
Data reduction and storage efficiency
Data reduction and storage efficiency
-
Data deduplication - SmartDedupe
The OneFS SmartDedupe architecture is consisted of five principal modules:
- Deduplication Control Path
- Deduplication Job
- Deduplication Engine
- Shadow Store
- Deduplication Infrastructure
The SmartDedupe control path consists of the OneFS Web Management Interface (WebUI), command-line interface (CLI) and RESTful platform API, and is responsible for managing the configuration, scheduling, and control of the deduplication job. The job itself is a highly distributed background process that manages the orchestration of deduplication across all the nodes in the cluster. Job control encompasses file system scanning, detection, and sharing of matching data blocks, in concert with the Deduplication Engine. The Deduplication Infrastructure layer is the kernel module that performs the consolidation of shared data blocks into shadow stores, the file system containers that hold both physical data blocks and references, or pointers, to shared blocks. These elements are described in more detail below.
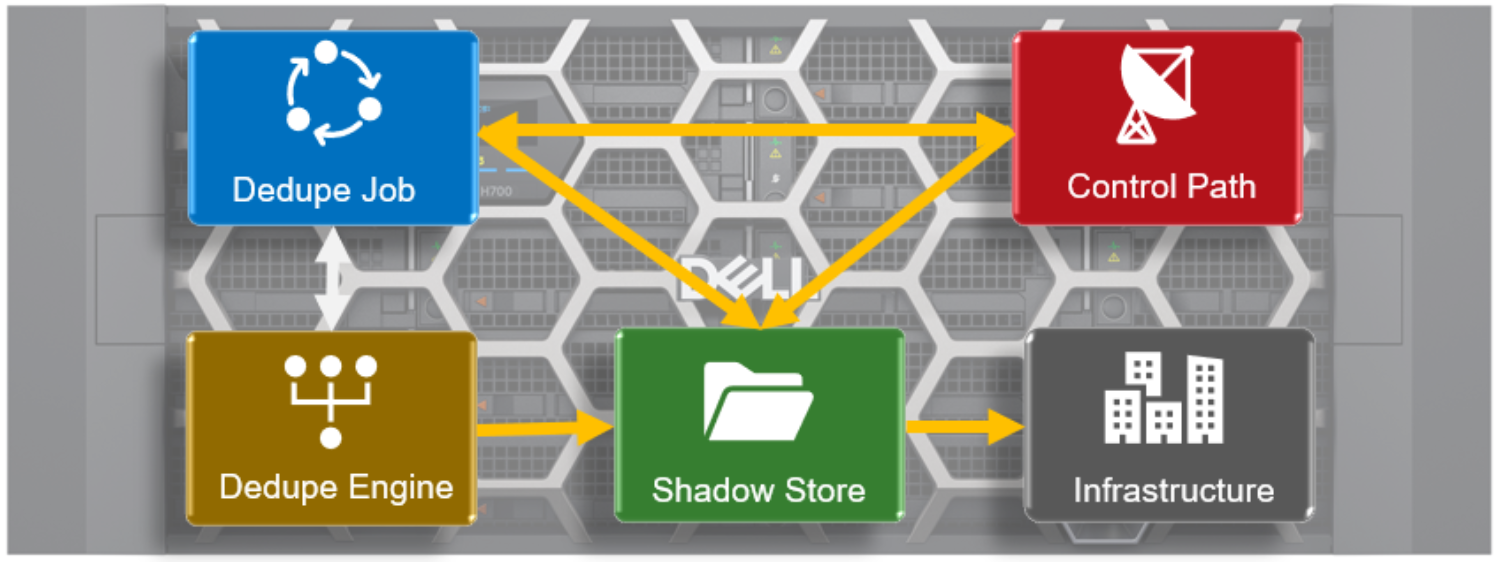
Figure 21. OneFS SmartDedupe modular architecture
Further information is available in the OneFS SmartDedupe white paper.
Shadow stores
OneFS shadow stores are file system containers that allow data to be stored in a sharable manner. As such, files on OneFS can contain both physical data and pointers, or references, to shared blocks in shadow stores.
