
Experiment 1
Experiment 1
-
As shown in the following figure, this experiment implements a five-step workflow using multiple agent roles (prompts) to classify technical support text inputs into the hierarchical label system. The workflow primarily uses the phi3:latest model from Ollama for role-specific prompt execution.
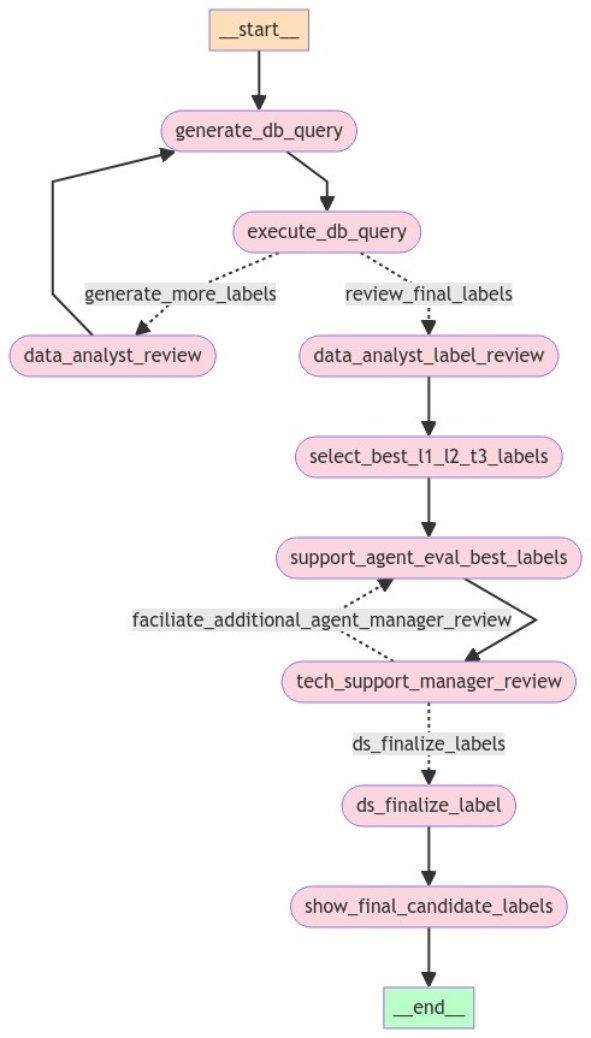
Figure 1. Experiment 1 agent workflow
Tier 1 (T1) represents the highest-level category, for example, [boot]
Tier 2 (T2) provides more specificity, for example, [no boot]
Tier 3 (T3) offers the most detailed classification, for example, [file corruption]A complete label might include components from one tier, two tiers, or all three tiers: [boot]-[no boot]-[file corruption]
Step 1: Candidate Label Retrieval - Generate a comprehensive list of potential T1-T2-T3 labels for given text input
Given input text such as an inbound customer email message:
- A Data Engineer SLM-agent creates database search queries to run two tools:
- semantic_search
- lexical_search (the generate_db_query step in Figure 1).
These tools operate on a PGVector database in which T1-T2-T3 labels have been embedded using the "multilingual-e5-large" embedding model. The semantic_search function retrieves the top N-most similar labels given a query or text. The lexical_search performs a native PostgreSQL keyword-based search on the same table (execute_db_query step in Figure 1).
2. A Senior Data Analyst agent examines the retrieved labels (the top 5, in this case) and provides feedback by getting cues from labels to add or refine label search queries (the data_analyst_review step Figure 1).
3. The Data Engineer refines the queries based on feedback and retrieves additional candidate labels.
The main idea behind this iterative candidate label retrieval is to minimize the possibility of accidentally omitting a relevant label for the rest of the processing.
On some limited experimental runs, the team observed that, despite the iterative process, agents fail to pick up multiple disjoint technical issues, such as key not working in keyboard and computer is slow. Agents also missed multiple customer requests that were mentioned in the input text, leading to incomplete candidate label sets. Failure to retrieve proper candidate labels at this stage becomes a single point of failure because subsequent steps rely on these labels.
Step 2: Label Relevance Assessment - Determine the relevance of each candidate label to the input text and filter out irrelevant candidates
A Senior Data Scientist agent assesses the relevance of each candidate label to the given input text: is_label_relevant. The agent then provides justification. In this step, the Dell SOAS team noticed that the SLM lacks "experience" or prior knowledge about the scope of labels, which poses a challenge in accurate assessment. This is the data_analyst_label_review step in Figure 1.
Step 3: Best Candidate Label Identification - Identify the best candidate labels from the filtered relevant labels
The Senior Data Scientist agent determines the relevant labels and identifies the best candidate labels: select_best_l1_l2_l3_labels in Figure 1.
Step 4: Role-Play for Label Refinement - Validate and refine label selections through multi-agent interaction
This step has three phases:
- A Senior Tech Support Agent reviews all candidate labels and the best labels chosen by the Senior Data Scientist, and then assesses appropriate labels and their levels.
- A Senior Manager reviews the same information and the agent's decision, and then provides feedback or asks clarifying questions.
- The Senior Tech Support Agent refines decisions based on the manager's feedback. This process iterates for a pre-configured number of rounds, the support_agent_eval_best_labels and tech_support_manager_review steps in Figure 1.
The team observed that the SLMs frequently demonstrate unintelligent communication and discussions during the tests. The language model does not always engage in meaningful conversations. While sentences are grammatically correct, spelled properly, and contextually relevant, they often lack true intelligence and have difficulty with decision-making. Despite these limitations, this multi-agent role-play feedback loop or pattern approach is still beneficial in minimizing hallucination; for example, by checking against guardrails or reminding other roles about certain formatting rules, compared to decisions being made by a single role. However, the role-play process adds to latency and makes it difficult to track and trace why certain decisions were made.
Step 5: Conversation Analysis and Final Recommendation - Analyze role-play discussions, summarize conversations, and identify overall recommendations and final labels
The exchange between the Senior Tech Support Agent and the Manager is captured and saved in the form of a conventional ‘chat log.’ The SOAS team have introduced the role of a Data Scientist agent, whose responsibility is to analyze and extract insights from the chat log. The main duties of the role are to summarize the discussions, identify significant conclusions, and formulate final label recommendations, as depicted in the ds_finalize_label step in Figure 1.
The team observed an increased hallucination risk with SLMs when analyzing lengthy conversations. The potential for single-point failure also exists if the summary is inaccurate, leading to incorrect results. Conversely, the team found that summarizing role-play discussions really helps to extract critical information in the required format, which might be JSON, while allowing role-play conversations to have a freestyle format. This approach maintains the benefits of open-ended discussions while still producing structured, machine-readable outputs.
- A Data Engineer SLM-agent creates database search queries to run two tools: