




Unlocking LLM Performance: Advanced Quantization Techniques on Dell Server Configurations


Introduction
Large Language Models (LLMs) are advanced AI systems designed to understand and generate human-like text. They use transformer architecture and are trained on extensive datasets, excelling in tasks like text generation, translation, and summarization. In business, LLMs enhance customer communication by providing accurate, context-aware responses. However, cloud-based LLM deployment raises data privacy and control concerns, prompting organizations with strict compliance needs to prefer on-premises solutions for better data integrity and regulatory compliance. While on-premises deployment ensures control, it can be costly due to the substantial compute requirements, necessitating ongoing investment. Unlike pay-as-you-go cloud services, organizations must purchase and maintain their own compute resources. To mitigate these costs, quantization techniques are employed to reduce model size with minimal loss in accuracy, making on-premises solutions more feasible.
Background
In the previous Unlocking LLM Performance: Advanced Inference Optimization Techniques on Dell Server Configurations blog, we discuss optimization techniques for enhancing model performance during inference. These techniques include continuous batching, KV caching, and context feedforward multihead attention (FMHA). Their primary goal is to improve memory use during inference, thereby accelerating the process. Because LLM inference is often memory-bound rather than computation-bound, the time taken to load model parameters into the GPU significantly exceeds the actual inference time. Therefore, optimizing memory handling is crucial for faster and more efficient LLM inference.
This blog describes the same hardware and software to provide insight into the advanced quantization techniques of LLMs on Dell servers, focusing on intricate performance enhancement techniques. These quantization methods are applied after the model has been trained to improve the inference speed. Post-training quantization techniques do not impact the weights of the base model. Our comparative analysis against the base model conveys the impacts of these techniques on critical performance metrics like latency, throughput, and first token latency. By using the throughput benchmark and first token latency benchmark, we provide a detailed technical exploration into maximizing the efficiency of LLMs on Dell servers.
Objectives
Our findings are based on evaluating the performance metrics of the Llama2-13b-chat-hf model, focusing on throughput (tokens/second), total response latency, first token latency, and memory consumption. Standardized input and output sizes of 512 tokens each were used. We conducted tests across various batch sizes to provide a comprehensive performance assessment under different scenarios. We compared several advanced quantization techniques and derived conclusions from the results.
Post-training quantization
Post-training quantization of LLMs is a fundamental strategy to diminish their size and memory footprint while limiting degradation in model accuracy. This technique compresses the model by converting its weights and activations from a high-precision data format to a lower-precision counterpart. It effectively decreases the amount of information each data point can hold, thus optimizing storage efficiency without compromising performance standards.
For this blog, we tested various post-training quantization techniques on the base Llama2-13b model and published the results, as shown in Figure 2 through Figure 7 below.
INT8 KV cache per channel
INT8 quantization in LLMs is a method of quantization in which the model's weights and activations are converted from floating-point numbers (typically 32-bit) to 8-bit integers, as shown in the following figure:
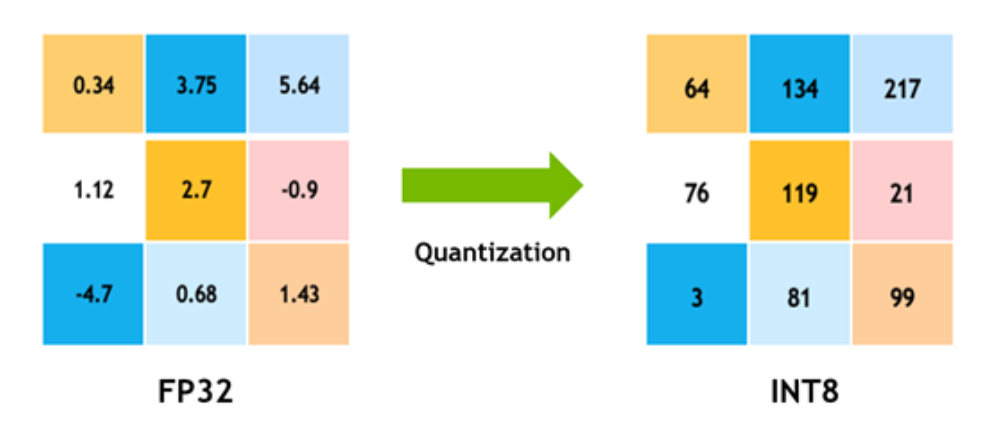
Figure 1: Quantization from FP32 to INT8*
* Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware Training with NVIDIA TensorRT
This process significantly reduces the memory footprint and computational complexity of the model while maintaining reasonable accuracy. INT8 quantization is a popular technique for optimizing LLMs for deployment in resource-constrained environments such as edge devices or mobile platforms, in which memory and computational resources are limited.