Shadow stores are similar to regular files, but typically do not contain all the metadata typically associated with regular file inodes. In particular, time-based attributes (creation time and modification time) are explicitly not maintained. Each shadow store can contain up to 256 blocks, with each block able to be referenced by 32,000 files. If this 32K reference limit is exceeded, a new shadow store is created. Also, shadow stores do not reference other shadow stores. And snapshots of shadow stores are not allowed, since shadow stores have no hard links.
Shadow stores are also used for OneFS file clones and small file storage efficiency (SFSE), in addition to deduplication.
Small File Storage Efficiency
Another principal consumer of shadow stores is OneFS Small File Storage Efficiency. This feature maximizes the space utilization of a cluster by decreasing the amount of physical storage required to house the small files that often consist of an archive dataset, such as found in healthcare PACS workflows.
Efficiency is achieved by scanning the on-disk data for small files, which are protected by full copy mirrors, and packing them in shadow stores. These shadow stores are then parity protected, rather than mirrored, and typically provide storage efficiency of 80% or greater.
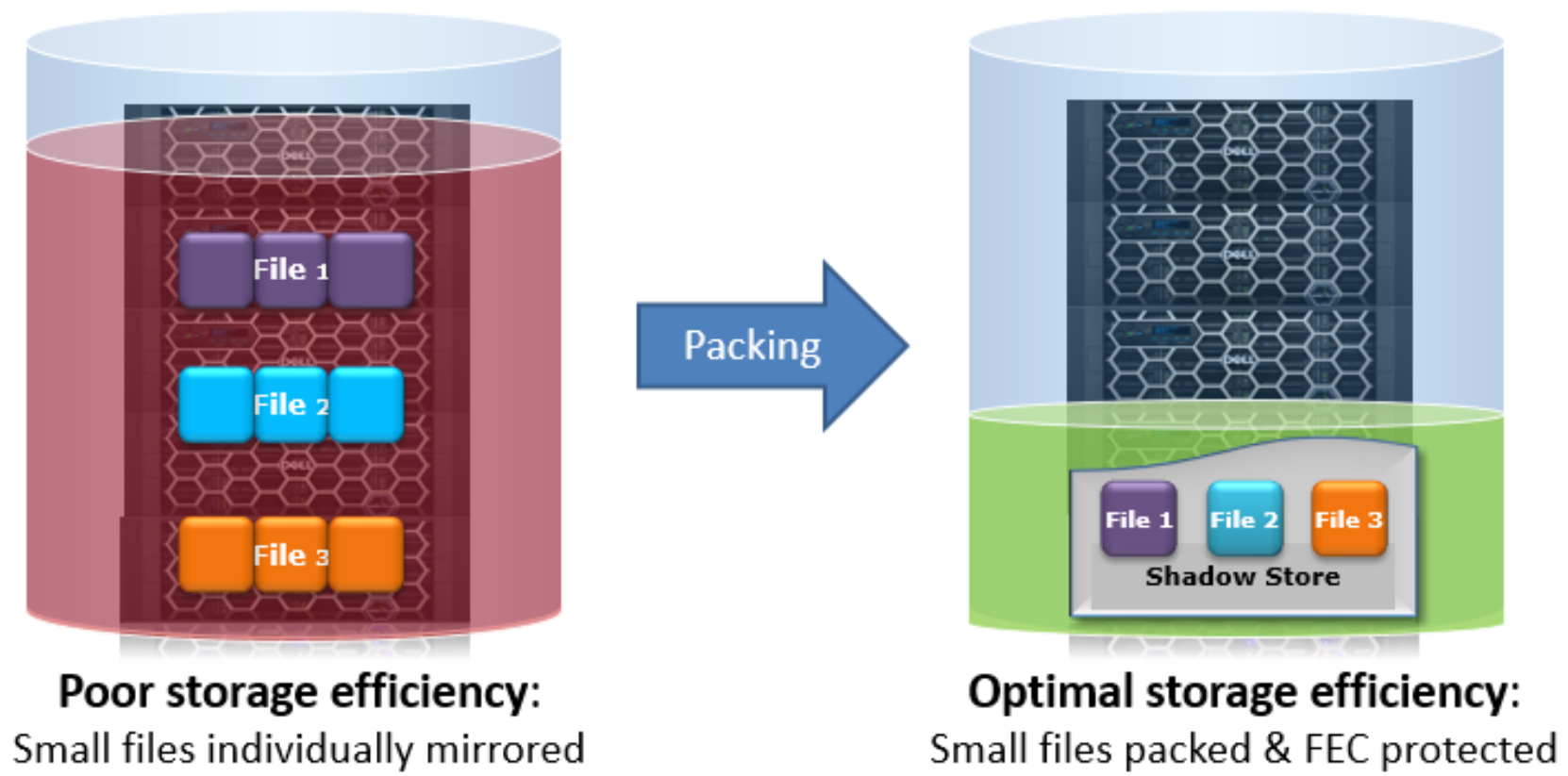
Figure 22. Small file containerization
Small File Storage Efficiency trades a small read latency performance penalty for improved storage utilization. The archived files obviously remain writable, but when containerized files with shadow references are deleted, truncated, or overwritten it can leave unreferenced blocks in shadow stores. These blocks are later freed and can result in holes which reduces the storage efficiency.
The actual efficiency loss depends on the protection level layout used by the shadow store. Smaller protection group sizes are more susceptible, as are containerized files, since all the blocks in containers have at most one referring file and the packed sizes (file size) are small.
A defragmenter is provided to reduce the fragmentation of files as a result of overwrites and deletes. This shadow store defragmenter is integrated into the ShadowStoreDelete job. The defragmentation process works by dividing each containerized file into logical chunks (~32 MB each) and assesses each chunk for fragmentation.
If the storage efficiency of a fragmented chunk is below target, that chunk is processed by evacuating the data to another location. The default target efficiency is 90% of the maximum storage efficiency available with the protection level used by the shadow store. Larger protection group sizes can tolerate a higher level of fragmentation before the storage efficiency drops below this threshold.
In-line data reduction
OneFS inline data reduction is available on the F910, F900, F810, F600, and F200 all-flash nodes, H700/7000 and H5600 hybrid chassis, and the A300/3000 archive platform. The OneFS architecture consists of the following principal components:
- Data Reduction Platform
- Compression Engine and Chunk Map
- Zero block removal phase
- Deduplication In-memory Index and Shadow Store Infrastructure
- Data Reduction Alerting and Reporting Framework
- Data Reduction Control Path
The in-line data reduction write path consists of three main phases:
- Zero Block Removal
- In-line Deduplication
- In-line Compression
If both inline compression and deduplication are enabled on a cluster, zero block removal is performed first, followed by deduplication, and then compression. This order allows each phase to reduce the scope of work in each subsequent phase.

Figure 23. In-line data reduction workflow
The F810 includes a hardware compression offload capability, with each node in an F810 chassis containing a Mellanox Innova-2 Flex Adapter. This means that compression and decompression are transparently performed by the Mellanox adapter with minimal latency, thereby avoiding the need for consuming a node’s expensive CPU and memory resources.
The OneFS hardware compression engine uses zlib, with a software implementation of igzip for the PowerScale F910, F900, F810, F600, F200, H700/7000, H5600, and A300/3000 nodes. Software compression is also used as fallback in the event of a compression hardware failure, and in a mixed cluster, for use in non-F810 nodes without a hardware compression capability, and as fallback in the event of a compression hardware failure. OneFS employs a compression chunk size of 128 KB, with each chunk consisting of sixteen 8 KB data blocks. This is optimal since it is also the same size that OneFS uses for its data protection stripe units, providing simplicity and efficiency, by avoiding the overhead of additional chunk packing.
