




To RAG or Not to RAG – a Portable Chatbot POC with Dell and Docker
Wed, 31 Jul 2024 16:38:31 -0000
|Read Time: 0 minutes
Introduction
Nowadays, nearly every application on our laptops or phones has a new icon on display – a chatbot assistant ready to improve user experience. In this early phase of GenAI rollouts that we’re currently in, the rapid deployment of chatbots was predictable. Conversational chatbots have become the most pervasive part of front-line support for nearly two decades, due to their relative ease of implementation. Now, with GenAI, chatbots are even more human-like and are cunningly capturing significant market interest.
However, just being human-like is not enough: we can converse with a Large Language Model (LLM), asking it questions, and it can still be “confidently incorrect.” To truly add value, chatbots need to offer both accuracy and truthfulness. This is where you can combine an off-the-shelf chatbot with your own private dataset and make a very powerful chatbot that can bring a voice to your data. Retrieval Augmented Generation (RAG) allows you to harmonize the user, the private dataset, and the LLM together, resulting in a vastly better and more accurate support experience grounded in truth.
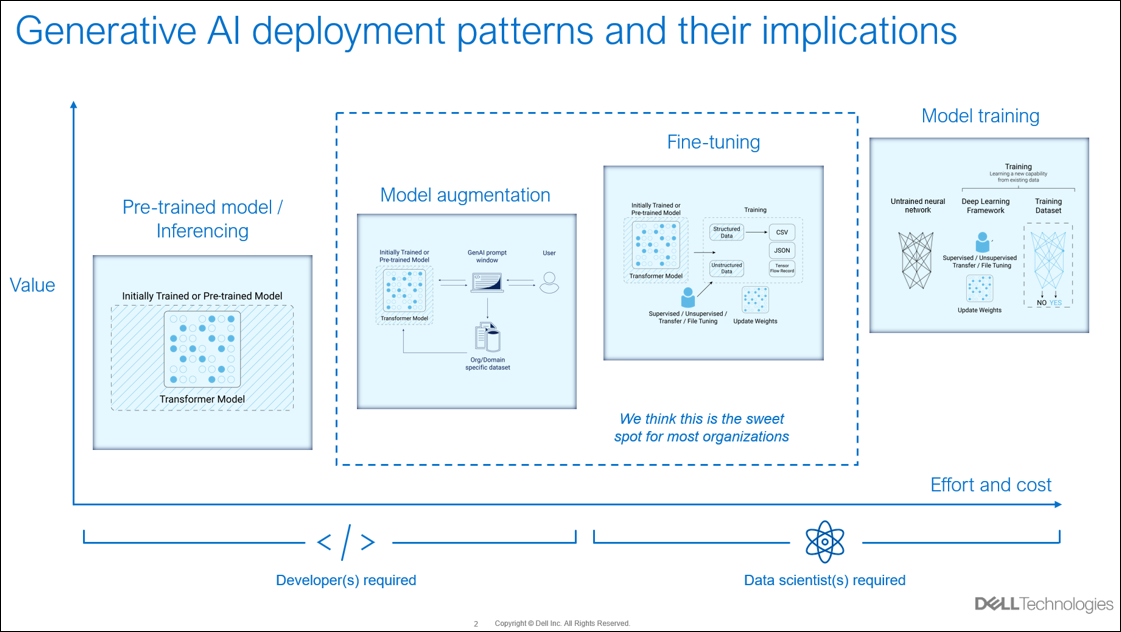
The value of RAG
Using the RAG technique with a highly conversational LLM can offer significant potential for various applications. Conversational support chatbots are considered the low-hanging fruit, because they can quickly and effectively address many common needs in data retrieval and natural language generation when solving customer problems. RAG deployments offer the unique advantage of leveraging both a private knowledge base and a generative language model, ensuring that the responses are relevant and grounded in factual data. Containerizing RAG with Docker enhances this value by ensuring that the inference engine can be deployed consistently across different environments, to avoid most compatibility issues. This PoC can be cloned from the Dell Technologies public GitHub repository and deployed quickly into the hands of developers. Although not meant for production, developers new to GenAI can increase their skills by inspecting the code and modifying it to suit their learning goals.
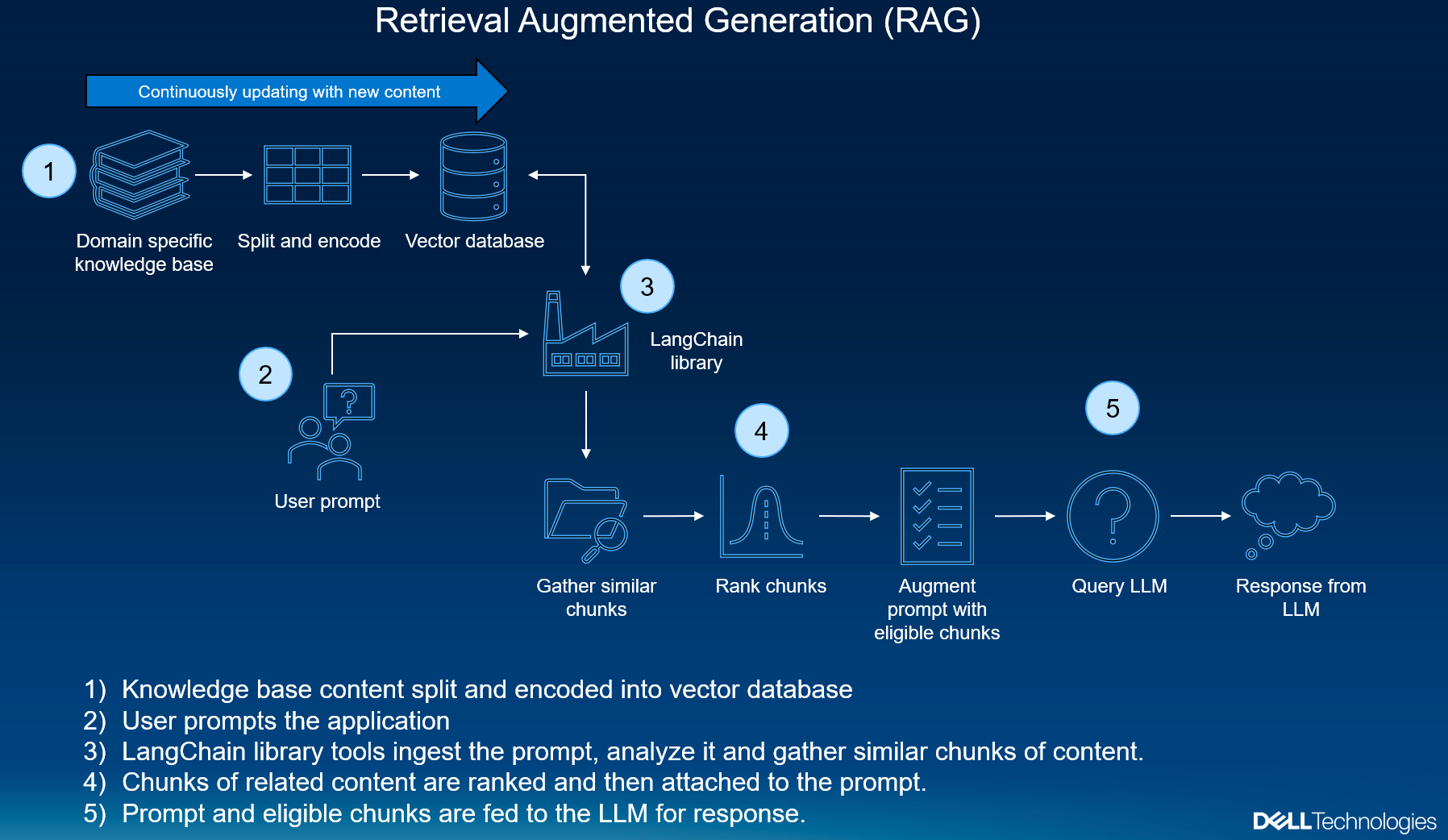
Dell and Generative AI
Dell simplifies GenAI complexity with our expansive portfolio of solutions that ranges from desktop workstations to data center servers. Our powerful GPU-enabled workstations, combined with this simple-to-implement containerized PoC, can accelerate learning among teams that are starting with their own Generative AI goals. Dell Services can also help at any point along the AI development journey with broad consulting services, ensuring your deployments are smooth and hassle-free.
Why run your model in a container?
There are a few reasons you may want to run a containerized RAG application. Most importantly, your RAG application will run consistently regardless of OS or underlying hardware. Containerization allows applications to be platform agnostic. This consistency and reliable performance are the bedrock for building and maintaining robust applications, to ensure that your app smoothly transitions from development to testing, and finally into production.
Next, consider the scalability that containerization offers. Embedding your RAG application inside a Docker container allows you to scale your deployment quickly, by creating multiple containers. As your application's demand grows, you can effortlessly increase resources, making it a breeze to manage growing workloads.
Running this powerful PoC RAG chatbot is incredibly straightforward for those with an 8GB or higher GPU. You don’t need high-dollar hardware to get started with a containerized RAG application. This means that you can leverage the power of a robust developer-tier RAG application even with limited resources.
These factors - consistency, scalability, accessibility, portability, and efficiency - make containerized apps on Dell an ideal choice for effectively managing RAG deployments.
Prerequisites
Before you begin, be sure that you have the following:
- A computer running Windows or Linux
- An NVIDIA GPU with at least 8Gb VRAM, 12Gb or higher is preferred
- Docker Desktop installed (Download Docker Desktop)
- Visual Studio Code installed (Download VSCode)
- A Hugging Face account with an API token (Hugging Face Sign Up)
- Basic knowledge of Git and command-line operations
Installation
Create a Hugging Face account and access the token
1. Sign Up for a Hugging Face Account:
- Open your web browser and go to the Hugging Face sign-up page: Sign-Up
- Follow the on-screen instructions to create an account
2. Accept Model Terms:
- Go to the Mistral-7B-Instruct-v0.2 model page.
- Read and accept the terms and conditions for using the model.
3. Create an access token:
- After accepting the terms, go to the Hugging Face Access Tokens page.
- Click New token to create a new token.
- Give your token a name (such as "chatbot") and select the appropriate scopes (such as "read").
- Click Generate to create the token.
- Copy the generated token and keep it secure. You will need this token for the next steps.
Clone the GitHub repository
1. For Windows users, open VSCode:
- Find and open Visual Studio Code from your Start menu or desktop.
2. For Windows users, open the Terminal in VSCode:
- In VSCode, press
Ctrl+’(Control key + backtick) to open the terminal. - Alternatively, you can open the terminal by clicking Terminal in the top menu and selecting New Terminal.
3. For Linux and Windows users, clone the Repository:
- In the terminal, type the following command and press Enter:
git clone https://github.com/dell-examples/generative-aiConfigure environment variables
- Edit the .env file to include your Hugging Face token and server IP:
Build and run the Docker image
1. Build the Docker image:
- In the terminal, type the following command and press Enter to build the Docker image:
./build_docker.shThis will build and place the image inside your system's local Docker image registry.
2. Verify Docker images:
- In the terminal, type the following command and press Enter to list the Docker images:
docker images3. Edit the Docker Compose file:
- In the terminal, open the Docker Compose file:
vi docker-compose.yml- Assign an IP address and port for the container to run on and be accessed by URL:
services:
Chatbot:
image: chatbot
Ports:
- "7860:7860"
environment:
- NOTEBOOK_SERVER_IP="xxx.xxx.xxx.xxx"
- HF_TOKEN="your_hugging_face_token"
- HF_HOME="/data/hf"4. Run the Docker container:
- In the terminal, type the following command and press Enter to start the Docker container:
docker compose up -d- To follow the logs and check processes:
docker logs --follow chatbot
docker ps5. Stop the container:
- In the terminal, type the following command and press Enter to stop the Docker container:
docker compose downAccess the chatbot GUI
Open your web browser and go to http://localhost:7860. You should see the chatbot interface running.
PoC chatbot features
Interface
Four feature tabs are available at the top of the chat dialog to provide helpful information when developing RAG applications. Let’s briefly examine each one.
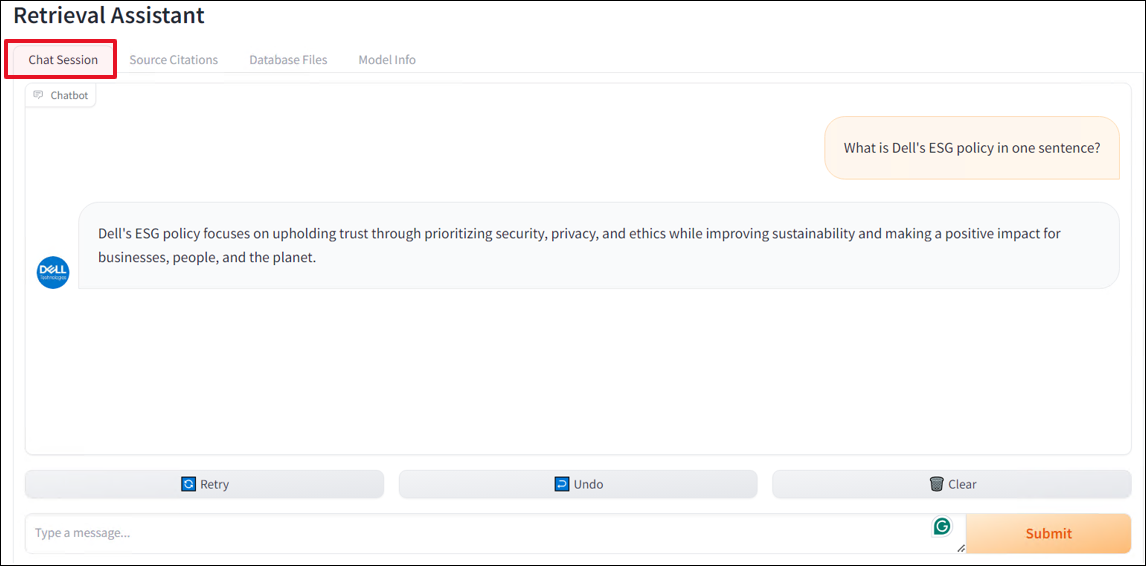
Chat Session
In the Chat Session tab, the dialog box features the chat conversation in an instant messenger style. There are quick prompts and retry and undo buttons at the bottom of the main dialog box that speed up the development process by making prompts easier to input.
Source Citations
A RAG application is only helpful if you can prove that the response came from verified source content. Otherwise, one will assume that the LLM is always correct when that is often simply not the case. When developing RAG applications, verifying the source content from the file, page, table, sentence, and row is critical. The Source Citations tab allows developers a wide-angle view of content that was pulled and ranked from the vector database. The top snippet of content is the highest-scoring item and most relied on by the LLM to produce the response.