Activation-aware quantization
Activation-aware Weight Quantization (AWQ) is a sophisticated approach that enhances traditional weight quantization methods. Unlike standard quantization techniques that treat all model weights equally, AWQ selectively preserves a subset of weights crucial for optimal performance in LLMs.
While conventional methods quantize weights independently of the data that they process, AWQ integrates information about the data distribution in the activations generated during inference. By aligning the quantization process with the model's activation patterns, AWQ ensures that essential information is retained while achieving significant compression gains. This dynamic approach not only maintains LLM performance but also optimizes computational efficiency, making AWQ a valuable tool for deploying LLMs in real-world scenarios.
FP8 postprocessing
An 8-bit floating point format quantizes the model by reducing the precision from FP16 to FP8 while preserving the quality of the response. It is useful for smaller models.
GPTQ
Generalized Post-Training Quantization (GPTQ) is a technique that compresses deep learning model weights, specifically tailored for efficient GPU inference. Through a meticulous 4-bit quantization process, GPTQ effectively shrinks the size of the model while carefully managing potential errors.
The primary goal of GPTQ is to strike a balance between minimizing memory use and maximizing computational efficiency. To achieve this balance, GPTQ dynamically restores the quantized weights to FP16 during inference. This dynamic adjustment ensures that the model maintains high-performance levels, enabling swift and accurate processing of data while benefiting from the reduced memory footprint.
Essentially, GPTQ offers a streamlined solution for deploying deep learning models in resource-constrained environments, harnessing the advantages of quantization without compromising inference quality or speed.
Smooth quantization
Smooth Quant is a technique of post-training quantization (PTQ) that offers an accuracy-preserving approach without the need for additional training. It facilitates the adoption of 8-bit weight and 8-bit activation (W8A8) quantization. The innovation behind Smooth Quant lies in its recognition of the disparity in quantization difficulty between weights and activations. While weights are relatively straightforward to quantize, activations pose a greater challenge due to their dynamic nature. Smooth Quant addresses this issue by intelligently redistributing the quantization complexity from activations to weights through a mathematically equivalent transformation. By smoothing out activation outliers offline, Smooth Quant ensures a seamless transition to 8-bit quantization.
A key benefit of Smooth Quant is its versatility, enabling INT8 quantization for both weights and activations across all matrix multiplications within LLMs. This comprehensive approach not only optimizes memory use but also enhances computational efficiency during inference.
INT8 KV cache AWQ
This quantization technique combines AWQ with INT8 KV caching, providing additional benefits. In addition to quantizing the model weights based on data distribution, it stores the KV cache in INT8 format. This method improves model performance.
Comparison total
The following plots provide a comparison between the inference optimization techniques described in this blog.
Figures 2 and 3 present a throughput comparison for different quantization methods applied to the Llama2-13b-chat model running on one NVIDIA L40S GPU and one NVIDIA H100 GPU, respectively. Throughput is defined as the total number of tokens generated per second. The goal of quantization methods is to enhance throughput. The figures show the impact of quantization across four batch sizes: 1, 4, 8, and 16. Notably, the INT8 KV cache with the AWQ method achieves the highest throughput gains, with an increase of approximately 240 percent for a batch size of 1 and approximately 150 percent for a batch size of 16.