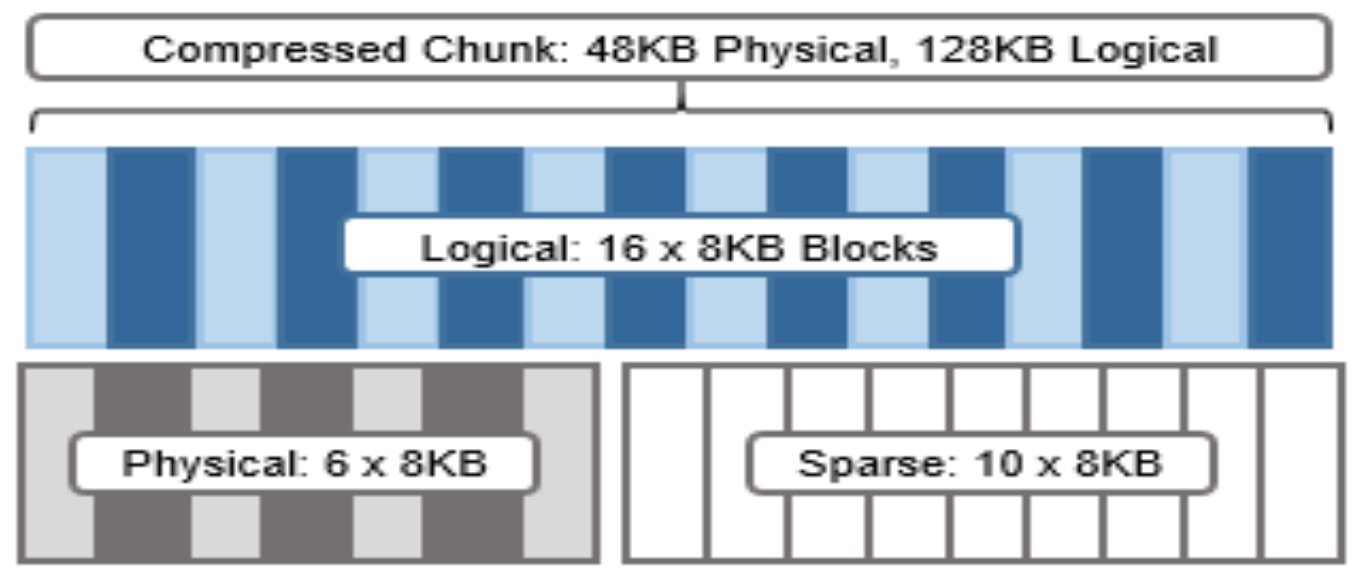
Figure 24. Compression chunks and OneFS transparent overlay
Consider the diagram above. After compression, this chunk is reduced from sixteen to six 8KB blocks in size. This means that this chunk is now physically 48 KB in size. OneFS provides a transparent logical overlay to the physical attributes. This overlay describes whether the backing data is compressed or not and which blocks in the chunk are physical or sparse, such that file system consumers are unaffected by compression. As such, the compressed chunk is logically represented as 128 KB in size, regardless of its actual physical size.
Efficiency savings must be at least 8 KB (one block) in order for compression to occur, otherwise that chunk or file will be passed over and remain in its original, uncompressed state. For example, a file of 16 KB that yields 8 KB (one block) of savings would be compressed. Once a file has been compressed, it is then FEC protected.
Compression chunks will never cross node pools. This avoids the need to decompress or recompress data to change protection levels, perform recovered writes, or otherwise shift protection-group boundaries.
Dynamic scale-out on demand
In contrast to traditional storage systems that must “scale up” when additional performance or capacity is needed, OneFS enables a storage system to “scale out,” seamlessly increasing the existing file system or volume into petabytes of capacity while increasing performance in tandem in a linear fashion.
Adding capacity and performance capabilities to a cluster is significantly easier than with other storage systems—requiring only three simple steps for the storage administrator: adding another node into the rack, attaching the node to the back-end network, and instructing the cluster to add the additional node. The new node provides additional capacity and performance since each node includes CPU, memory, cache, network, NVRAM, and I/O control pathways.
The AutoBalance feature of OneFS will automatically move data across the backend network in an automatic, coherent manner so existing data that resides on the cluster moves onto this new storage node. This automatic rebalancing ensures the new node will not become a hot spot for new data and that existing data can gain the benefits of a more powerful storage system. The AutoBalance feature of OneFS is also completely transparent to the end user and can be adjusted to minimize impact on high-performance workloads. This capability alone allows OneFS to scale transparently, on-the-fly, from TBs to PBs with no added management time for the administrator or increase in complexity within the storage system.
A large-scale storage system must provide the performance required for various workflows, whether they be sequential, concurrent, or random. Different workflows will exist between applications and within individual applications. OneFS provides for all these needs simultaneously with intelligent software. More importantly, with OneFS, throughput and IOPS scale linearly with the number of nodes present in a single system. Due to balanced data distribution, automatic rebalancing, and distributed processing, OneFS can leverage additional CPUs, network ports, and memory as the system scales.
