
Experiment 2
Experiment 2
-
In response to challenges identified in Experiment 1, particularly the single-point failures caused by inadequate retrieval of relevant candidate labels, the Dell SOAS team pursued a refined agentic approach in Experiment 2. The team created a dedicated agent for each label level, starting with Level 1 (T1). The duty of the T1 agent was to ensure precision in identifying all applicable T1 labels and to handle scenarios with multiple unrelated technical symptoms or customer requests. This experiment used the phi3:latest model from Ollama, hosted locally, to perform all workflow steps.
The following figures shows the Experiment 2 workflow implementation:
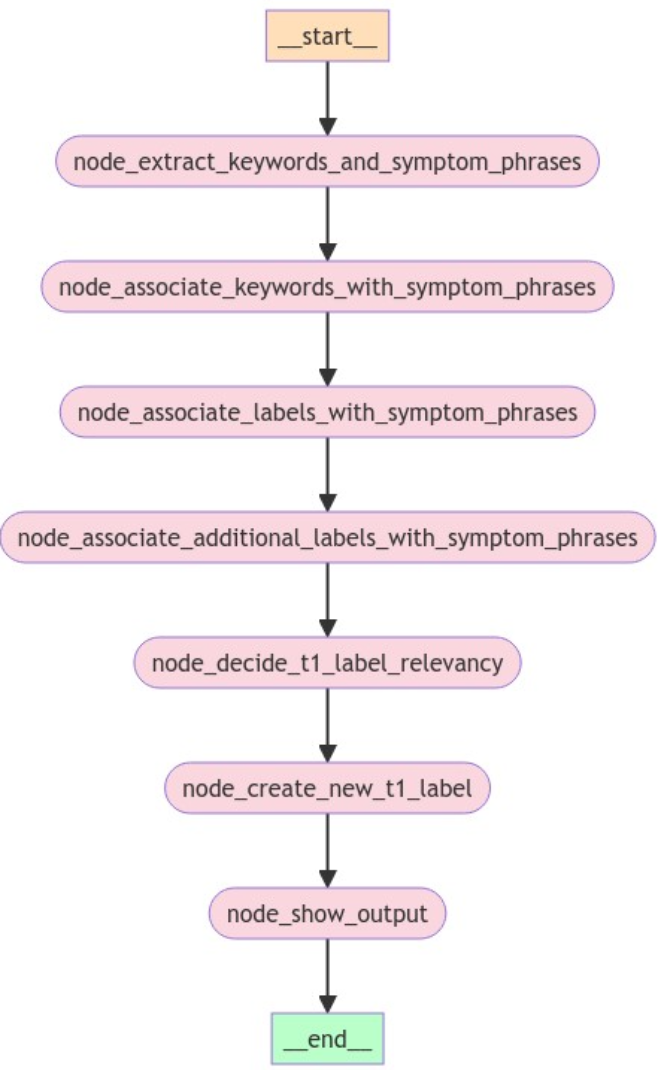
Figure 2. Experiment 2 agent workflow
Step 1: Keyword and Theme Identification
The Data Analyst began by identifying all relevant keywords, distinct symptom themes, and customer requests. Like humans, SLMs often have difficulty associating symptoms and root causes in complex cases. However, the SLMs generally succeeded in identifying major technical issues, customer request themes, and keywords—the node_extract_keywords_and_symptom_phrases step in Figure 2.
This step proved crucial for ensuring that subsequent steps could associate labels accurately with each identified theme, catering to multi-label scenarios or identifying multiple unrelated technical or non-technical issues.
Step 2: Verification and Association of Symptom Phrases
Following the identification of keywords and themes, the workflow incorporated a secondary verification step by a Data Analyst role, where any missing symptoms were added and keywords were associated with each symptom theme. This is the node_associate_labels_with_symptom_phrases step in Figure 2.
Step 3: Association of Candidate T1 Labels
In this phase, a Data Analyst role selected the best possible set of candidate T1 labels for each identified symptom theme or request—the node_associate_symptoms_with_labels workflow step in Figure 2. For this purpose, the team identified the scope of each T1 label by embedding the encompassing T2-T3 labels directly into the prompt for clarity and precision.
Here is an example of a T1 label with derived scope from T2-T3 scope:
[backup & data management] - Issues related to backup products and services, including drivers, errors, installation, OEM referrals, vendor escalations, and version updatesCustom instructions were incorporated in the prompt to minimize assumptions. For instance, if a display issue was ambiguous between internal or external display, both labels were considered at this stage.
The inclusion of detailed descriptions of label scopes significantly enhanced the accuracy of T1 candidate label selection. However, the team observed that SLMs sometimes responded inconsistently to these rules.
In an additional step, a separate Data Analyst role identified candidate T1 labels based on a much simpler prompt. The simpler prompt did not include lengthy scopes of each label, ensuring that all the relevant candidate T1 labels are identified for each distinct symptom or customer request: the node_associate_additional_labels_with_symptom_phrases step in Figure 2.
The final set of candidate T1 labels for each symptom or customer request includes unique T1 labels from both the preceding processes.
Step 4: Selection of Optimal Labels
A Data Analyst decided on the best labels from the proposed candidates based on their scope and the specifics of the given text, such as a case note. This step concluded with the selection of the best T1 label and a justification for this choice, corresponding to node_decide_t1_label_relevancy in Figure 2.
The divide-and-conquer strategy of breaking down the overall problem into multiple focused tasks proved effective. Allowing the SLM to make decisions based on candidate labels and their defined scopes led to better results.
Step 5: Final Label Classification
A Data Analyst role classified the input into existing labels or created a new label based on the case note, extracted symptoms, and then created the set of T1 labels with defined scopes. The final output included the label and a proposed scope for that label.
The sample labels that are included in the prompt acted as “few-shot” examples, which typically resulted in the creation of labels that were both grammatically consistent and well formatted. For more information about the few-shot learning technique, see Language Models are Few-Shot Learners.
The model was less successful in making decisions about whether to create a new label, a task that remains challenging even for humans. This difficulty was especially evident in edge cases such as deciding whether “NPU overheating” warranted a new category or should be incorporated under the existing [thermal] label—node_create_new_t1_label in Figure 2.