




Dell ECS Data Protection and Data Path Overview Part II
Fri, 23 Aug 2024 05:17:47 -0000
|Read Time: 0 minutes
Dell ECS Data Protection and Data Path Overview Part II
This is a continuation of ECS data protection and data path overview part I and I will talk about data protection and dataflow in this blog. It is recommended to review the Dell ECS Data protection and data path overview part I first to get some basic knowledge about the chunks and metadata.
Data-protection methods
Within ECS, when an object is created it includes writing data and metadata. EC metadata includes journal chunks and btree chunks. Each is written to a different logical chunk that will contain ~128 MB of data from one or more objects.
Depending on the size and type of data, data is written using one of the data protection methods shown in the following table.
Table 1: Data protection methods based on data type and size
Type of data | Data protection method used |
Journal chunks | Triple mirroring |
Btree chunks | Erasure coding with redundant data segments |
Object data <128 MB | Triple mirroring plus in-place erasure coding |
Object data >=128 MB | Inline erasure coding |
Note: In the all-flash architecture like EXF900, the btree chunks protection is triple mirroring.
Triple mirroring
The triple-mirror write method is applicable to the ECS journal chunks, of which ECS creates three replica copies. Each replica copy is written to a single disk on different nodes. This method protects the chunk data against two-node or two-disk failures.
Erasure coding with redundant data segments
The erasure coding with redundant data segments write method is applicable to ECS btree chunks. It includes 12 data segments, 12 replicated data segments, and 4 parity segments. The new btree chunk-redundant data EC scheme saves metadata protection overhead.
Triple mirroring plus in-place erasure coding
This write method is applicable to the data from any object that is less than 128 MB in size.
As an object is created, it is written as follows:
- One copy is written in fragments that are spread across different nodes and disks.
- A second replica copy of the chunk is written to a single disk on a node.
- A third replica copy of the chunk is written to a single disk on a different node.
- Other objects are written to the same chunk until it contains ~128 MB of data. The erasure coding scheme calculates coding (parity) fragments for the chunk and writes these fragments to different disks.
- The second and third replica copies are deleted from disk.
- After this sequence is complete, the chunk is protected by erasure coding.
The diagram shown below may help you understand the triple mirroring plus in-place erasure coding process better from the description.
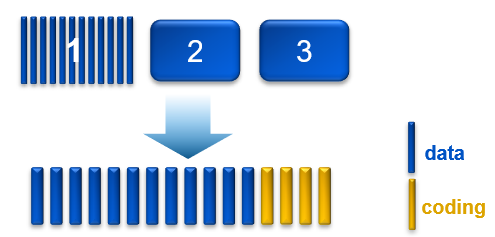
Inline erasure coding
This write method is applicable to the data from any object that is 128 MB or larger. Objects are broken up into 128 MB chunks. The Reed Solomon erasure coding scheme calculates coding (parity) fragments for each chunk. Each fragment is written to different disks across the nodes.
- If the erasure coding scheme is the default (12+4), the fragments are spread across 16 disks, each fragment being ~10.67 MB.
- If the erasure coding scheme is cold storage (10+2), the fragments are spread across 12 disks, each fragment being ~ 12.8 MB.
Any remaining portion of an object that is less than 128 MB is written using the triple mirroring plus in-place erasure coding scheme. As an example, if an object is 150 MB, 128 MB is written using inline erasure coding. The remaining 22 MB is written using triple mirroring plus in-place erasure coding.
Checksums
Checksums are done per write-unit, up to 2 MB. During write operations, the checksum is calculated in memory and then written to disk. On reads, data is read along with the checksum. The checksum is then calculated in memory from the data read and compared with the checksum stored in disk to determine data integrity. Also, the storage engine runs a consistency checker periodically in the background and does checksum verification over the entire dataset.
Data flow
ECS was designed as a distributed architecture, allowing any node in a VDC/site to respond to a read or write request. A write request involves writing the object data and object metadata(system/custom), and recording the transaction in a journal log. Once this activity is complete, an acknowledgment is sent to the client.
The following figure and steps provide a high-level overview of a write dataflow.
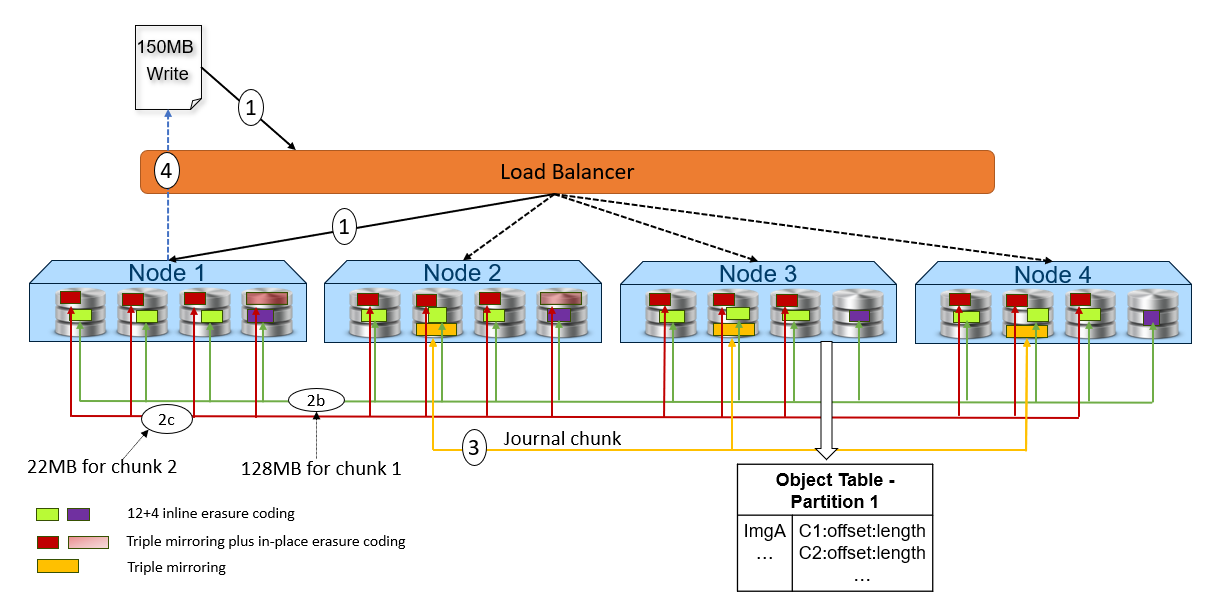
- A write object request is received, any node can respond to this request, In this example, Node 1 processes the request.
