
All paths down and permanent device loss
All paths down and permanent device loss
-
APD and PDL
The major concern with APD and PDL is that VMs running on those devices (datastores/RDMs) can stop responding, causing unwanted outages. In cases where device removal is expected, steps can be taken to avoid these conditions. This procedure is covered below in Avoiding APD and PDL. But when it is unexpected, VMware offers some capabilities around APD and PDL for the HA cluster which allow automated recovery of VMs. The capabilities are enabled through a feature that is called VM Component Protection or VMCP. When VMCP is enabled, vSphere can detect datastore accessibility failures, APD or PDL, and then recover affected virtual machines. VMCP allows the user to determine the response that vSphere HA makes, ranging from the creation of event alarms to virtual machine restarts on other hosts.
VMCP is enabled automatically (Host Monitoring) once vSphere HA is enabled. The screen is shown in Figure 54 in the vSphere Client under the vSphere Availability menu option on the left.
Note: VMCP is not supported with vVols.
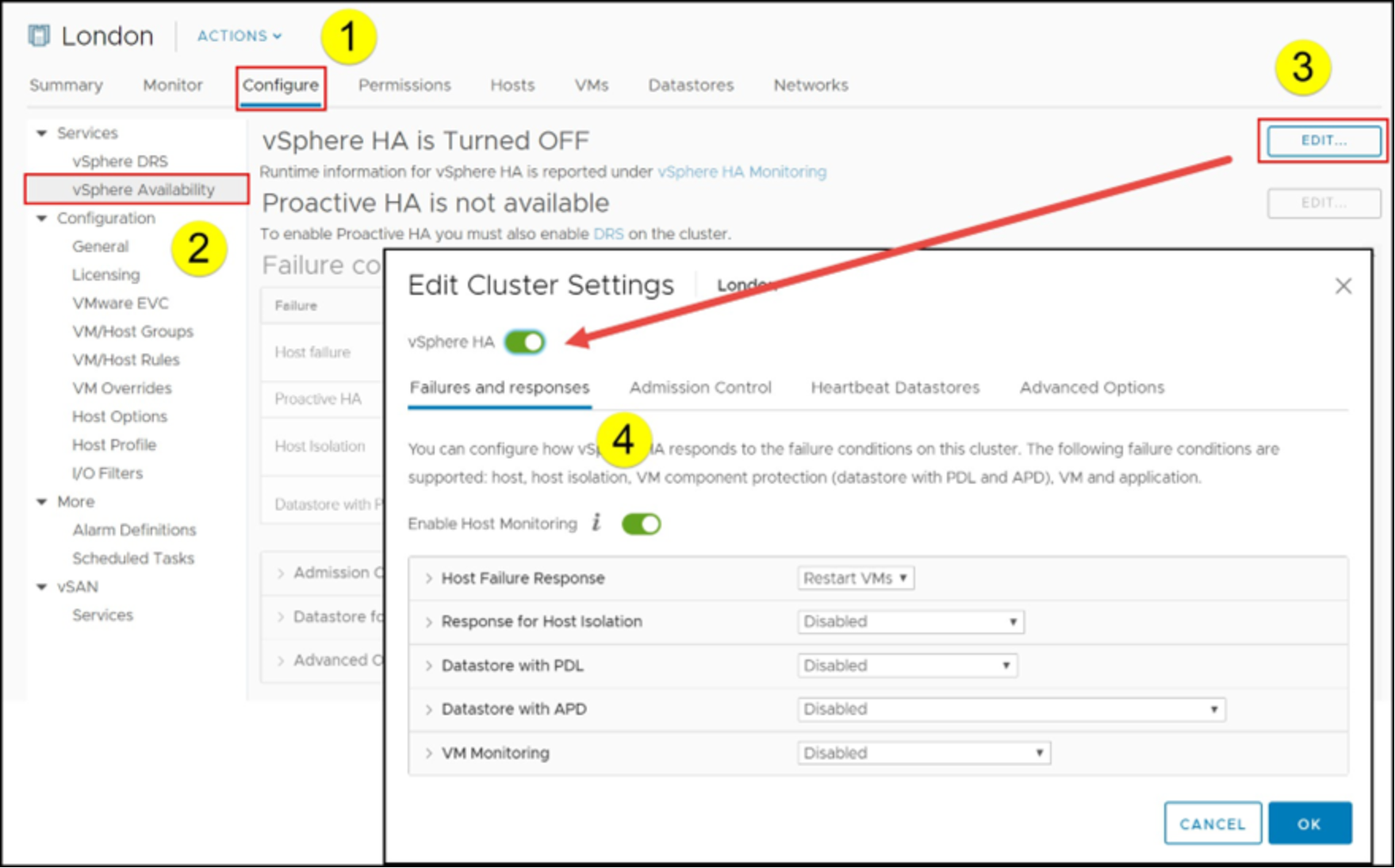
Figure 54. Enable VMCP in the vSphere Client
Once VMCP is enabled, storage protection levels and virtual machine remediations can be chosen for APD and PDL conditions as shown in Figure 55.
