. Such a graph looks similar, but people tend to perceive and remember numbers based on powers of 10 better.
The system provides good results with stat and read operations reaching their peak value at 32 threads with 5.34M op/s and 2.42M op/s respectively. Remove operations attained the maximum of 164.76K op/s at 512 threads and create operations achieved their peak at 256 threads with 232.22K op/s. Stat and read operations have more variability, but when they reach their peak value, performance does not drop below 2.9M op/s for stat operations and 2M op/s for read operations. Create and remove operations are more stable when they reach a plateau: and remain above 130K op/s for remove operations remain above 130K op/s and create operations remain above 146K op/s.
Metadata performance with MDtest using 4 KiB files
This test is almost identical to the previous test, except that we used small files of 4 KiB instead of empty files. The following command was used to run the benchmark, where the Threads variable is the number of threads used (1 to 512 incremented in powers of 2), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads –map-by node --mca btl_openib_allow_ib 1 --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/mdtest -v -d /mmfs1/perf/mdtest -P -i 1 -b $Directories -z 1 -L -I 1024 -u -t -F -w 4K -e 4K
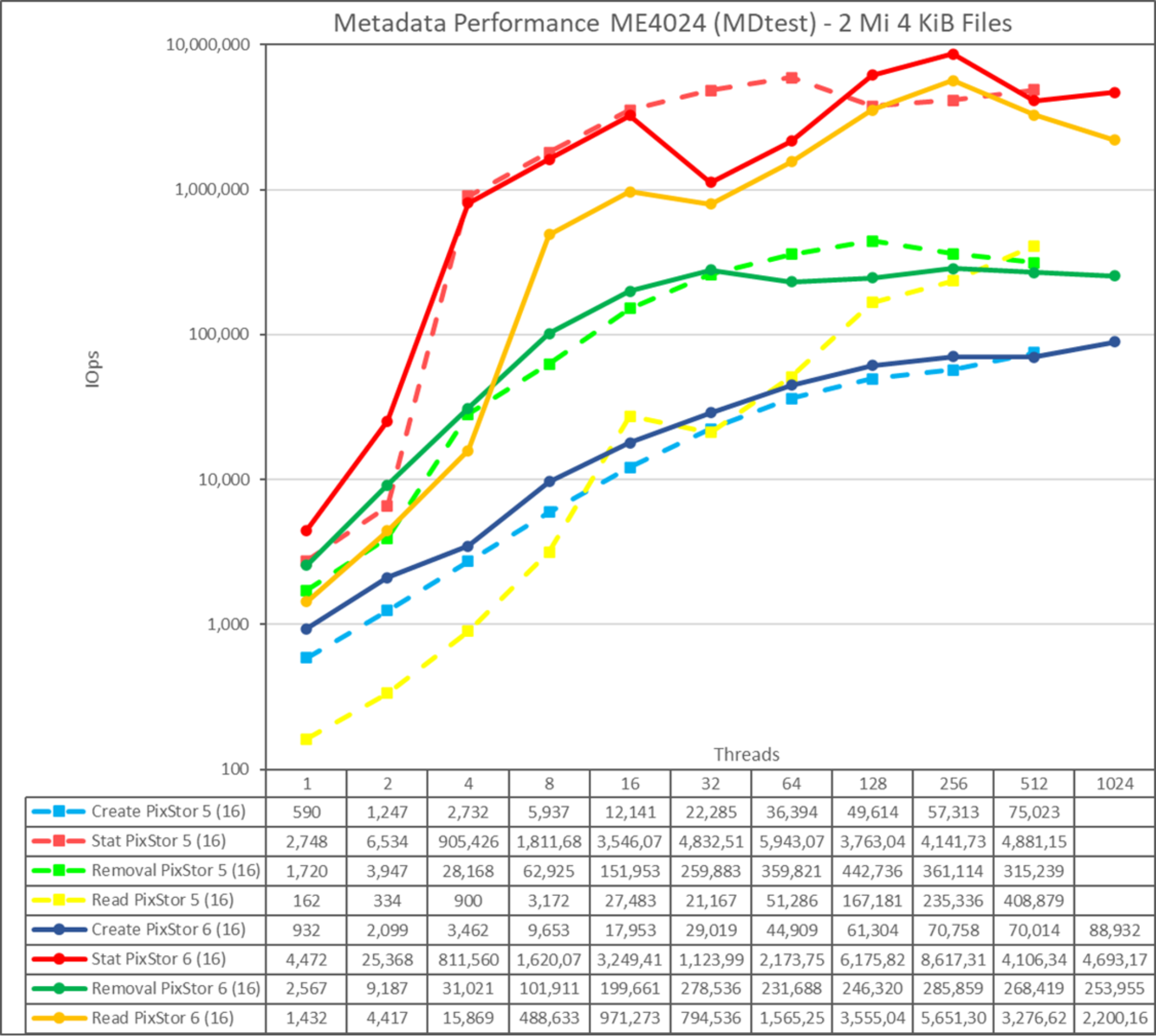
Figure 21. Metadata performance - small files (4 K)
The system provides good results for stat and operations, reaching their peak value at 256 threads with 8.62M op/s and 5.65M op/s respectively. Remove operations attained the maximum of 285.86K op/s and create operations achieved their peak with 70.76K op/s, both at 256 threads. Stat and read operations have more variability, but when they reach their peak value, performance does not drop below 4M op/s for stat operations and 3.2M op/s for read operations. Create and remove operations have less variability; create operations keep increasing as the number of threads grows, and remove operations slowly decrease after reaching their peak value.
Because these numbers are for a metadata module with a single ME4024 array, performance increases for each additional ME4024 array, however, we cannot assume a linear increase for each operation. Unless the whole file fits inside its inode, data targets on the ME4084 arrays are used to store small files, limiting the performance.
Summary
The current solution can deliver good performance, which is expected to be stable regardless of the used space (because the system was formatted in scattered mode), as can be seen in Table 5. Furthermore, the solution scales in capacity and performance linearly as more storage node modules are added, and a similar performance increase can be expected from the optional HDMD with one ME4024.
Table 5. Peak and sustained performance
Benchmark
Peak performance
Sustained performance
Write
Read
Write
Read
Large Sequential N clients to N files
20.5 GB/s
23 GB/s
19.8 GB/s
21 GB/s
Large Sequential N clients to single shared file
20.2 GB/s
21.7 GB/s
18 GB/s
21.3 GB/s
Random Small blocks N clients to N files
18.4K IOps
12.4K IOps
18.4K IOps
12. K IOps
Metadata Create empty files
232.2K Ops
150K Ops
Metadata Stat empty files
5.34M Ops
2.9M Ops
Metadata Read empty files
2.73M Ops
2M Ops
Metadata Remove empty files
189.2K Ops
13 K Ops
Metadata Create 4 KiB files
70.76K Ops
61K Ops
Metadata Stat 4 KiB files
8.62M Ops
4.1M Ops
Metadata Read 4 KiB files
5.65M Ops
3.2M Ops
Metadata Remove 4 KiB files
285.9K Ops
231.7K Ops