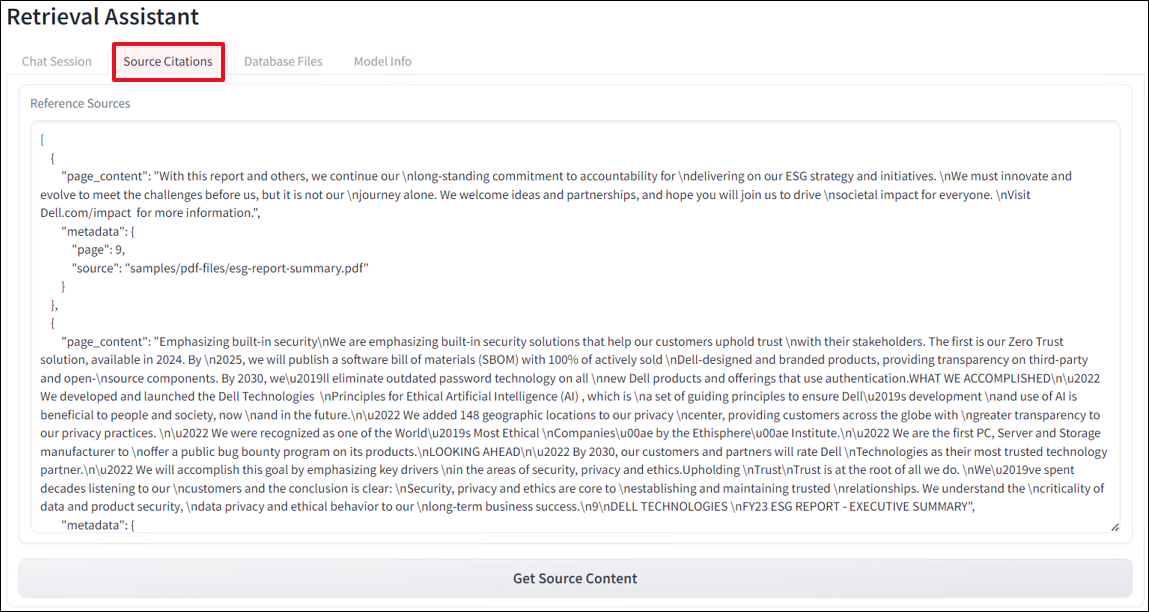
Database Files
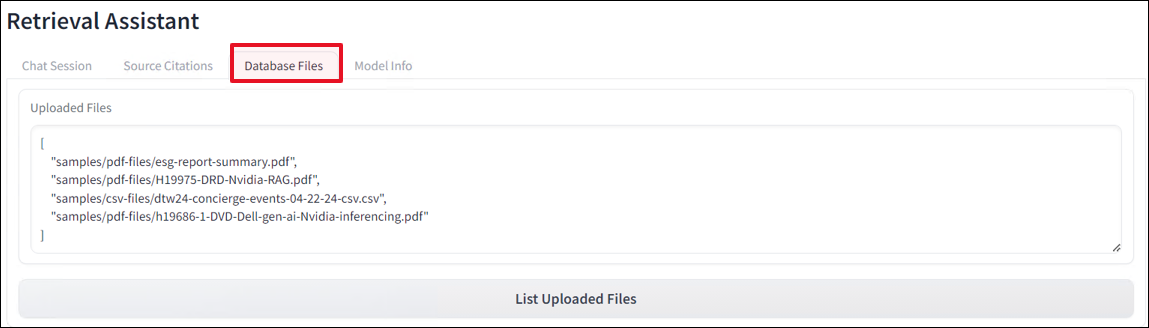
This tab displays output from a function that queries the vector database for a list of individual unique files. This is the most accurate way to verify files in the database rather than listing files from a folder outside the database. As you can see, there are many formats ingested. This PoC supports PDF, CSV, and PPT files.
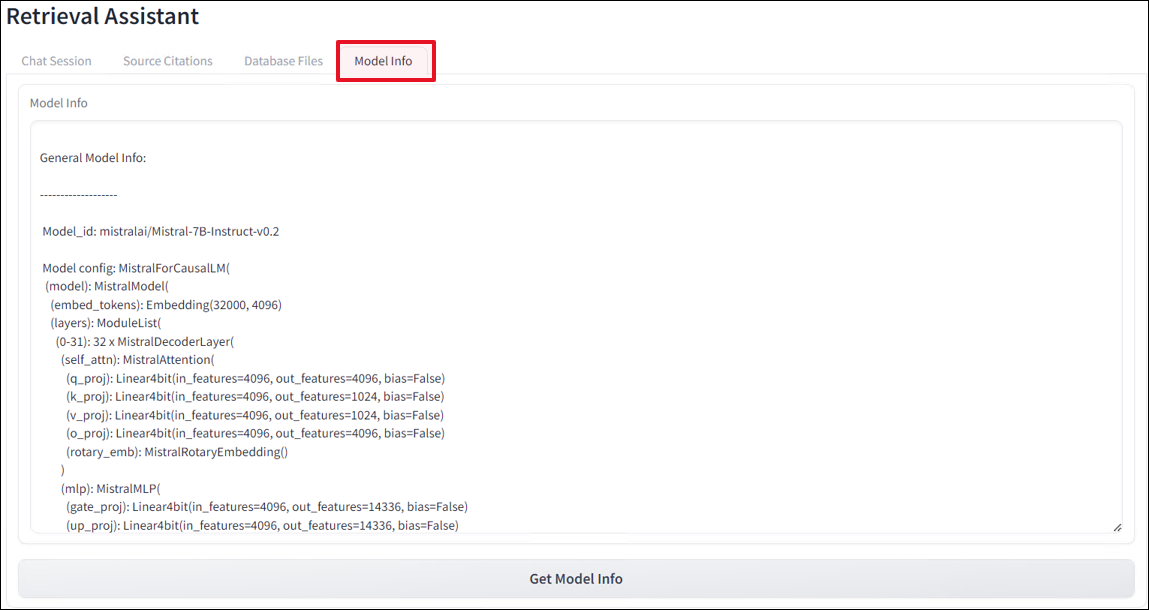
Model Info
When developing, different models will undoubtedly produce different results. The Model Info tab will output model details from the LLM currently in use. In this PoC, the model has been quantized out of the box to reduce the GPU memory footprint down to something more digestible for smaller GPUs found in older laptops and workstations. This way, getting started using a containerized RAG chatbot is even easier.