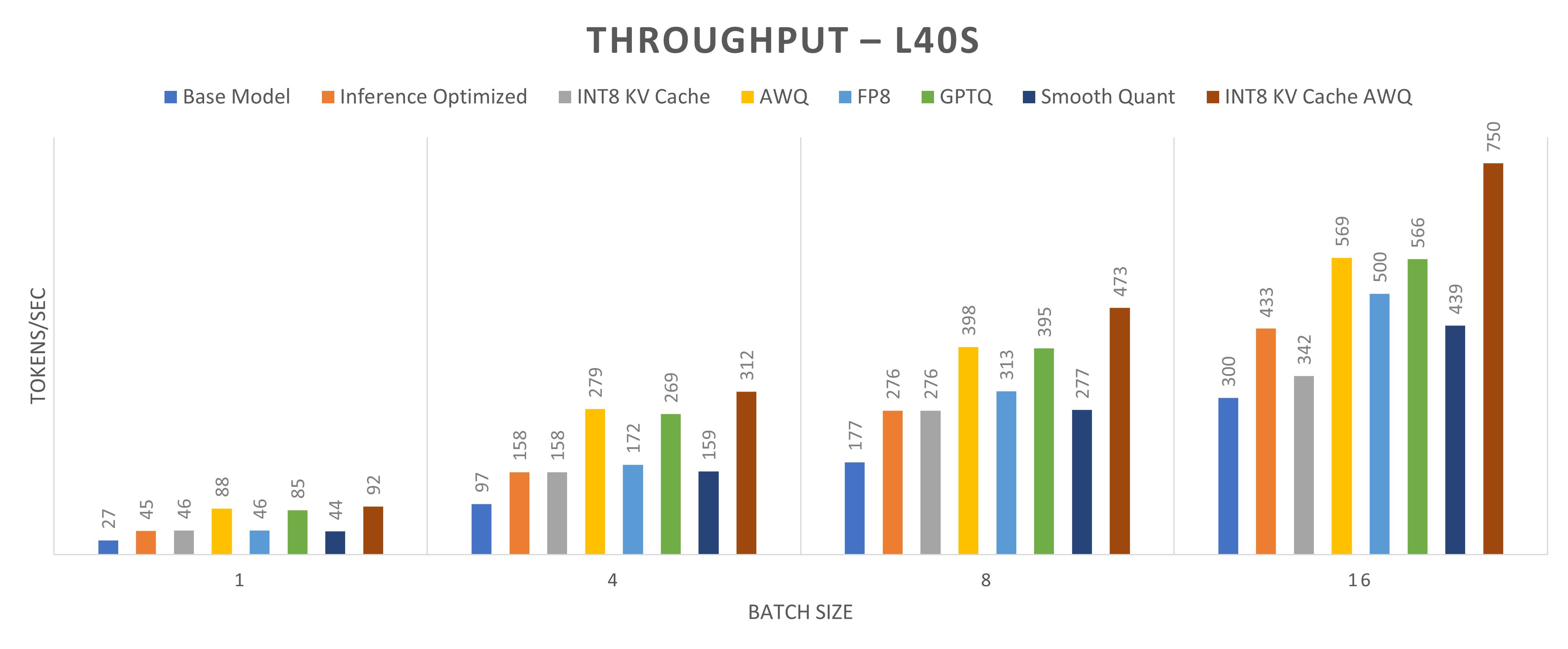
Figure 2: Throughput (tokens/sec) comparison for the Llama2-13b-chat model running on one NVIDIA L40S GPU core (higher throughput indicates better performance)
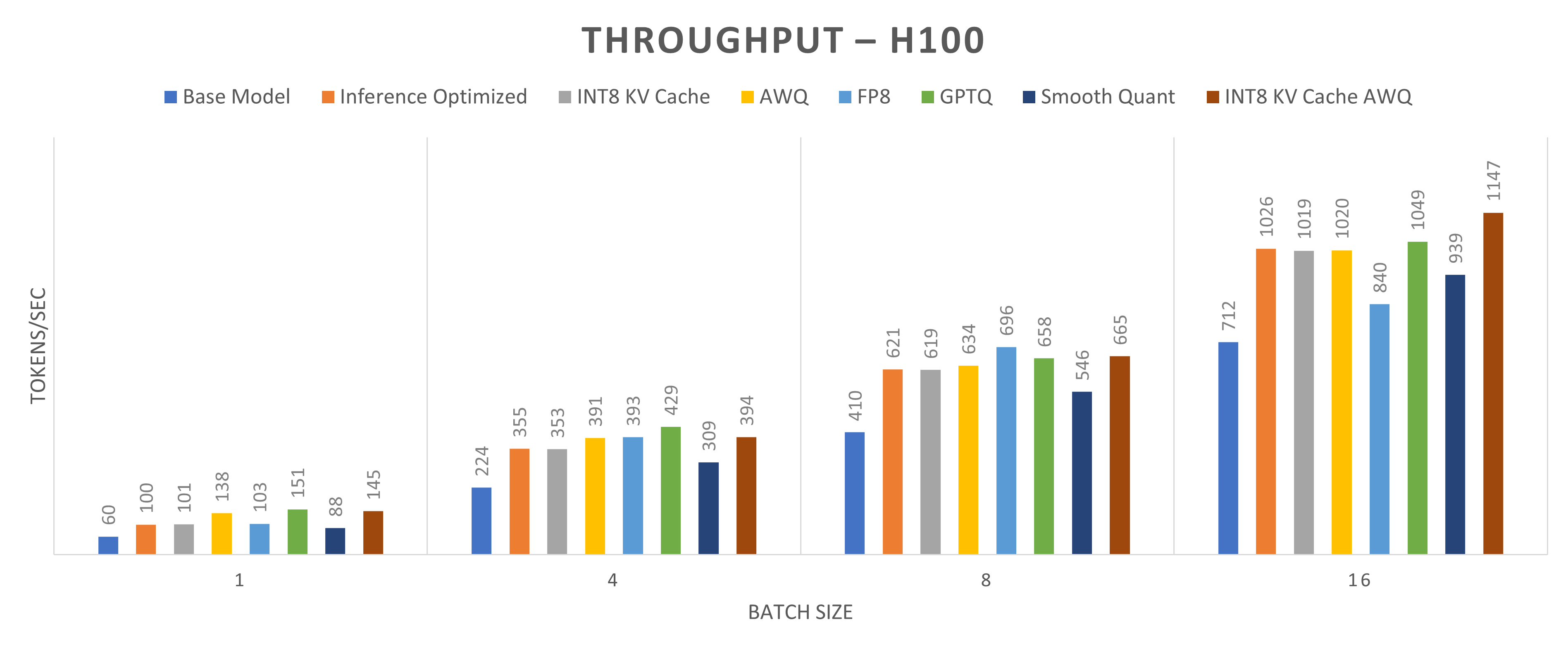
Figure 3: Throughput (tokens/sec) comparison for Llama2-13b-chat model running on one NVIDIA H100 GPU core (higher throughput indicates better performance)
Figures 4 and 5 present a comparison of total inference latency for the Llama-2-13b model quantized using different methods on one NVIDIA L40S GPU and one NVIDIA H100 GPU, respectively. Total inference latency, defined as the time taken to generate a complete response (512 tokens in this case), is shown across four batch sizes: 1, 4, 8, and 16. The primary goal of quantization is to reduce total inference latency, accelerating response generation. Among the methods evaluated, INT8 KV cache with AWQ demonstrates the lowest total inference latency, producing 512 tokens, the fastest. The reductions in total inference latency are approximately 65 percent for a batch size of 1, 60 percent for a batch size of 4, 50 percent for a batch size of 8, and 48 percent for a batch size of 16.