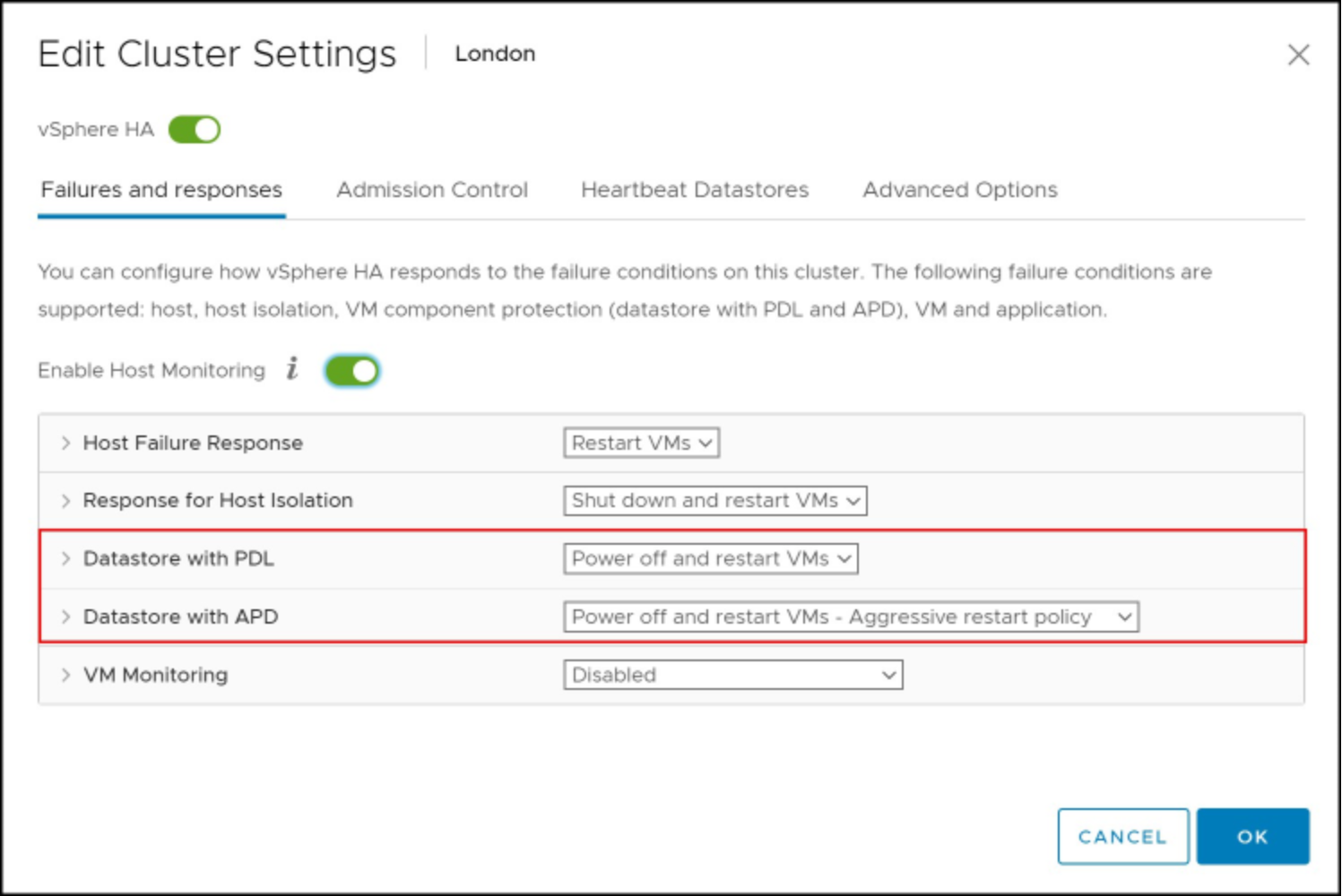
Figure 55. Storage and VM settings for VMCP in the vSphere Client
Each condition can be configured independently. The following sections detail the best practices for each.
