
Using SmartPools to improve performance
Using SmartPools to improve performance
-
One of the principal goals of storage tiering is to reduce data storage costs without compromising data protection or access. SmartPools can be used to improve performance in several ways:
- Location-based performance improvements
- Performance settings
- SSD strategies
- Performance isolation
Location-based performance uses SmartPools file pool policies to classify and direct data to the most appropriate media (SSD, SAS, or SATA) for its performance requirements.
In addition, SmartPools file pool rules also allow data to be optimized for both performance and protection.
As we have seen, SSDs can also be employed in various ways, accelerating combinations of data, metadata read and write, and metadata read performance on other tiers.
Another application of location-based performance is for performance isolation goals. Using SmartPools, a specific node pool can be isolated from all but the highest performance data. File pool policies can be used to direct all but the most critical data away from this node pool. This approach is sometimes used to isolate only a few nodes of a certain type out of the cluster for intense work. Because node pools are easily configurable, a larger node pool can be split, and one of the resulting node pools isolated and used to meet a temporary requirement. Then, split pools can be reconfigured back into a larger node pool.
For example, the administrators of this cluster are meeting a temporary need to provide higher performance support for a specific application for a limited time period. They have split their highest performance tier and set policies to migrate all data not related to their project to other node pools. The servers running their critical application have direct access to the isolated node pool. A default policy has been set to ensure all other data in the environment is not placed on the isolated node pool. In this way, the new node pool is completely available to the critical application.
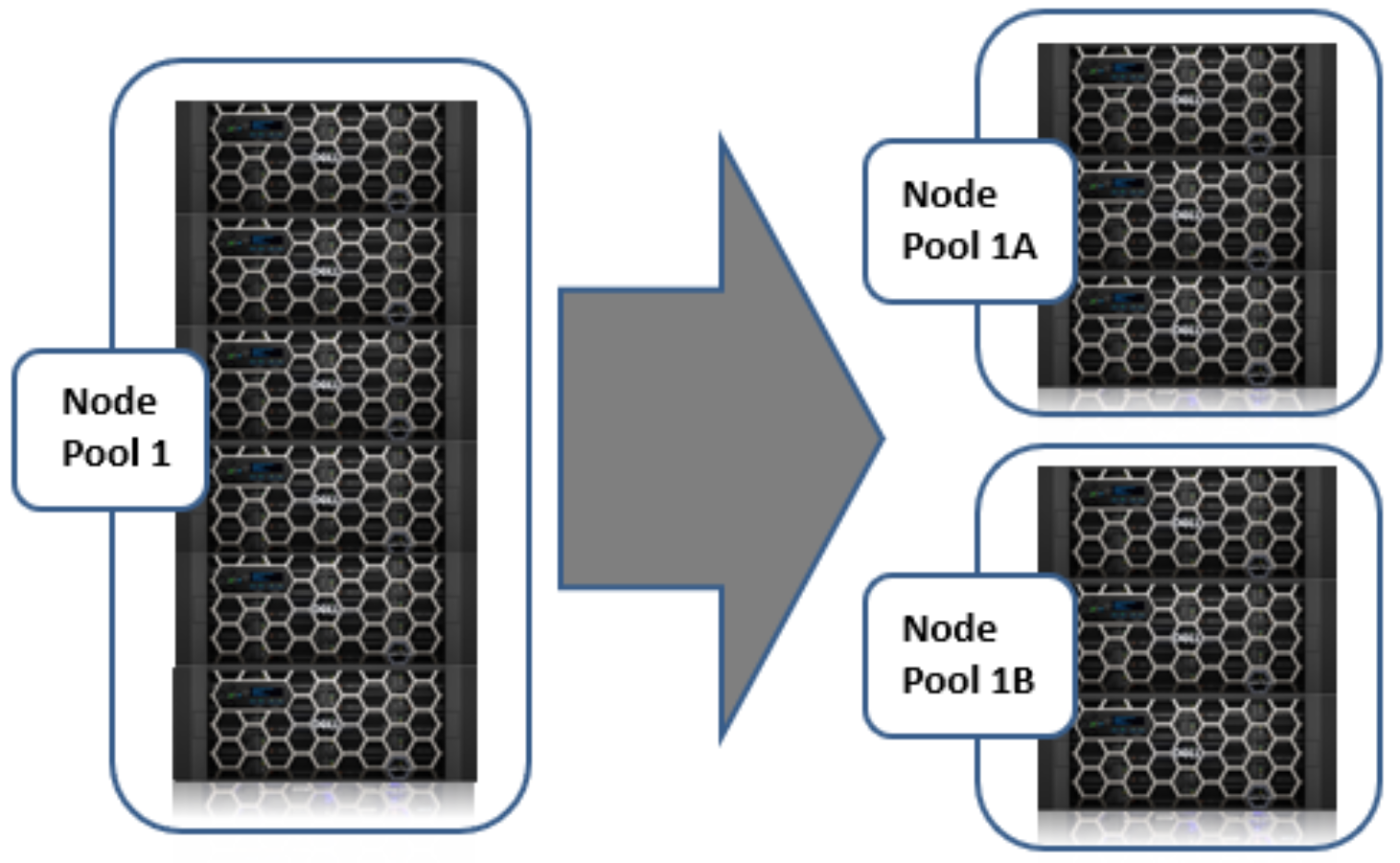
Figure 21. Performance isolation example