
Experiment 3
Experiment 3
-
Building on insights from Experiment 1 and Experiment 2, Experiment 3 introduced substantial changes to refine the label classification process: refining T1 labels into more detailed T2 labels or introducing new labels at the T2 level. For the T2 agent to determine whether a T1 label should be expanded, the agent required access to potential T3 labels. For instance, for the symptom "random bluescreen issues" labeled as [bluescreen], the T2 agent assessed whether to choose from T2 labels such as [bluescreen]-[after osri], [bluescreen]-[inside of os], or [bluescreen]-[on boot]. The presence of a T3 label such as [bluescreen]-[inside of os]-[intermittent] indicated that [bluescreen]-[inside of os] was the most appropriate expansion for this symptom. This process highlighted the need to access a comprehensive view of potential labels across tiers, prompting the development of a mechanism that retrieves the best candidate T1, T2, and T3 labels through semantic embedding-based searches.
The following figure shows the Experiment 3 workflow:
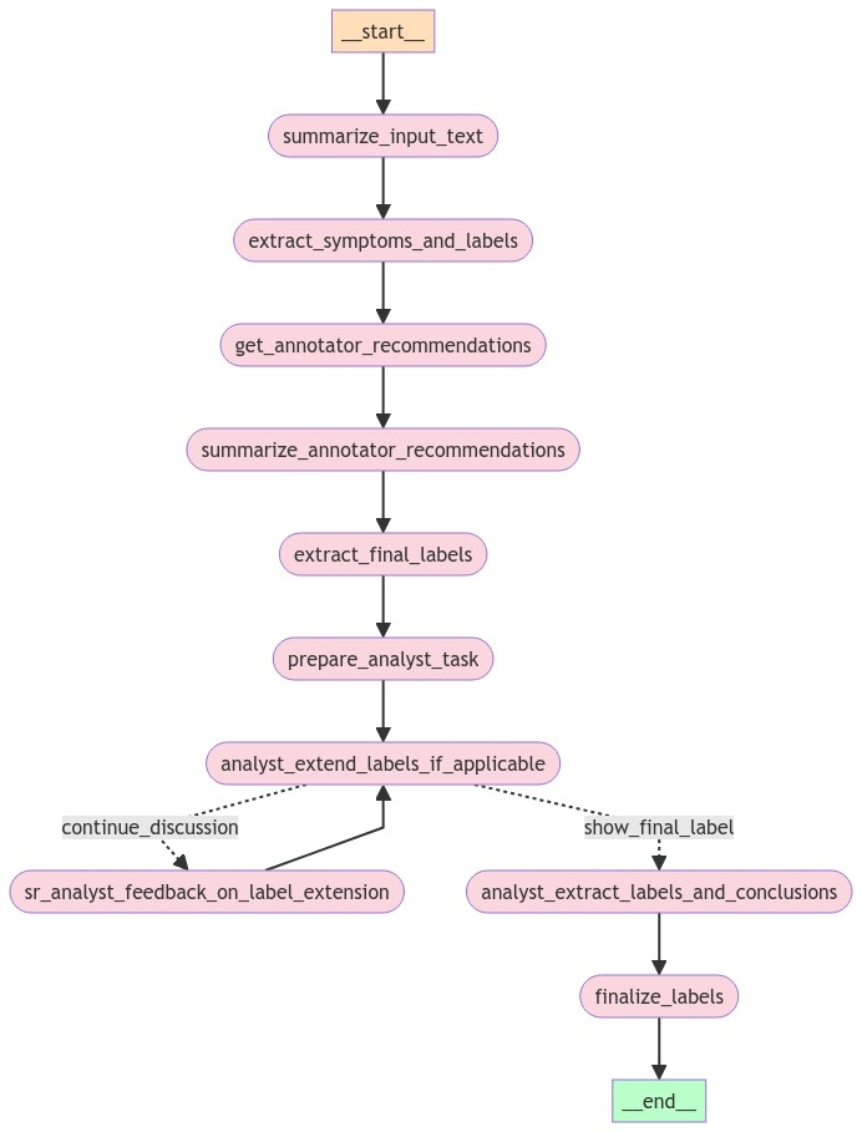
Figure 3. Experiment 3 agent workflow
To streamline the process, the team developed a series of tools using semantic embedding-based search to retrieve candidate labels across T1, T2, and T3 levels. These tools were designed to:
- Retrieve the top five most similar T1 labels for a given symptom—Tool #1
- Based on a T1 or T1-T2 label, retrieve the top five labels corresponding to the symptom across T1-T2 or T1-T2-T3 levels; that is, retrieve T1-T2 with a given T1 as a prefix or retrieve T1-T2-T3 with T1-T2 as a prefix—Tool #2
- Identify T3 label components; that is, only level 3 text of a T1-T2-T3 label that matches the symptom—Tool #3
- Obtain the top N T1-T2-T3 labels for a given symptom—Tool #4
Step 1: Text Summarization
During evaluations of the workflows using case note data, the team encountered an issue with lengthy texts that exceeded the context capacity of the models, particularly those with a maximum context size of less than 128,000 tokens. To address this challenge, the team incorporated a text summarization step into the agentic workflow: summarize_input_text step in Figure 3. If the length of the text exceeded a predetermined threshold, a computational linguist role using the phi3:3.8b-mini-128k-instruct-q8 model was tasked with summarizing the text. The model was chosen for its ability to handle large contexts, encompassing lengthy text blocks such as email threads. The summarization aimed to condense the text to no more than 200 words, ensuring that it focused on the essential elements of a given text, namely key symptoms and customer inquiries. Special attention was given to the expanding acronyms and abbreviations to maintain clarity and relevance. The team provided the model with a large number of terminology mappings in the same prompt for this purpose. The terminology mappings were acronyms or abbreviations and their expanded forms. Further, the summarization prompt was designed to exclude any personal information, such as names, signatures, email addresses, and physical addresses, unless these details were pertinent to resolving the customer's issue.
