
Implementation guidance from model selection to deployment
Implementation guidance from model selection to deployment
-
The Dell Enterprise Hub on Hugging Face is designed to make selecting, configuring, and deploying AI models simpler and more reliable by filtering the optimized model choices and delivering the models in self-contained containers to deploy on Dell PowerEdge Servers.
“…[That’s the] magic of the experience, with minimal config from the enterprise hub through a simple copy and paste command, you are able to accomplish in minutes something that takes companies weeks through trial and error…”
– Jeff Boudier, Head of Product at Hugging Face
Dell Enterprise Hub on Hugging Face is available to all users and organizations. Subscribers to the Dell Enterprise Hub will use their Hugging Face credentials to log into https://dell.huggingface.co securely. The initial login process will redirect the user to authorize Dell Enterprise Hub to access the content that exists in your organization’s Enterprise Hub subscription on Hugging Face. This is an OAuth connection to grant read access to the user content and models. Terms of service on models the user has previously accepted will carry through to models curated in the Dell Enterprise Hub.
Model Catalog
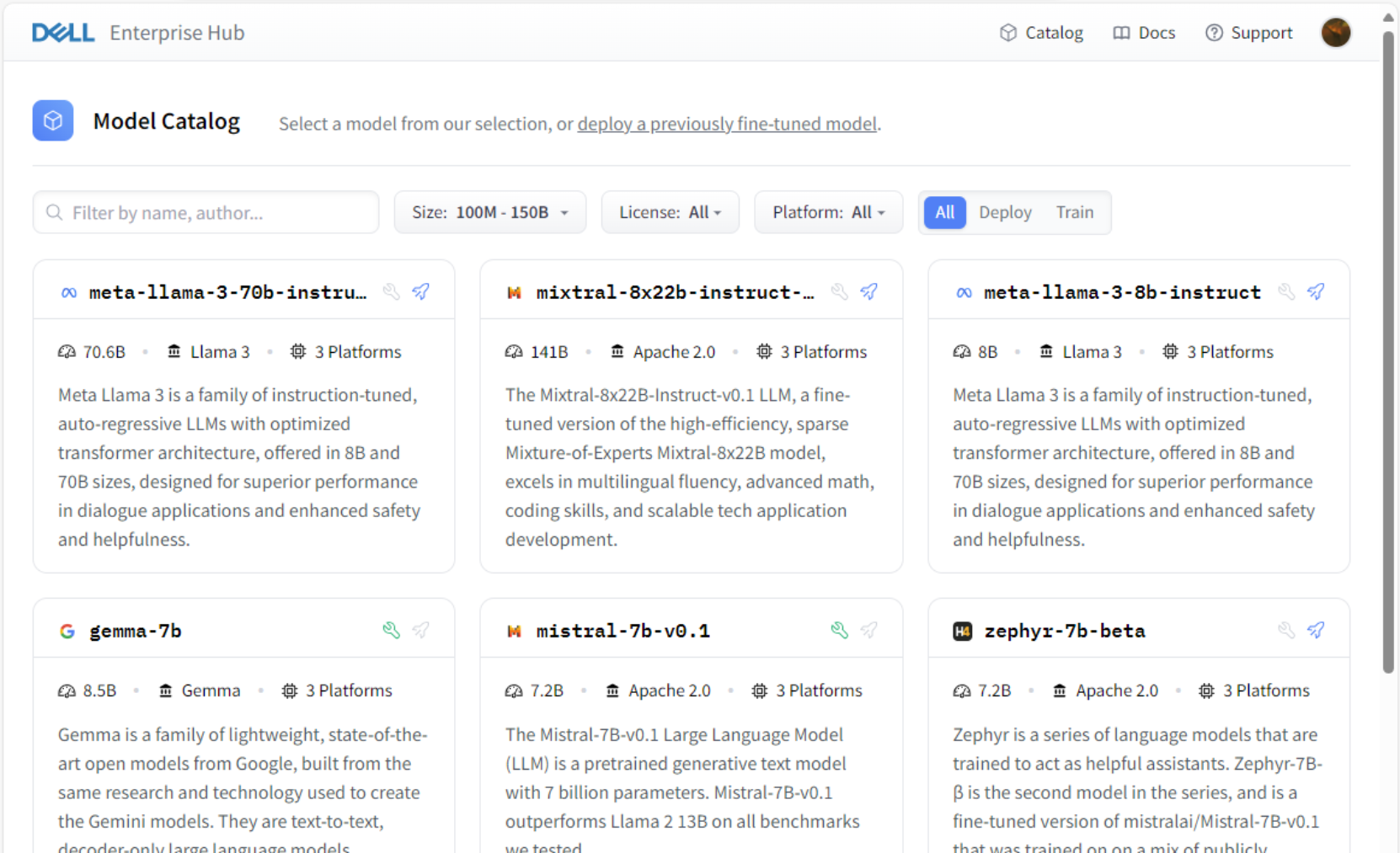
Figure 1. Sample Model Catalog, Dell Enterprise Hub on Hugging Face
While the filter functions include valid selectors such as model name, size of the model, and license type, the main filter is the Platform dropdown. This allows the Dell Enterprise Hub subscriber to select specific Dell PowerEdge server models with the available GPU options. This retrieves the exact model containers tuned specifically to Dell Server and GPU combinations to create optimized containers.
There are two types of Model Cards in the Model Catalog: Deploy and Train. The Deploy option, indicated by a small blue rocket icon next to the model title, enables developers to deploy the pretrained models to on-premises Dell platforms. The Train option, indicated by the small green wrench icon next to the model title, empowers users to leverage the model to train custom datasets using the on-premises Dell platforms and then deploy the fine-tuned model leveraging the trained data. The user clicks the model card to configure a small number of defined parameters and initiate the deployment process.
Model Card Train tab
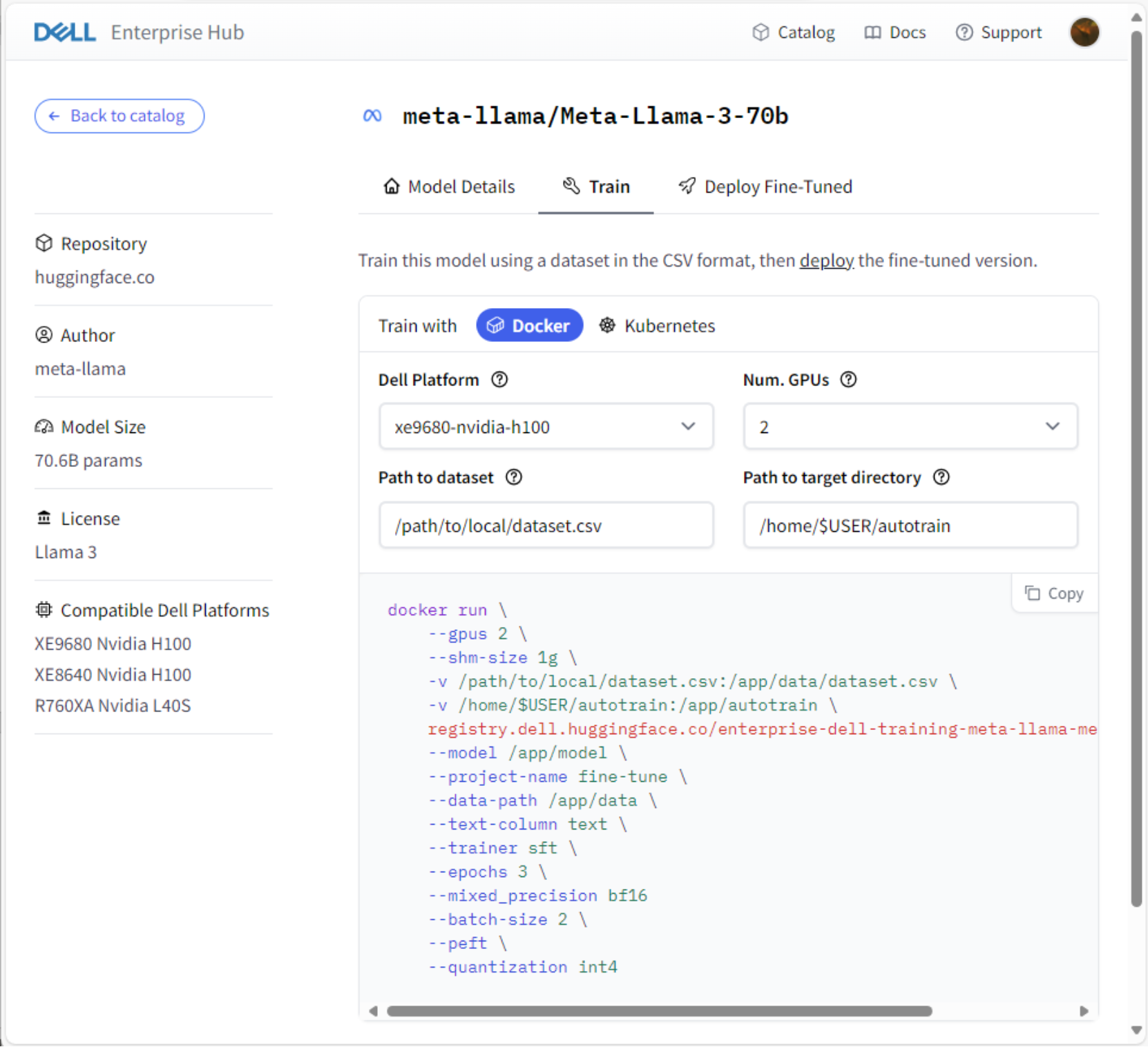
Figure 2. Sample Model Card Train tab, Dell Enterprise Hub on Hugging Face
Notice the details on the left, including Author, Model Size, License, and—specific to the Dell Enterprise Hub—Compatible Dell Platforms. The model card for the Train model allows the user to train then deploy the fine-tuned model with Docker or Kubernetes, with additional deployment options planned for future releases. To utilize the containerized feature of the Dell Enterprise Hub, the system must have one of these platforms fully deployed and configured in their on-premises Dell platform.
The Dell Platform drop-down allows users to select the appropriate hardware and GPU combination to which they wish to deploy the model. This ensures that the generated code and model information is the optimized model container for that exact hardware and GPU combination. Many Dell PowerEdge server and GPU combinations have more than 1 GPU, however the user may only want to allocate a fraction of the total to a particular model or project. The Num.GPUs field allows the user to adjust this quantity for the model.
The Path to dataset field identifies the user dataset to be trained. This can be either a mounted location on the host server or an accessible unc path from the host server. The Path to target directory defaults to the current user’s home directory and will host artifacts such as weights from the model.
The default settings in the containers are set for PEFT (Parameter-Efficient Fine-Tuning) with QLoRA (Quantization and Low-Rank Adapters). They are already included in the container automation, however users can modify this setting if another method is preferred. The user can make additional edits to the generated code snippet section, such as epochs or batch size. The containers are self-contained and prepackaged with model weights.
The user will then copy the code snippet from the Model Card and paste this code into the command line on the host server (single node) or a control node for the cluster (multi-node). Running the code will pull the Dell-optimized training container from the Hugging Face container registry. If the model has previously been pulled in this environment, the code snippet will attempt to use the local cached container registry.
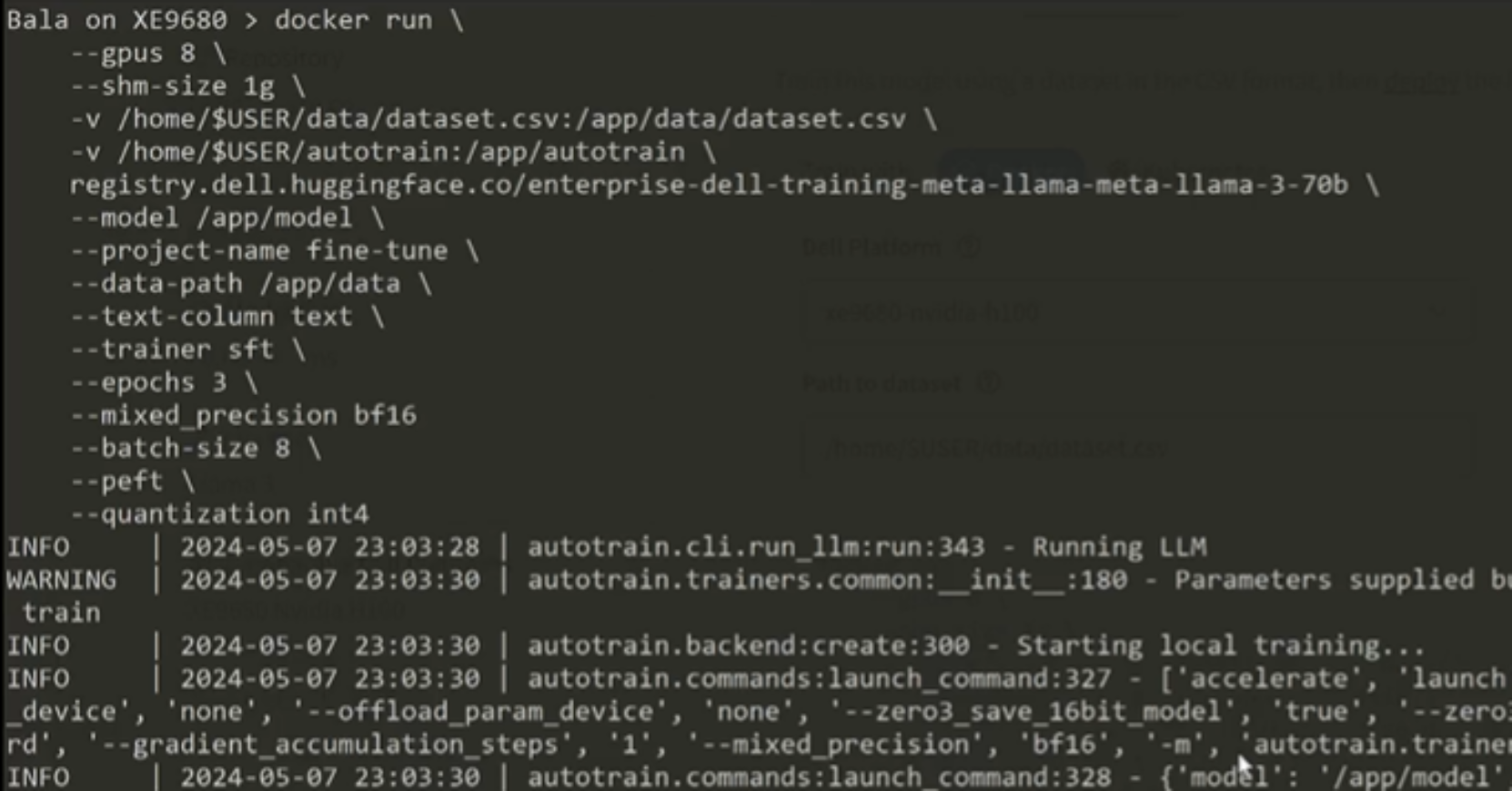
Figure 3. Sample code snippet command line – model training using docker
Hugging Face’s autotrain, a powerful tool that simplifies the model training process, is an integrated component in the container. The model will immediately spin up the required resources and begin training the model using the dataset indicated in the model card parameter. As the model training progresses, informational messages in the command line relay data about the deployment status. Once the training is completed, return to the Dell Enterprise Hub Model Card to update the Path to model field and copy the code snippet.