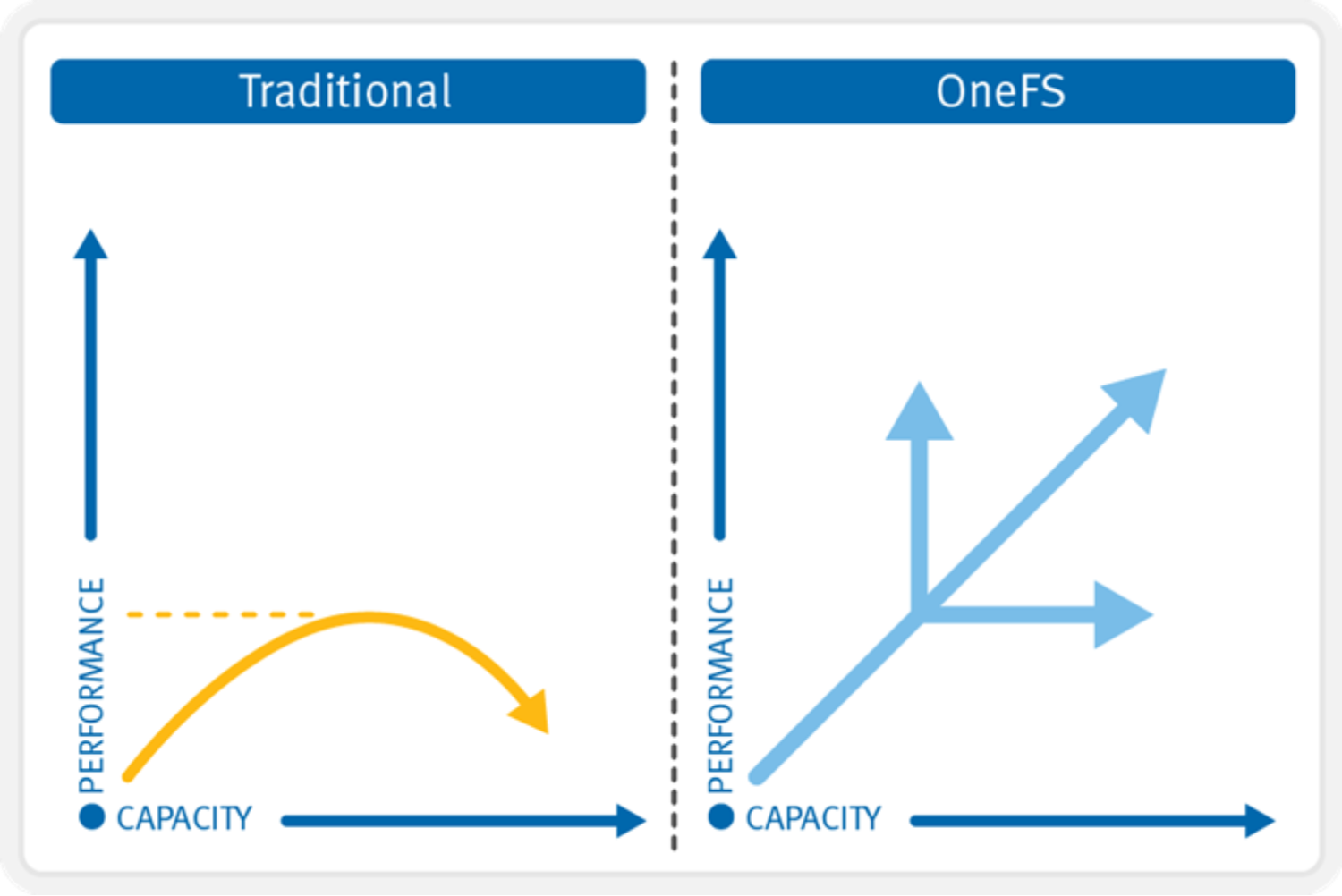
Figure 25. OneFS linear scalability
Interfaces
Administrators can use multiple interfaces to administer a storage cluster in their environments:
- Web Administration User Interface (“WebUI”)
- Command-Line Interface through SSH network access or RS232 serial connection
- LCD Panel on the nodes themselves for simple add/remove functions
- RESTful Platform API for programmatic control and automation of cluster configuration and management.