The model generally adhered well to the summarization guidelines, effectively extracting essential information from extensive customer email messages and making the data more manageable for subsequent steps. However, instances of hallucination occurred, when the model generated summaries that were completely unrelated to the original text, especially with texts at the upper limits of length and complexity. Despite these challenges, the summarization process proved largely successful in streamlining data processing for our experimental workflow.
Step 2: Retrieval of Candidate T1, T2, and T3 Labels
The team used the T1 agent developed in Experiment 2, with the summarized text when relevant, to extract symptoms and determine the most appropriate T1 labels. Recognizing the dependency of T1-T2 and T1-T2-T3 label retrieval processes on the initial T1 labels, the team introduced an additional retrieval step leveraging Tool 1. In this step, for each symptom, the three most similar T1 labels are retrieved. To streamline the process, any duplicated T1 labels resulting from the T1 agent's workflow and semantic retrieval are removed. This was achieved by merging the labels that are retrieved directly from the T1 agent with those obtained through Tool 1, prioritizing the T1 agent’s labels, and ensuring that no more than three T1 labels were finalized for each symptom.
Following the consolidation of T1 labels, for each symptom and its best-matched T1 label, the second information retrieval tool, Tool 2, was employed to retrieve the top three T1-T2 label combinations, using the identified T1 label as a prefix. The same tool retrieved the top three T1-T2-T3 labels for each T1-T2 combination, effectively managing to secure a maximum of three T1-T2 labels and nine T1-T2-T3 labels for each symptom and T1 label combination. This comprehensive retrieval ensured that the subsequent steps had a robust set of candidate labels from which to identify and classify the most appropriate labels across all levels. This process corresponds to the extract_symptoms_and_labels step in Figure 3.
This layered approach to label retrieval not only optimized the accuracy and efficiency of the candidate label retrieval process, but also minimized the risk of omitting relevant labels.
Step 3: Parallel Text Classification Using SLM
Continuing the workflow enhancement for technical support text classification, an SLM is assigned the role of a human text annotator. The task is to classify each extracted symptom or customer request by selecting the most appropriate label or labels from the provided candidates. This selection process focuses on capturing the detail level of the extracted symptoms without making assumptions about underlying causes or results. If no suitable labels are available, the SLM is instructed to clearly indicate the absence of applicable labels. This process corresponds to the get_annotator_recommendations step in Figure 3.
To facilitate this classification, a Chain-of-Thought prompting technique is employed, which aids the SLM in navigating through the T1, T2, and T3 labels. By addressing all relevant label levels and the most applicable labels at the symptom level, the SLM is better equipped to determine the most fitting label. This approach not only enhances the precision of the classification, but also aligns with the detailed hierarchical structure that is required for accurate technical support analysis.
Given the generative and stochastic nature of SLMs, these models have a propensity for producing inconsistent results. To mitigate this issue and enhance the accuracy of the classifications, the team adopted the "self-consistency" prompting technique, requiring parallel running of the same prompt three times. This technique effectively replicates the process of three independent annotators evaluating the same symptom with the available labels. The redundancy ensures that the resulting classifications are robust and consistent across multiple interpretations.
For this critical task, the team selected a cloud-based llama-3-8b-instruct model. This choice was driven by the need for high computational power and efficiency to handle the complexity of the tasks without compromising inference time. The SLM's responses are not restricted to a specific format, allowing it to generate responses in a freeform manner. This flexibility enables the model to use its generative capabilities fully, although it introduces challenges in maintaining response consistency.
The implementation of the "self-consistency" prompting technique significantly improved both the consistency and the quality of the SLM's responses. However, despite instructions to avoid proposing new labels at this stage, the SLM occasionally introduced new labels, probably because of its inherent generative nature. This observation underscores the need for robust label validation mechanisms. By incorporating subsequent validation steps and providing targeted feedback to the annotator role, it is possible to further minimize inaccuracies and ensure that the classification aligns closely with the established label taxonomy.
This step proved to be essential in refining the label classification process, ensuring that each customer issue is categorized with the highest accuracy and relevancy while enhancing the overall effectiveness of our technical support system.
Step 4: Review Consolidation and Label Determination
Step 4, summarize_annotator_recommendations in Figure 3, consolidates individual responses from three annotators into a new prompt along with the extracted symptom. The primary task is to identify the best label after a thorough review of all responses, taking account of the majority consensus while allowing the model to exercise its own judgment based on the comprehensive analysis of the three reviews. This process effectively integrates various perspectives to determine the most accurate label or labels for classifying a symptom accurately. For this step, the team employed the llama-3-8b-instruct model.
The use of parallel calls to the SLM to run prompts, followed by a summarization, comparison, or majority voting mechanism, has proven to be a valuable pattern within agentic workflows. This approach significantly enhances the consistency and accuracy of responses, suggesting its potential applicability across similar tasks requiring high precision in response-generation and decision-making processes.
Step 5: Final Analysis and Label Extraction
Step 5, extract_final_labels in Figure 3, uses a prompt to analyze the consolidated review from Step 4, aiming to extract the final label or labels as identified. The phi3:latest model is deployed for this purpose.
Step 6: Preparation for Label Analysis and Decision-Making
The role of the Data Analyst is to analyze the current best labels resulting from Step 5 to determine the necessity of introducing a new label. The best labels include the symptoms and input text such as case notes, This step involves preparing the analyst’s task parameters by using Tool 3 and Tool 4, as described in Experiment 3, to retrieve the top N T1-T2-T3 labels and the top N T3 label components for a given symptom.
For this purpose, the following information is compiled to be ready for use in Step 7: Top 7 T1-T2-T3 labels, top 5 Tier 3 (T3) label components, Input Text, Symptom, and Current (best) labels. This process corresponds to the prepare_analyst_task in Figure 3.
The Tier 3 label components are used primarily to maintain the consistency of any newly proposed T3 labels. Simultaneously, the T1-T2-T3 labels aid in the decision-making process by providing insights into whether it is necessary to create new labels if matching labels across T1-T2-T3 already exist.
Step 7: Role Play for Label Extension Analysis
A role play is conducted between a Data Analyst—the analyst_extend_labels_if_applicable step in Figure 3—and a Senior Data Analyst—the sr_analyst_feedback_on_label_extension step in Figure 3—to discuss the potential extension of the current label: T1 or a combination of T1 and T2 (T1-T2). The Data Analyst reviews the task parameters that are prepared in Step 6 to determine if the current best label, T1 or T1-T2, can be extended to the next level, such as T1 to T1-T2 or T1-T2 to T1-T2-T3, by proposing a new label. To assist in maintaining label consistency, candidate T3 label ideas are presented as few-shot examples.
Explicit instructions are provided for the SLM to enclose any new labels within curly brackets {}, ensuring that AI-generated labels can be clearly identified. After receiving the task, the Data Analyst may decide to propose a new three-tier label using the current best label as a prefix.
Subsequently, the Senior Analyst is provided with background information about the task and asked to give constructive feedback to the Data Analyst, including ensuring the proper formatting of the new labels by enclosing them in curly brackets. The Data Analyst addresses the feedback in further discussions. This iterative process runs for two rounds between the respective roles. This implementation uses the phi3:3.8b-mini-128k-instruct-q8_0 model for both the analyst and senior analyst roles.
The role-play effectively facilitated the introduction of new label component formatting rules. However, the discussions during the role play were not deeply meaningful at times. While the discussions were relevant to the topic, they lacked the depth and intelligence necessary to significantly enhance the final response. In other words, the SLMs did not demonstrate the required intelligence to perform the task to an acceptable standard. This highlights a need for further refinement in the role play setup and the models that are used to ensure higher quality and more meaningful discussions in future implementations.
Step 8: Conclusion Synthesis and Label Finalization
After the designated rounds of discussions between the Senior Analyst and the Data Analyst about the potential extension of current labels are complete, their final conversation is processed into a summarizing prompt. This process corresponds to the analyst_extract_labels_and_conclusions step in Figure 3. This prompt aims to synthesize the conclusion of the discussion and extract the final proposed label in JSON format. For this task, the team selected the phi3:3.8b-mini-128k-instruct-q8_0 model because of its ability to handle large contexts effectively.
This process of summarizing role play discussions into final conclusions has become a recurrent pattern in agentic workflows. However, observation showed that the discussions, which are often hallucinated or lacking in intelligence, can exacerbate the complexity of generating clear and concise summaries. Such discussions sometimes lead to confusion rather than clarity in the synthesized outcomes. There is a recognized need for more capable and intelligent models to address these issues. Advanced models could significantly improve the quality of the discussions and, therefore, the accuracy and usability of the final summarized conclusions. This step underscores the ongoing requirement to enhance model capabilities to better support complex decision-making and summarization tasks in agentic workflows.