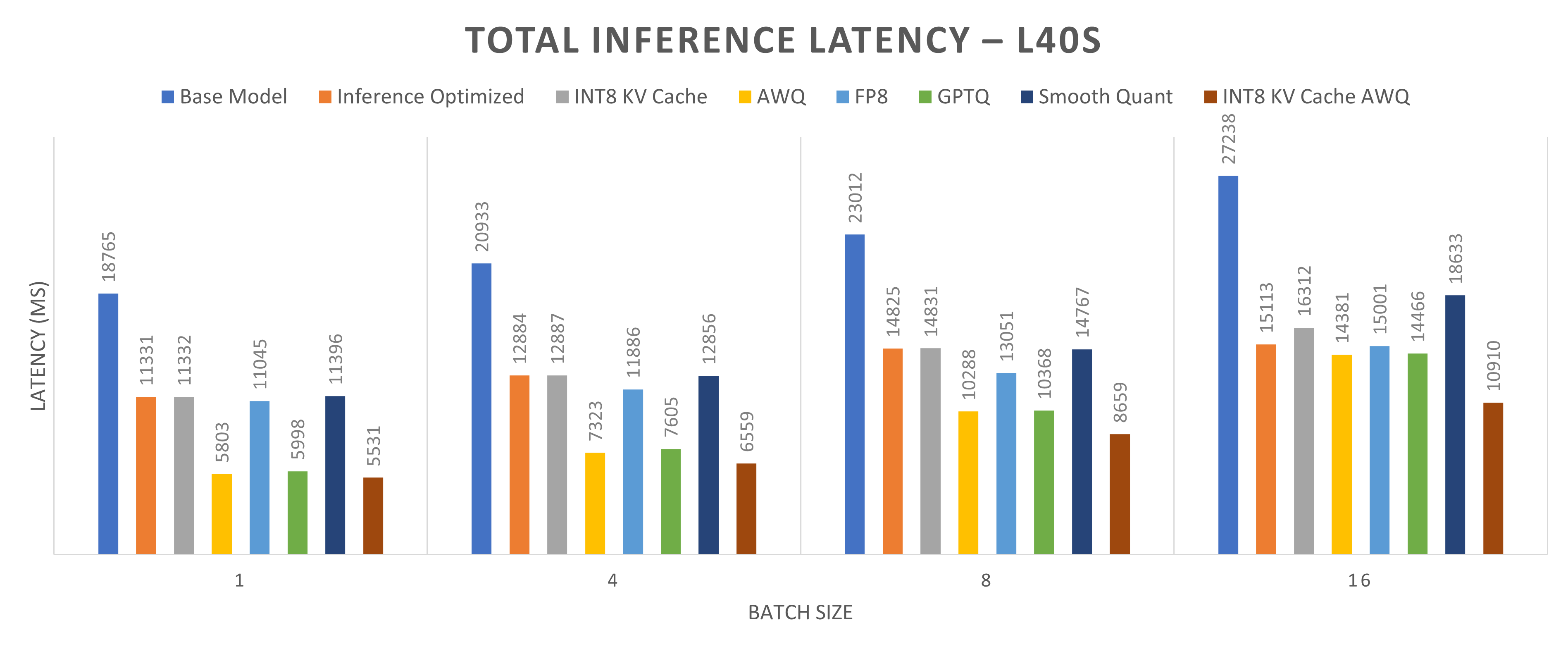
Figure 4: Total Inference Latency (MS) for Llama2-13b model running on one NVIDIA L40S GPU core.
Input size is 512 tokens, and output size is 512 tokens. Lower inference latency indicates better performance.
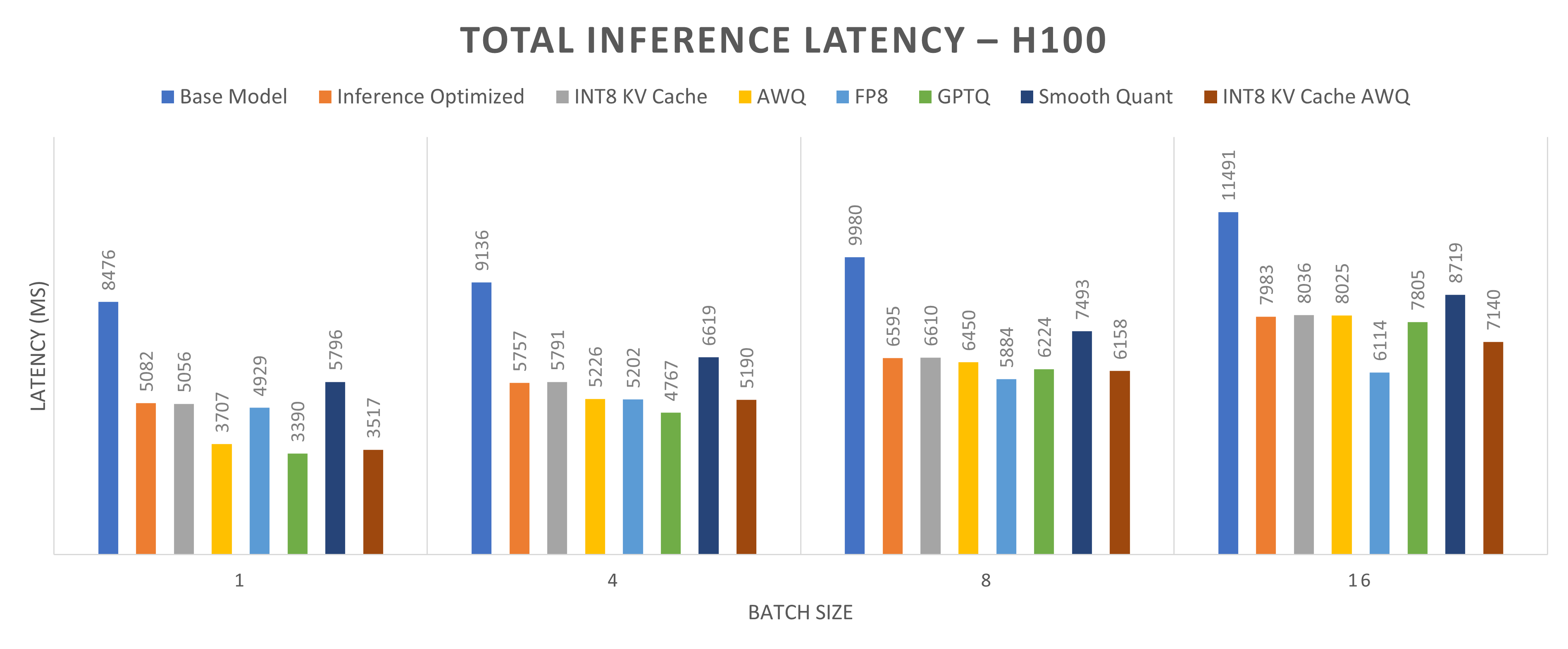
Figure 5: Total Inference Latency (MS) for Llama2-13b model running on one NVIDIA H100 GPU core.
Input size is 512 tokens, and output size is 512 tokens. Lower inference latency indicates better performance.
Figures 6 and 7 compare the first token latency of the Llama-2-13b base model using various quantization techniques on one NVIDIA L40S GPU and one NVIDIA H100 GPU, respectively. These figures show the total inference latency across four batch sizes: 1, 4, 8, and 16. First token latency is the time taken to generate the first output token. Ideally, quantization reduces first token latency, but it is not always the case because inference for quantized models is often memory-bound rather than computation-bound. Therefore, the time taken to load the model into memory can outweigh computational speedups. Quantization can increase the time to generate the first token, even though it reduces total inference latency. For instance, with INT8 KV cache with AWQ quantization, the total inference latency decreases by 65 percent for a batch size of 1, while the first token latency decreases by 25 percent on the NVIDIA L40S GPU but increases by 30 percent on the NVIDIA H100 GPU. For a batch size of 16, the first token latency decreases by 17 percent on the NVIDIA L40S GPU and increases by 40 percent on the NVIDIA H100 GPU.