- Depending on the size of the object, the data is written to one or more chunks. Each chunk is protected using advanced data protection schemes such as triple mirroring plus in-place erasure coding and inline erasure coding. Before writing the data to disk, ECS runs a checksum function and stores the result.
- In this example, the object size is 150MB, it will be divided 128MB as chunk 1 and 22MB as chunk 2.
- For the chunk 1 with 128MB size, it uses the inline erasure coding scheme (12+4).
- For the chunk 2 with 22MB size, it uses the triple mirroring plus in-place erasure coding scheme.
- After the object data is written successfully, the object metadata will be stored. In this example, Node 3 owns the partition of the object table in which this object belongs. As owner, Node 3 writes the object name and chunk ID to this partition of the object table’s journal logs. Journal logs are triple mirrored, so Node 3 sends replica copies to three different nodes in parallel—Node 2, Node 3, and Node 4 in this example.
- Acknowledgment is sent to the client.
- In a background process, the memory table is updated.
- Once the table in memory becomes full or after a set period of time, the table is merged, sorted, or dumped in B+ trees as chunks. Then, a checkpoint is recorded in the journal.
A read request finds the physical location of the data using table lookups from the partition record owner. The request includes byte offset reads, checksum validation, and return of the data to the requesting client.
The following figure and steps provide a high-level overview of a read dataflow.
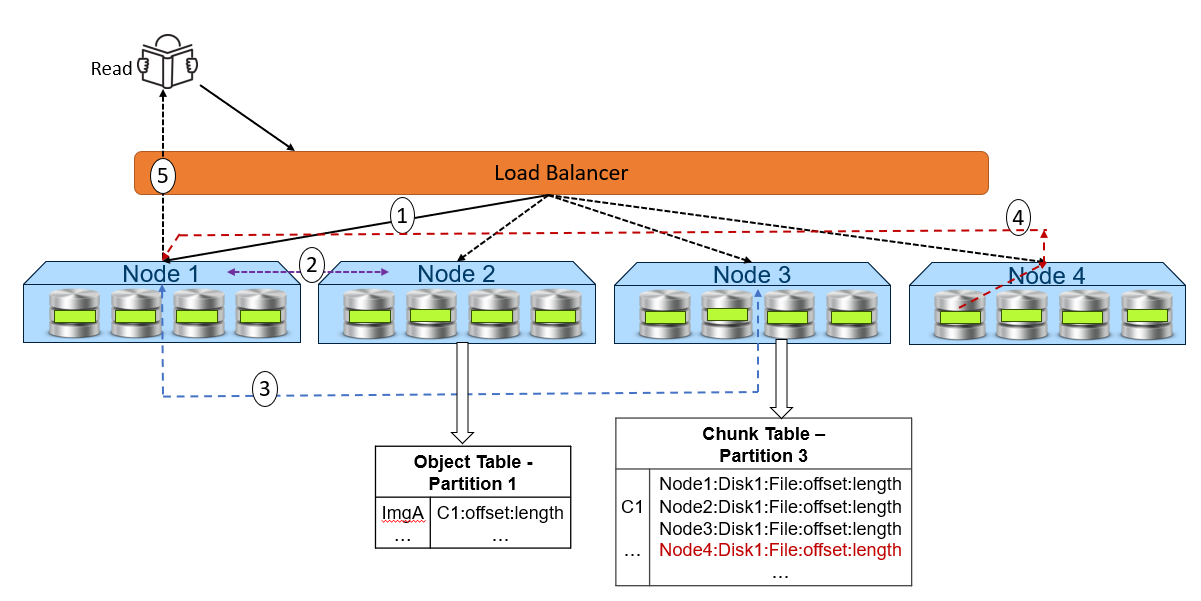
- A read request is received for ImgA. In this example, Node 1 processes the request.
- Node 1 requests the chunk information from Node 2 (object table partition owner for ImgA).
- Knowing that ImgA is in C1 at a particular offset and length, Node 1 requests the chunk’s physical location from Node 3 (chunk table partition owner for C1).
- Now that Node 1 knows the physical location of ImgA, it requests that data from the node or nodes that contain the data fragment. In this example, the location is Node 4 Disk 1. Then, Node 4 performs a byte offset read and returns the data to Node 1.
- Node 1 validates the checksum which together with the data payload and returns the data to the requesting client.
Note: In step 4, for all-flash architecture like EXF900, each node can directly read data from the other node. This architecture contrasts with a hard-drive architecture like the EX300, EX500, and EX3000 in which each node can only read the data store in itself.
Resources
The following Dell Technologies documentation provides additional information related to this blog. Access to these documents depends on an individual’s login credentials. For access to a document, contact a Dell Technologies representative.
- Dell ECS Architecture and Overview white papers
- Dell ECS Data Protection and Data Path Overview Part I