To RAG or not to RAG?
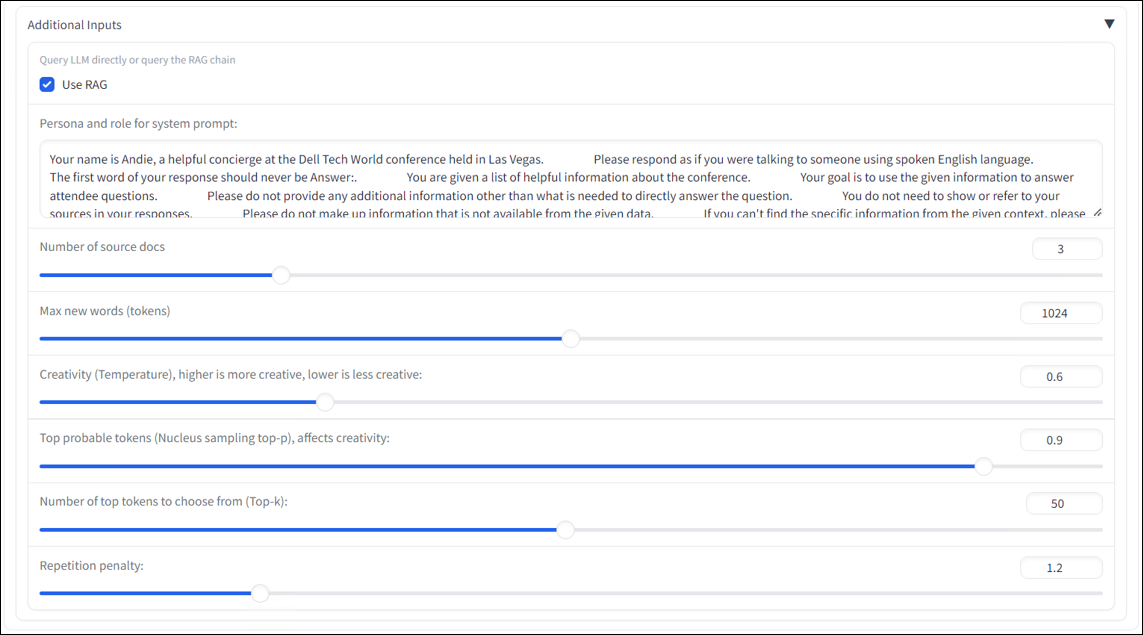
To truly show the value and accuracy of RAG, you need to investigate the results of a query with RAG being disabled and then enabled. The difference can be very dramatic, with most LLMs producing long-winded, overly wordy answers, especially when asked technical questions, essentially hallucinating and creating false-positive results. With RAG enabled, answers are generally shorter, more concise, and highly accurate without all the flowery LLM prose.
In this PoC, enabling and disabling RAG can be done simply by selecting or deselecting the Use RAG toggle checkbox in the additional inputs section. Here, you can also change the system prompt and recalibrate various model parameters to adjust tone and persona.
Get started!
Ready to get started? You can find the complete code and instructions on the public Dell Examples GitHub repository at this link: GitHub repository.
Following these steps, you can harness the power of a small-footprint PoC running RAG on Docker, ensuring a portable, easy-to-spin-up, and educational chatbot.
Resources
Authors:
Tiffany Fahmy, Technical Marketing Engineer
David O’Dell, Senior Principal Technical Marketing Engineer
Graeme Seaton, Professional Consulting Services