PDL VMCP settings
The PDL settings are the simpler of the two failure conditions to configure, because there are only two choices. vSphere can either:
- Issue events.
- Initiate the power off of the VMs and restart them on the surviving hosts.
As the purpose of HA is to keep the VMs running, the default choice should always be to power off and restart. Once either option is selected, the table at the top of the edit settings is updated to reflect that choice. This update is seen in Figure 56.
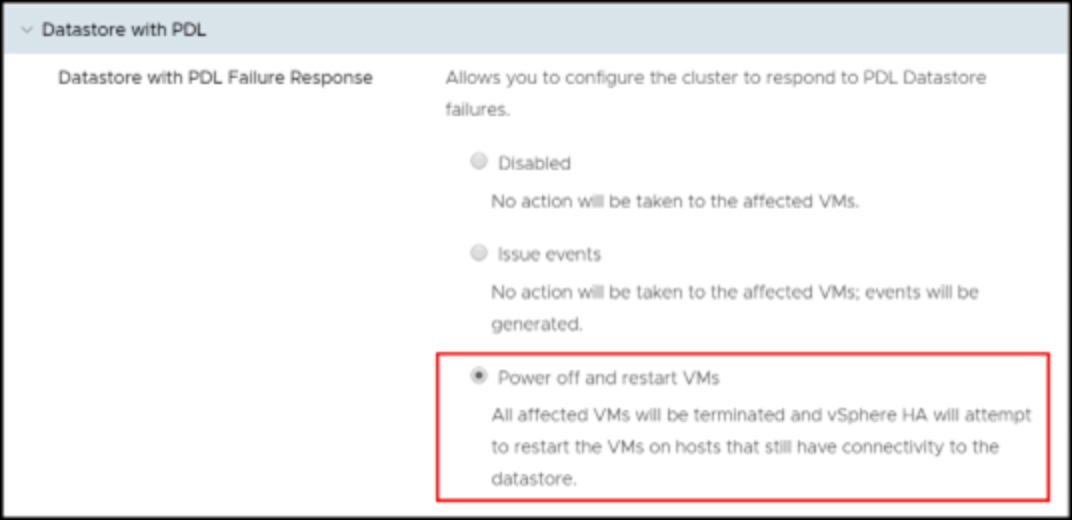
Figure 56. PDL datastore response for VMCP in the vSphere Client
APD VMCP settings
As APD events are transient by nature, and not a permanent condition like PDL, VMware provides a more nuanced ability to control the behavior within VMCP. Essentially, however, there are still two options to choose from: vSphere can issue events, or it can initiate power off of the VMs and restart them on the surviving hosts (aggressively or conservatively). Dell Technologies recommends taking the conservative approach as seen in Figure 57.
