
None
None
-
Figure 2 shows the network architecture. It shows the network connectivity for the PowerEdge training nodes, PowerScale storage, and the three control plane nodes that incorporate NVIDIA Base Command Manager Essentials and other software components.
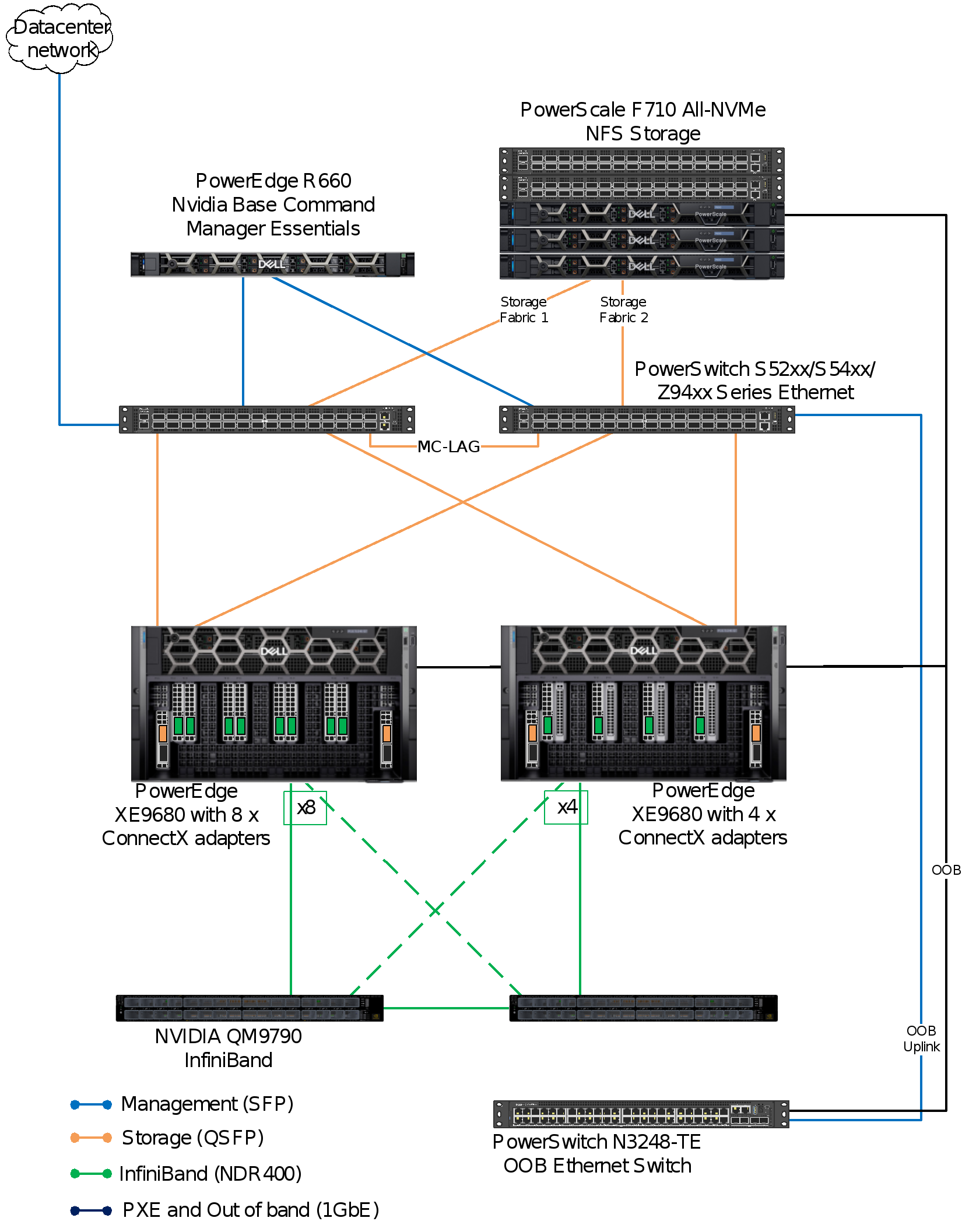
Figure 2. Networking design showing two options for XE9680 connectivity
In this reference design, we evaluated two network configurations. The first setup equipped each XE9680 with 8 NVIDIA ConnectX-7 SmartNIC network adapters, ensuring a dedicated network port for each GPU. In contrast, the second setup featured 4 NVIDIA ConnectX-7 SmartNIC network adapters per XE9680. Our objective was to validate both configurations by measuring their training times. This comparison aims to provide readers with the data necessary to choose the most suitable configuration for their needs.
Our network design accommodates a minimum of eight PowerEdge XE9680 servers, each equipped with 8 NVIDIA Connect-X 7 adapters. When deploying eight servers, we establish 32 inter-switch links to guarantee unblocked communication on two 64 port QM970.
Rail-optimized network architecture
LLM training often necessitates clusters significantly larger than 8 nodes. When scaling beyond eight servers, the network architecture must be carefully considered. In the PowerEdge XE9680 model, each NVIDIA GPU can be equipped with a dedicated InfiniBand network adapter, enabling communication with GPUs in other servers. This communication, facilitated by GPUDirect RDMA, doesn’t interrupt the CPU, thereby reducing latency. Collective communications are crucial for the performance of modern distributed LLM training. The NVIDIA Collective Communication Library (NCCL), part of the Magnum IO Library, implements GPU-accelerated collective operations like all-gather and all-reduce. NCCL is aware of the network topology and is optimized to achieve high bandwidth and low latency over various interconnects, including PCIe, NVLink, and InfiniBand.