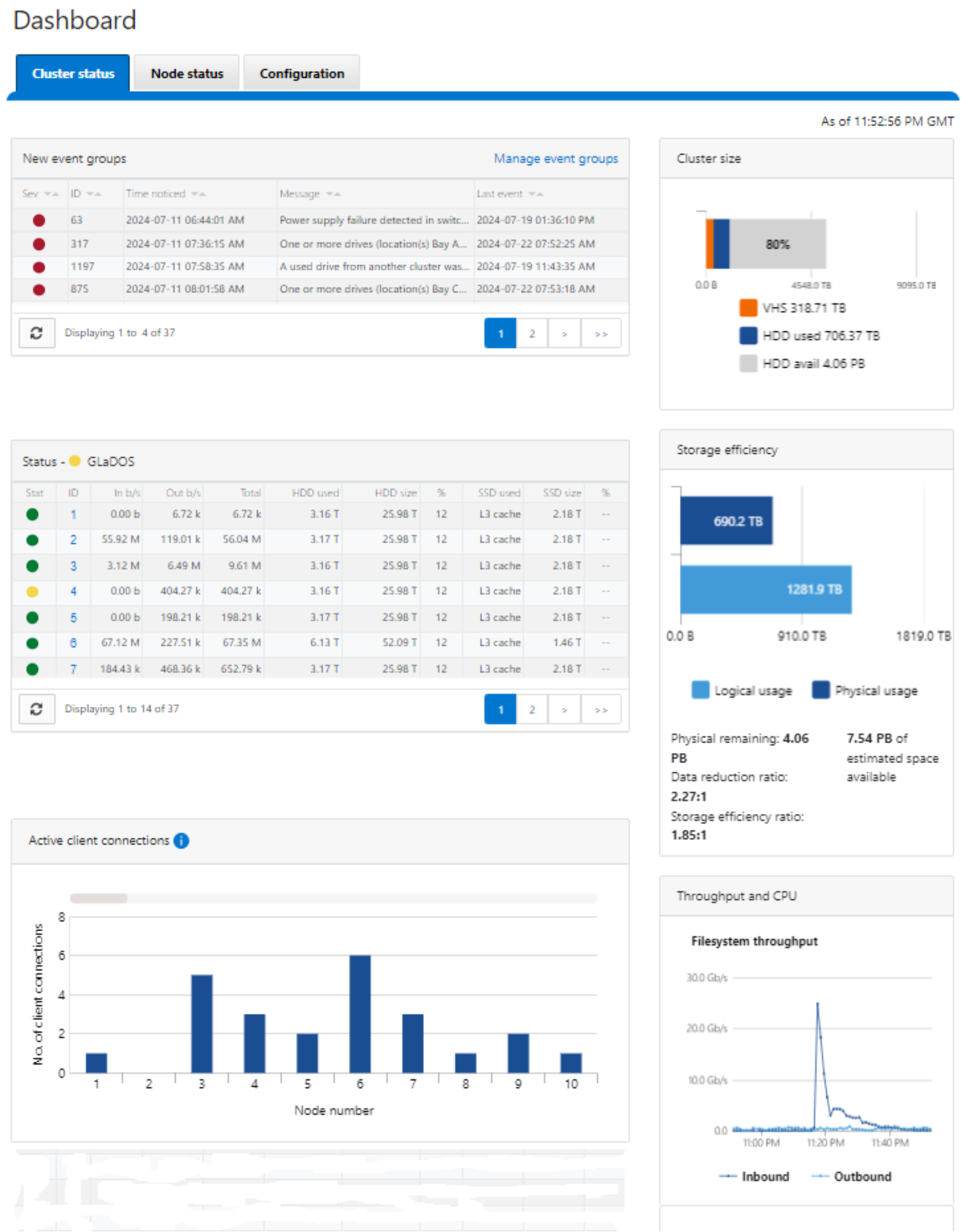
Figure 26. OneFS Web User Interface
OneFS 9.5 also supports multifactor authentication (MFA) with common access card (CAC) or personal identity verification (PIV) device, single sign-on (SSO) using SAML, and PKI-based authentication.