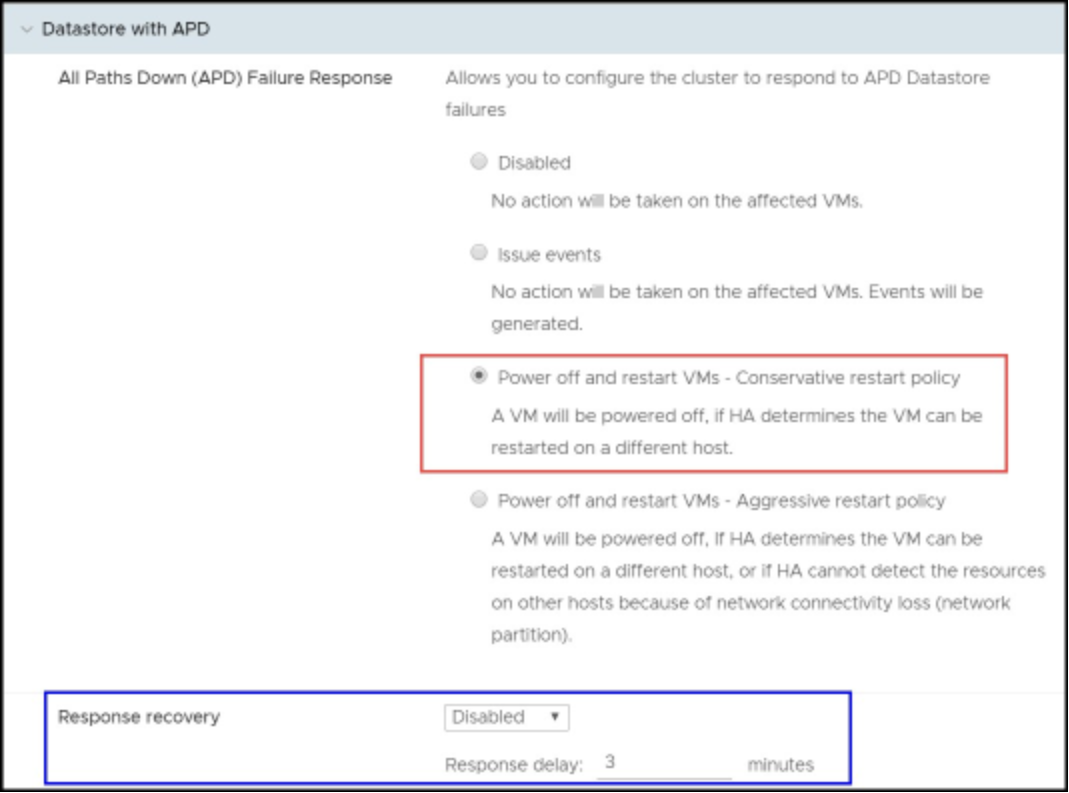
Figure 57. APD datastore response for VMCP in the vSphere Client
If issue events is selected, vSphere does nothing more than notify the user through events when an APD event occurs. As such no further configuration is necessary. If, however, either aggressive or conservative restart of the VMs is chosen, as recommended, additional options may be selected to further define how vSphere should behave. The formerly grayed-out option Response recovery is now available, and a minute value can be selected after which the restart of the VMs would proceed. This delay is in addition to the default 140-second APD timeout. The difference in approaches to restarting the VMs is straightforward. If the outcome of the VM failover is unknown, say in the situation of a network partition, then the conservative approach would not terminate the VM. The aggressive approach terminates the VM. If the cluster does not have sufficient resources, neither approach terminates the VM.