A new feature, known as PXN (PCI × NVLink), was introduced in NCCL 2.12. This feature allows a GPU to communicate with a NIC on the node via NVLink and then PCI, bypassing the CPU and avoiding the use of QPI or other inter-CPU protocols, which can’t deliver full bandwidth. As a result, each GPU can access other NICs as needed, even though it primarily uses its local NIC.
Considering this, a rail optimized network architecture is recommended for large cluster designed for LLM training. This architecture consists of leaf-spine network switches as shown in the figure.
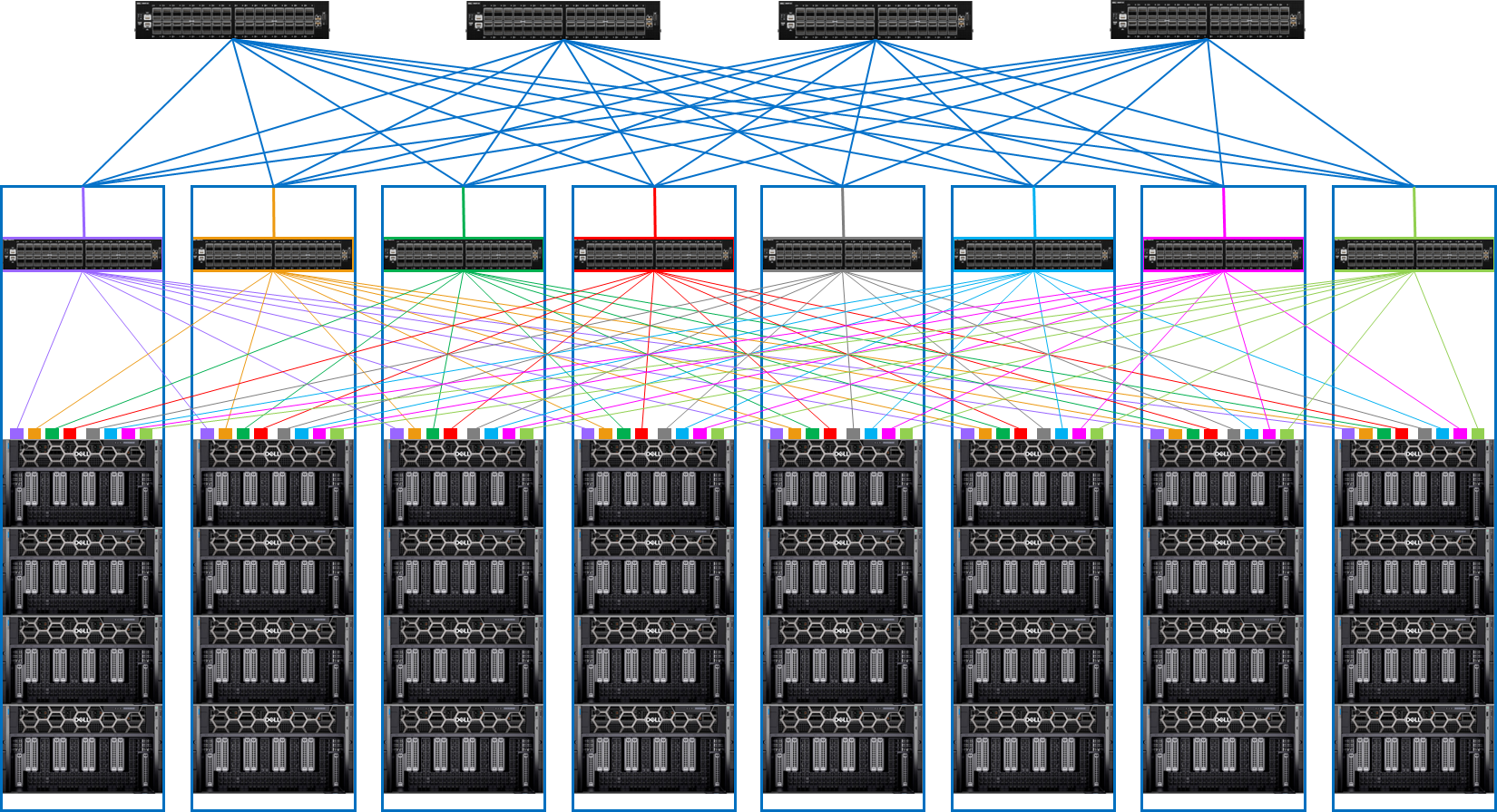
Figure 3. Rail optimized network architecture for distributed LLM training
The rail-optimized network architecture consists of the following design elements:
- Each of the eight pods houses 4 PowerEdge XE9680 servers and one PowerSwitch Z9664F-ON, which functions as a spine switch.
- Each of PowerEdge XE9680 server is equipped with 8 InfiniBand network adapters (NVIDIA Connect-X 7) that connect to the PowerSwitch Z9664F-ON spine switch.
- Each PowerSwitch Z9664F-ON spine switch has 64 ports. Half of these ports (32) connect to the PowerEdge XE9680 servers, while the remaining half connect to 4 x PowerSwitch Z9664F-ON leaf switches.
- Each leaf switch is connected to each spine switch using 8 links. This setup results in a 1:1 subscription ratio between the server to the leaf switches and leaf to spine switches.