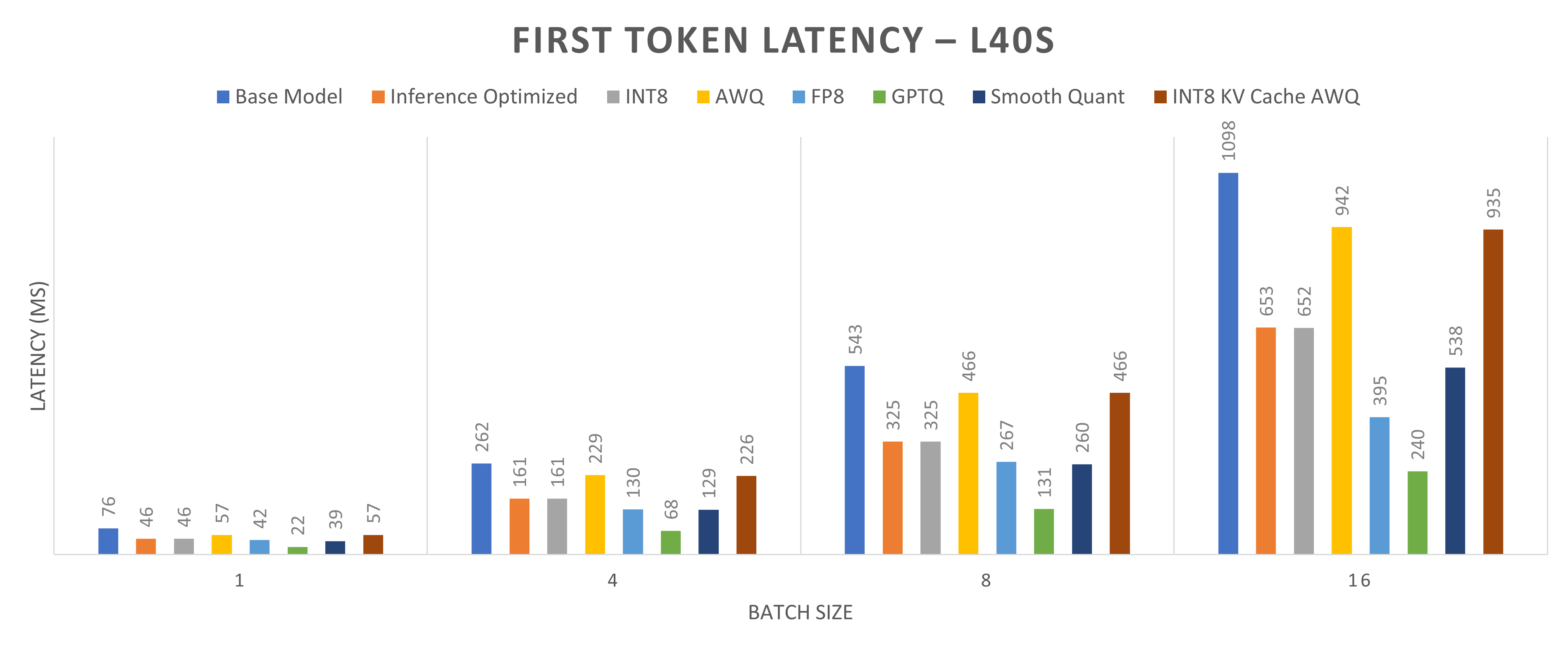
Figure 6: Time to generate first token for Llama2-13b model running on one NVIDIA L40S GPU core (lower first token latency indicates better performance)
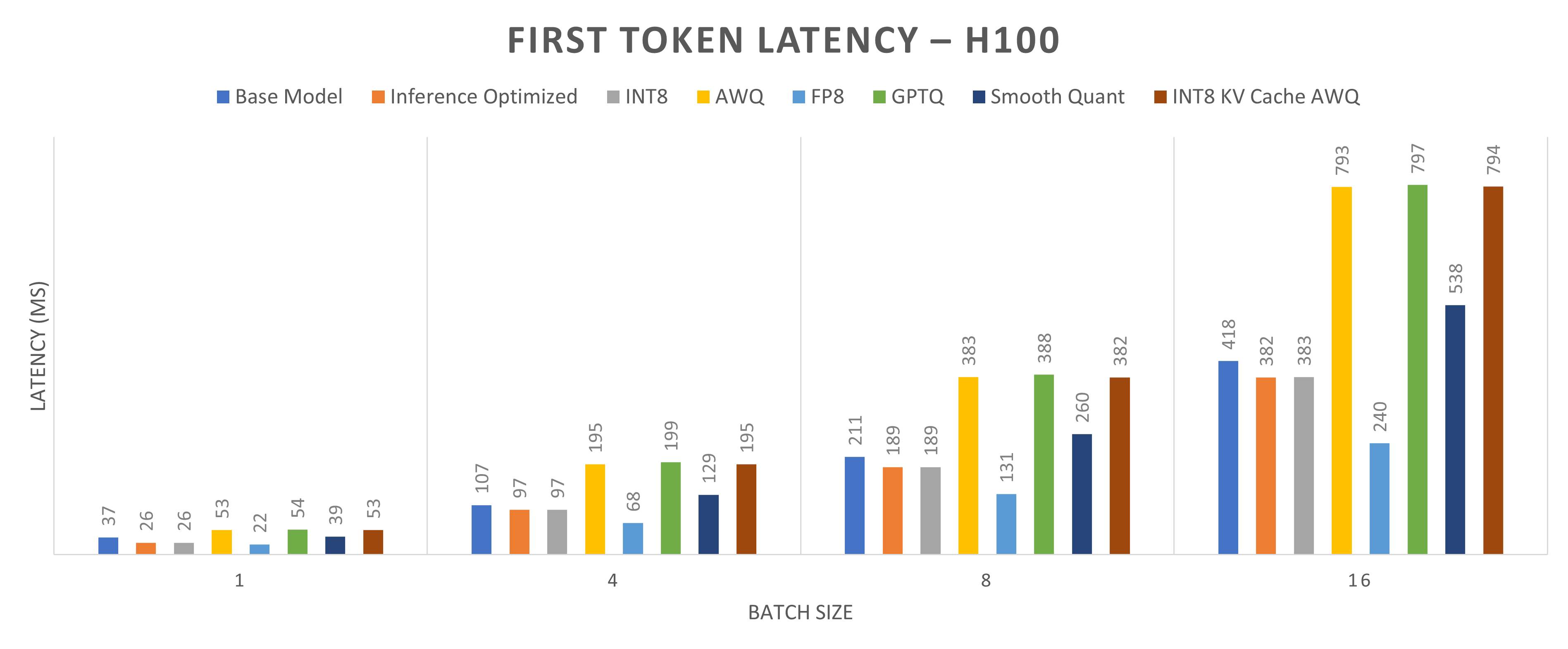
Figure 7: Time to generate first token for Llama2-13b model running on one NVIDIA H100 GPU core (lower inference latency indicates better performance)
Conclusions
Our conclusions include:
- The NVIDIA H100 GPU consistently outperforms the NVIDIA L40S GPU across all scenarios owing to its superior compute availability.
- The first token latency is higher for AWQ and GPTQ, yet their total inference time is lower, resulting in higher throughput. This result suggests that AWQ and GPTQ are memory-bound, requiring more time for memory loading than for actual inference.
- By optimizing for inference through iterative batching and quantized KV caching, throughput has improved by approximately 50 percent. We observed the most significant enhancements, a throughput improvement of 67 percent, with a batch size of 1. As batch size increases, the gains diminish slightly. For a batch size of 16, the performance gain in throughput is 44 percent. Additionally, total inference latency decreased by approximately 35 percent.
- Among all quantization methods, the most significant gains are achieved with INT8 KV cache AWQ, showing a remarkable 65 percent improvement on one NVIDIA L40S GPU and a 55 percent improvement on one NVIDA H100 GPU.