Users can choose whether vSphere should act should the APD condition resolve before the user-configured delay period is reached. If both:
- The setting “Response recovery” is set to “Reset VMs.”
- APD recovers before the delay is complete.
The affected VMs are reset, which recovers the applications that the I/O failures impacted.
This setting does not have any impact if vSphere is only configured to issue events if an APD event occurs. VMware and Dell recommend leaving this set to “Disabled” to not unnecessarily disrupt the VMs.
The configuration is shown in Figure 58.
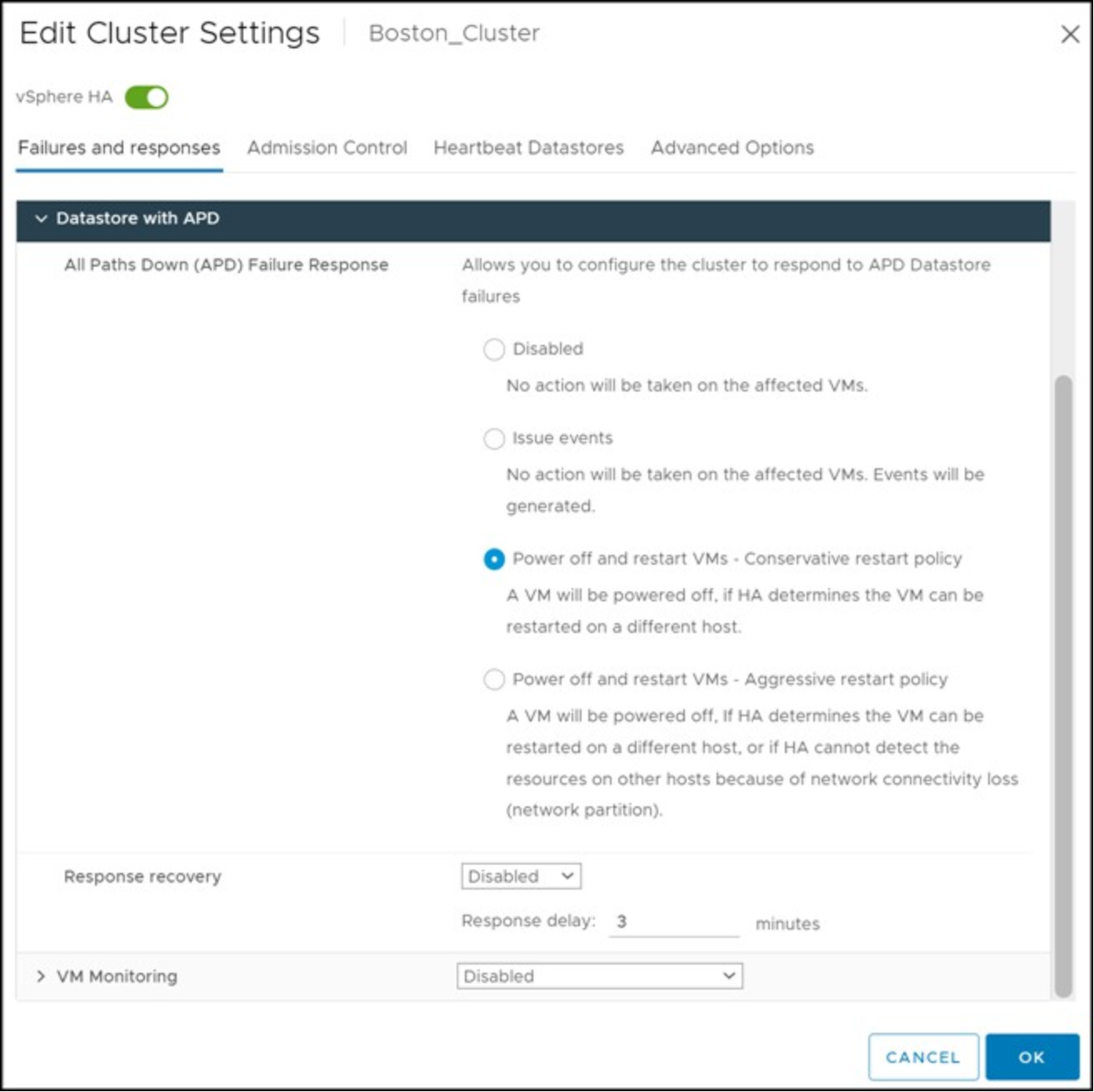
Figure 58. Other APD settings when enabling power off and restart VMs in the vSphere Client
Since the purpose of HA is to maintain the availability of VMs, VMware and Dell recommend setting APD to power off and restart the VMs conservatively. Depending on the business requirements, the three-minute default delay can be adjusted higher or lower.
Note: If either the Host Monitoring or VM Restart Priority settings are disabled, VMCP cannot perform virtual machine restarts. Storage health can still be monitored and events can be issued, however.
APD and PDL monitoring
APD and PDL activities can be monitored from within the vSphere Client or the ESXi host in the vmkernel.log file. VMware provides a screen which can be accessed by highlighting the cluster and going to the Monitor tab and vSphere HA subtab. Here can be seen any APD or PDL events. These events are transitory and no historical information is recorded. Since there is a timeout period, APD is easier to catch than PDL. Figure 59 includes an APD event in this monitoring screen for an FC-NVMe datastore in the vSphere Client.
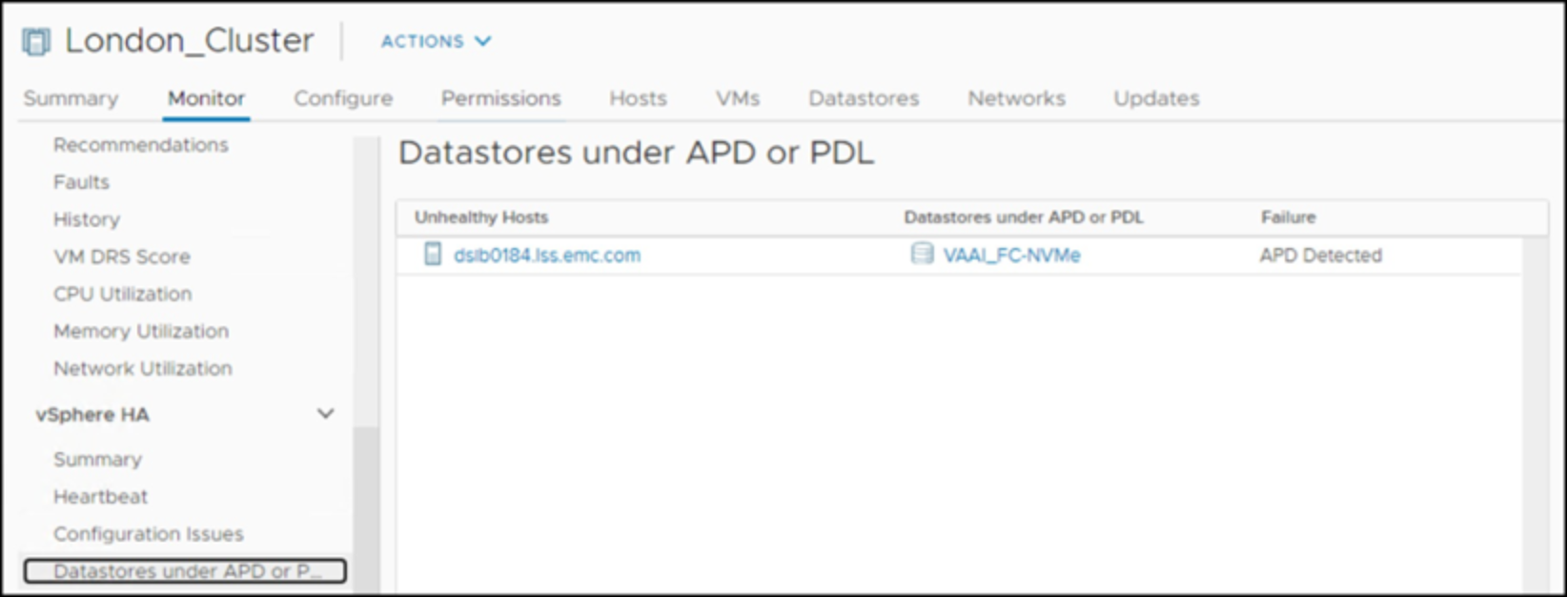
Figure 59. APD and PDL monitoring in the vSphere Client
The other way monitoring can be accomplished is through the log files in /var/log on the ESXi host. Both APD and PDL events are recorded in various log files. An example of each from the vmkernel.log file is shown in the single screenshot in Figure 60.
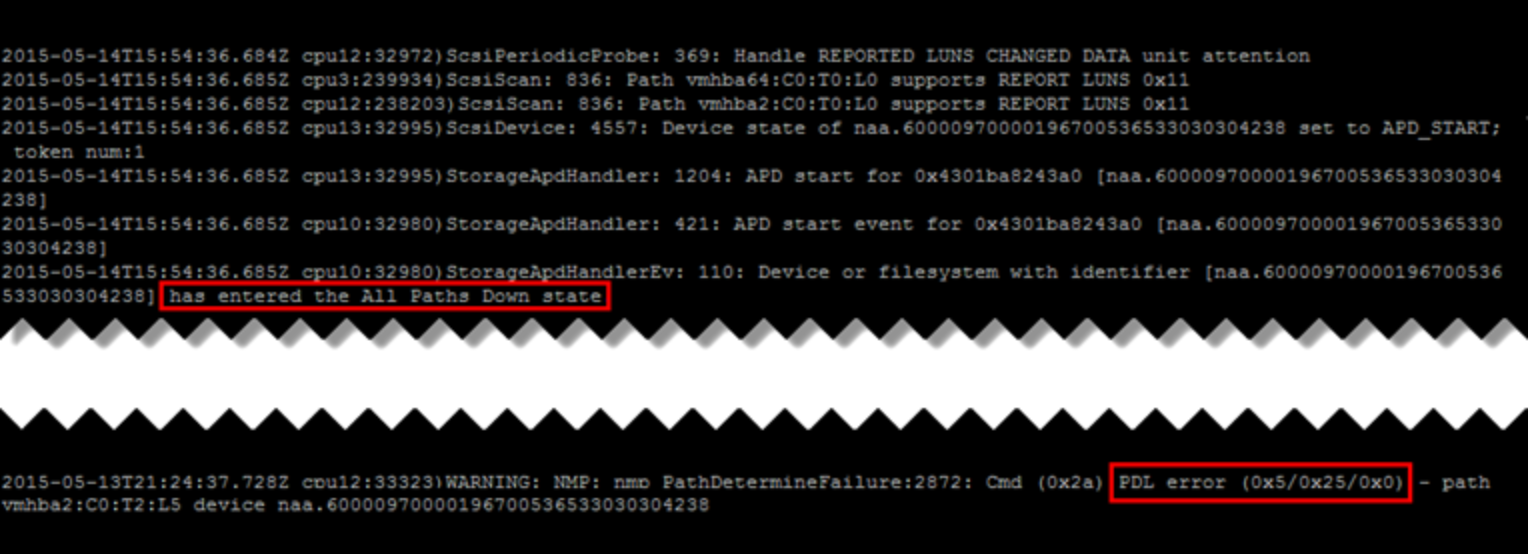
Figure 60. APD and PDL entries in the vmkernel.log