
Node pools
Node pools
-
Node pools are groups of disk pools, spread across similar storage nodes (equivalence classes), as illustrated in Figure 7. Multiple groups of different node types can work together in a single, heterogeneous cluster. For example:
- One node pool of all-flash F-Series nodes for IOPS-intensive applications
- One node pool of H-Series nodes, primarily used for high-concurrent and sequential workloads
- One node pool of A-Series nodes, primarily used for nearline and deep archive workloads
Node pools allow OneFS to present a single storage resource pool consisting of multiple drive media types: NVMe, SSD, high-speed SAS, and large capacity SATA. They provide a range of different performance, protection, and capacity characteristics. This heterogeneous storage pool in turn can support a diverse range of applications and workload requirements with a single, unified point of management. It also facilitates the mixing of older and newer hardware, allowing for simple investment protection even across product generations, and seamless hardware refreshes.
Each node pool contains only disk pools from the same type of storage nodes, and a disk pool may only belong to one node pool. For example, all-flash F-Series nodes would be in one node pool, whereas A-Series nodes with high capacity SATA drives would be in another. Today, a minimum of four nodes, or one chassis, are required per node pool for Gen6 modular chassis-based hardware, or three previous generations of PowerScale nodes per node pool.
Nodes are not provisioned (not associated with each other and not writable) until at least three nodes from the same compatibility class are assigned in a node pool. If nodes are removed from a node pool, that pool becomes under-provisioned. In this situation, if two like nodes remain, they are still writable. If only one remains, it is automatically set to read-only.
Once node pools are created, they can be easily modified to adapt to changing requirements. Individual nodes can be reassigned from one node pool to another. Node pool associations can also be discarded, releasing member nodes so they can be added to new or existing pools. Node pools can also be renamed at any time without changing any other settings in the node pool configuration.
Any new node added to a cluster is automatically allocated to a node pool and then subdivided into disk pools without any additional configuration steps. The node inherits the SmartPools configuration properties of that node pool. Thus, the configuration of disk pool data protection, layout, and cache settings must be completed only once per node pool. Configuration can be done at the time the node pool is first created. The shared attributes of the new nodes with the closest matching node pool determine the automatic allocation. If the new node is not a close match to the nodes of any existing node pool, it remains unprovisioned until the minimum node pool node membership for like nodes is met. That minimum is three nodes of the same or similar storage and memory configuration.
When a new node pool is created, and nodes are added, SmartPools associates those nodes with an ID. This ID is also used in file pool policies and file attributes to dictate file placement within a specific disk pool.
By default, a file that a specific file pool policy does not cover goes to the default node pool or pools identified during setup. If no default is specified, SmartPools writes that data to the pool with the most available capacity.
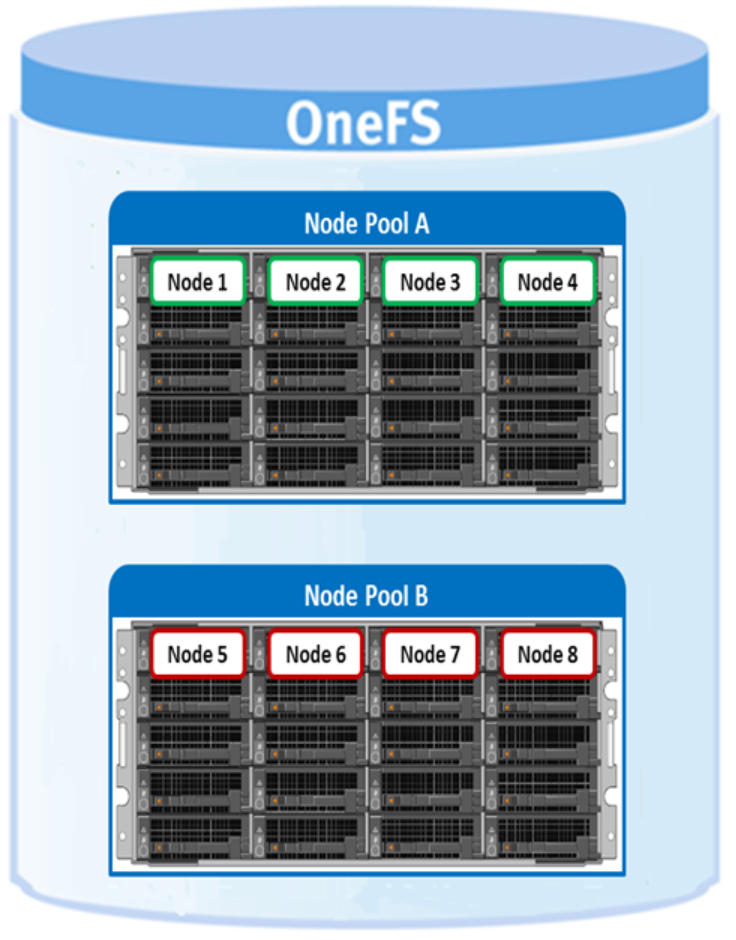
Figure 7. Automatic provisioning into node pools