
File pools
File pools
-
File pools make up the SmartPools logic layer. User-configurable file pool policies govern where data is placed, protected, and accessed, and how it moves among the node pools and tiers. Conceptually, file pools tiering is similar to storage information life cycle management (ILM) but do not involve file stubbing or other file system modifications. File pools allow data to be automatically moved from one type of storage to another within a single cluster to meet performance, space, cost, or other requirements. The data retains its data protection settings. For example, a file pool policy might dictate that anything written to path /ifs/foo goes to the H-Series nodes in node pool 1. Then, that data moves to the A-Series nodes in node pool 3 when the data is older than 30 days.
To simplify management, defaults are in place for node pool and file pool settings that handle basic data placement, movement, protection, and performance. All these settings can also be configured through the simple and intuitive WebUI, delivering deep granularity of control. Also provided are customizable template policies that are optimized for archiving, extra protection, performance, and VMware files.
When a SmartPools job runs, the data could be moved, undergo a protection or layout change, and so on. There are no stubs. Because the file system itself is doing the work, no transparency or data access risks apply.
Data movement is parallelized, using the resources of multiple nodes for speedy job completion. While a job is in progress, all data is available to users and applications.
The performance of different nodes can also be increased with the addition of system cache or solid state drives (SSDs). A OneFS cluster can use up to 181 TB of globally coherent cache. Within a file pool, SSD strategies can be configured to place a copy of that pool’s metadata, or even some of its data, on SSDs in that pool.
Overall system performance impact can be configured to suit the peaks and lulls of an environment’s workload. Change the time or frequency of any SmartPools job, and the quantity of resources allocated to SmartPools. For extremely high-utilization environments, a sample file pool policy can be used to match SmartPools run times to nonpeak computing hours. While resources required to run SmartPools jobs are low and the defaults work for most environments, that extra control can be beneficial when system resources are heavily used.
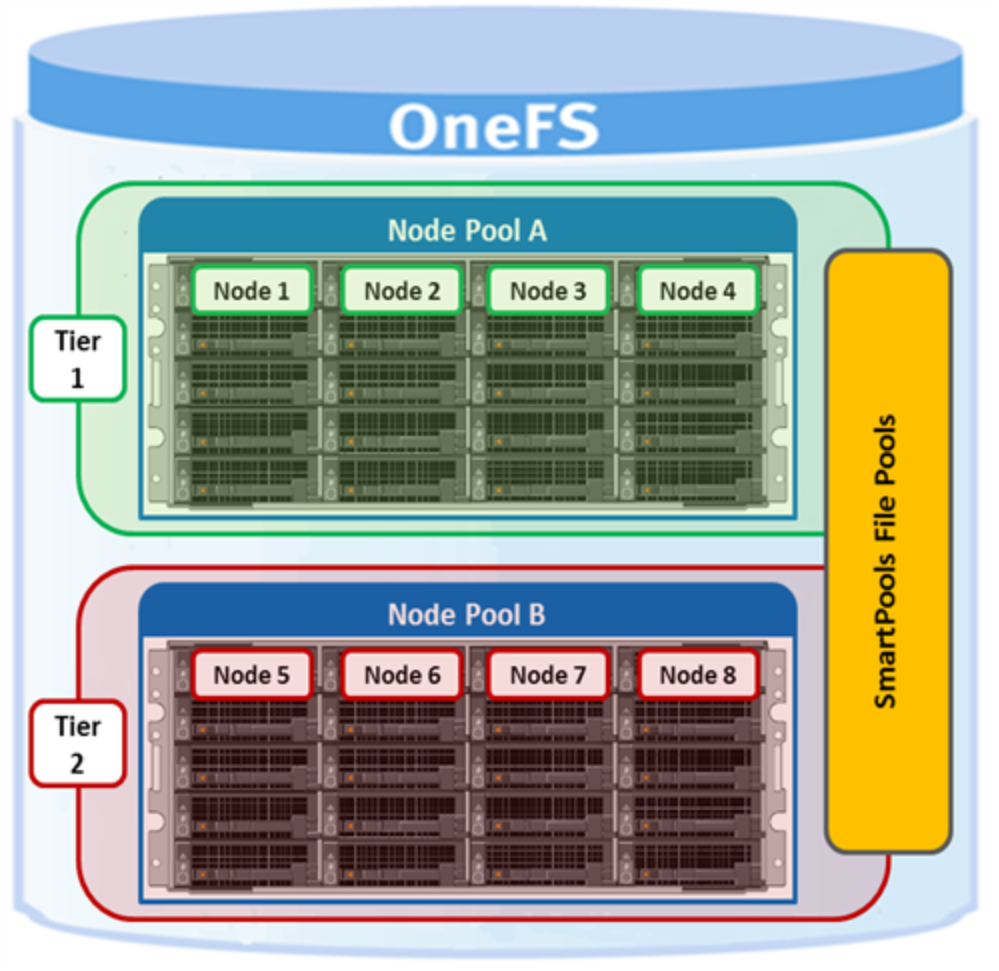
Figure 11. SmartPools file pool policy engine