Model Card Deploy Fine-Tuned tab
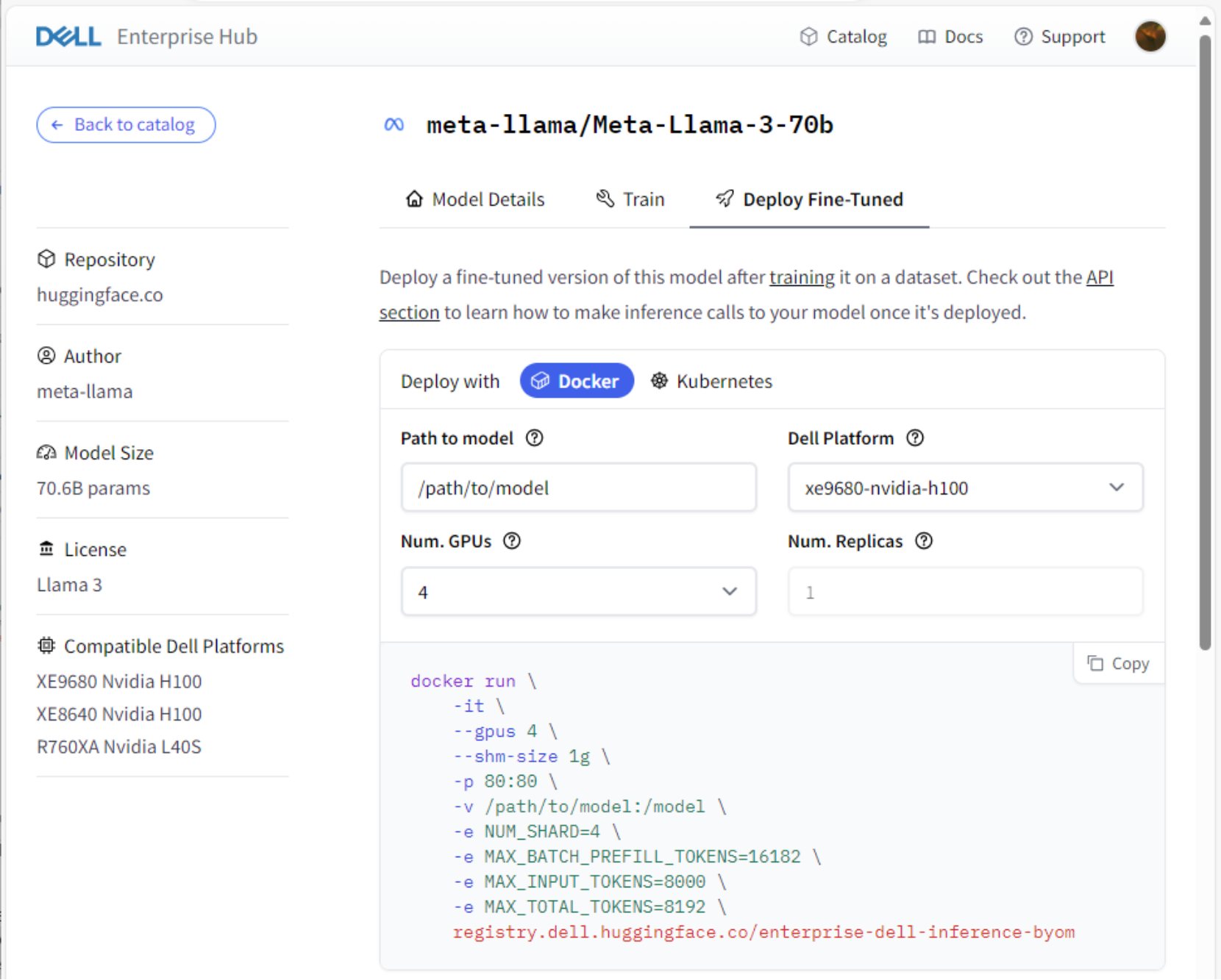
Figure 4. Sample Model Card Deploy Fine-Tuned tab, Dell Enterprise Hub on Hugging Face
During the previous training process, the model path defaults to the parent directory of the Path to target directory setting. If the default setting was used during the last process, enter the value /home/$USER/model in the Path to model field. Like the Train process, the number of GPUs can be designated. The listening port of the web service can also be set in the code snippet. Once the options are set, copy the code snipped and run it from the on-premises Dell platform to deploy the fine-tuned model.
The fine-tuned model deployment leverages the trained dataset. Once the deployment completes, the model is ready to be in the included web UI provided by the web service. A simple test with a curl command can verify the service is running and will respond with generated AI content:
curl 127.0.0.1:80/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":50}}' \
-H 'Content-Type: application/json'
Figure 5 represents the web interface for the deployed model. Users can reach the UI using any network interface on the host using the port specified in the deployment code snippet or default port 80.
Figure 5. Sample web interface for a deployed model from Dell Enterprise Hub
The containers also support API calls using the OpenAI-compatible Messages API. Developers can create dynamic applications that call the API endpoints to create custom interactions with the deployed model.