More information about OneFS commands and feature configuration is available in the OneFS Administration Guide.
Authentication and access control
Authentication services offer a layer of security by verifying users’ credentials before allowing them to access and modify files. OneFS supports four methods for authenticating users:
- Active Directory (AD)
- LDAP (Lightweight Directory Access Protocol)
- NIS (Network Information Service)
- Local users and Groups
OneFS supports the use of more than one authentication type. However, it is recommended that you fully understand the interactions between authentication types before enabling multiple methods on the cluster. See the product documentation for detailed information about how to properly configure multiple authentication modes.
Active Directory
Active Directory, a Microsoft implementation of LDAP, is a directory service that can store information about the network resources. While Active Directory can serve many functions, the primary reason for joining the cluster to the domain is to perform user and group authentication.
You can configure and manage a cluster’s Active Directory settings from the Web Administration interface or the command-line interface; however, it is recommended that you use Web Administration whenever possible.
Each node in the cluster shares the same Active Directory machine account making it very easy to administer and manage.
LDAP
The Lightweight Directory Access Protocol (LDAP) is a networking protocol used for defining, querying, and modifying services and resources. A primary advantage of LDAP is the open nature of the directory services and the ability to use LDAP across many platforms. The clustered storage system can use LDAP to authenticate users and groups in order to grant them access to the cluster.
NIS
The Network Information Service (NIS), designed by Sun Microsystems, is a directory services protocol that can be used by OneFS to authenticate users and groups when accessing the cluster. NIS, sometimes referred to as Yellow Pages (YP), is different from NIS+, which OneFS does not support.
Local users
OneFS supports local user and group authentication. You can create local user and group accounts directly on the cluster, using the WebUI interface. Local authentication can be useful when directory services—Active Directory, LDAP, or NIS—are not used, or when a specific user or application needs to access the cluster.
Access zones
Access zones provide a method to logically partition cluster access and allocate resources to self-contained units, thereby providing a shared tenant, or multi-tenant, environment. To facilitate this, Access Zones tie together the three core external access components:
- Cluster network configuration
- File protocol access
- Authentication
As such, SmartConnect zones are associated with a set of SMB shares, NFS exports, HDFS racks, and one or more authentication providers per zone for access control. This provides the benefits of a centrally managed single file system, which can be provisioned and secured for multiple tenants. This is particularly useful for enterprise environments where multiple separate business units are served by a central IT department. Another example is during a server consolidation initiative, when merging multiple Windows file servers that are joined to separate, un-trusted, Active Directory forests.
With Access Zones, the integrated System access zone includes an instance of each supported authentication provider, all available SMB shares, and all available NFS exports by default.
These authentication providers can include multiple instances of Microsoft Active Directory, LDAP, NIS, and local user or group databases.
Roles Based Administration
Roles Based Administration is a cluster management roles-based access control system (RBAC) that divides up the powers of the “root” and “administrator” users into more granular privileges and allows assignment of these to specific roles. These roles can then be granted to other non-privileged users. For example, data center operations staff can be assigned read-only rights to the entire cluster, allowing full monitoring access but no configuration changes to be made. OneFS provides a collection of integrated roles, including audit, and system and security administrator, plus the ability to create custom defined roles, either per access zone or across the cluster. Roles Based Administration is integrated with the OneFS command-line interface, WebUI, and Platform API.
For more information about identity management, authentication, and access control in multi-protocol environments, See the OneFS Multiprotocol Security Guide.
OneFS auditing
OneFS provides the ability to audit system configuration and NFS, SMB, and HDFS protocol activity on a cluster. This allows organizations to satisfy various data governance and regulatory compliance mandates that they may be bound to.
All audit data is stored and protected within the cluster file system and is organized by audit topic. From here, audit data can be exported using the Dell Common Event Enabler (CEE) framework to third-party applications like Varonis DatAdvantage and Symantec Data Insight. OneFS Protocol auditing can be enabled per Access Zone, allowing granular control across the cluster.
A cluster can write audit events across up to five CEE servers per node in a parallel, load-balanced configuration. This allows OneFS to deliver an end to end, enterprise grade audit solution.
Further information is available in the OneFS Audit white paper.