
Data protection
Data protection
-
A file system journal, which stores information about changes to the file system, is designed to enable fast, consistent recoveries after system failures or crashes, such as power loss. The file system replays the journal entries after a node or cluster recovers from a power loss or other outage. Without a journal, a file system would need to examine and review every potential change individually after a failure (an “fsck” or “chkdsk” operation); in a large file system, this operation can take a long time.
OneFS is a journaled file system in which each node contains a battery-backed NVRAM card used for protecting uncommitted writes to the file system. The NVRAM card battery charge lasts many days without requiring a recharge. When a node boots up, it checks its journal and selectively replays transactions to disk where the journaling system deems it necessary.
OneFS will mount only if it can guarantee that all transactions not already in the system have been recorded. For example, if proper shutdown procedures were not followed, and the NVRAM battery discharged, transactions might have been lost; to prevent any potential problems, the node will not mount the file system.
Hardware failures and quorum
In order for the cluster to properly function and accept data writes, a quorum of nodes must be active and responding. A quorum is defined as a simple majority: a cluster with ùë• nodes must have ‚åäùë•/2‚åã+1 nodes online in order to allow writes. For example, in a seven-node cluster, four nodes would be required for a quorum. If a node or group of nodes is up and responsive, but is not a member of a quorum, it runs in a read-only state.
OneFS uses a quorum to prevent “split-brain” conditions that can be introduced if the cluster should temporarily split into two clusters. By following the quorum rule, the architecture guarantees that regardless of how many nodes fail or come back online, if a write takes place, it can be made consistent with any previous writes that have ever taken place. The quorum also dictates the number of nodes required in order to move to a given data protection level. For an erasure-code-based protection-level of ùëÅ+ùëÄ, the cluster must contain at least 2ùëÄ+1 nodes. For example, a minimum of seven nodes is required for a +3n configuration; this allows for a simultaneous loss of three nodes while still maintaining a quorum of four nodes for the cluster to remain fully operational. If a cluster does drop below quorum, the file system will automatically be placed into a protected, read-only state, denying writes, but still allowing read access to the available data.
Hardware failures—add/remove nodes
A system called the group management protocol (GMP) enables global knowledge of the cluster state at all times and guarantees a consistent view across the entire cluster of the state of all other nodes. If one or more nodes become unreachable over the cluster interconnect, the group is “split” or removed from the cluster. All nodes resolve to a new consistent view of their cluster. (Think of this as if the cluster were splitting into two separate groups of nodes, though note that only one group can have quorum.) While in this split state, all data in the file system is reachable and, for the side maintaining quorum, modifiable. Any data stored on the “down” device is rebuilt using the redundancy stored in the cluster.
If the node becomes reachable again, a “merge” or add occurs, bringing nodes back into the cluster. (The two groups merge back into one.) The node can rejoin the cluster without being rebuilt and reconfigured. This is unlike hardware RAID arrays, which require drives to be rebuilt. AutoBalance may restripe some files to increase efficiency, if some of their protection groups were overwritten and transformed to narrower stripes during the split.
The OneFS Job Engine also includes a process called Collect, which acts as an orphan collector. When a cluster splits during a write operation, some blocks that were allocated for the file may need to be re-allocated on the quorum side. This will “orphan” allocated blocks on the non-quorum side. When the cluster re-merges, the Collect job will locate these orphaned blocks through a parallelized mark-and-sweep scan and reclaim them as free space for the cluster.
Scalable rebuild
OneFS does not rely on hardware RAID either for data allocation, or for reconstruction of data after failures. Instead OneFS manages the protection of file data directly, and when a failure occurs, it rebuilds data in a parallelized fashion. OneFS can determine which files are affected by a failure in constant time, by reading inode data in a linear manor, directly off disk. The set of affected files are assigned to a set of worker threads that are distributed among the cluster nodes by the job engine. The worker nodes repair the files in parallel. This implies that as cluster size increases, the time to rebuild from failures decreases. This has an enormous efficiency advantage in maintaining the resiliency of clusters as their size increases.
Virtual hot spare
Most traditional storage systems based on RAID require the provisioning of one or more “hot spare” drives to allow independent recovery of failed drives. The hot spare drive replaces the failed drive in a RAID set. If these hot spares are not themselves replaced before more failures appear, the system risks a catastrophic data loss. OneFS avoids the use of hot spare drives, and simply borrows from the available free space in the system in order to recover from failures; this technique is called virtual hot spare. In doing so, it allows the cluster to be fully self-healing, without human intervention. The administrator can create a virtual hot spare reserve, allowing the system to self-heal despite ongoing writes by users.
File-level data protection with erasure coding
A cluster is designed to tolerate one or more simultaneous component failures, without preventing the cluster from serving data. To achieve this, OneFS protects files with either erasure code-based protection, using Reed-Solomon error correction (N+M protection), or a mirroring system. Data protection is applied in software at the file-level, enabling the system to focus on recovering only those files that are compromised by a failure, rather than having to check and repair an entire file set or volume. OneFS metadata and inodes are always protected by mirroring, rather than Reed-Solomon coding, and with at least the level of protection as the data they reference.
Because all data, metadata, and protection information are distributed across the nodes of the cluster, a cluster does not require a dedicated parity node or drive, or a dedicated device or set of devices to manage metadata. This ensures that no one node can become a single point of failure. All nodes share equally in the tasks to be performed, providing perfect symmetry and load-balancing in a peer-to-peer architecture.
OneFS provides several levels of configurable data protection settings, which you can modify at any time without needing to take the cluster or file system offline.
For a file protected with erasure codes, we say that each of its protection groups is protected at a level of N+M/b, where N>M and M>=b. The values N and M represent, respectively, the number of drives used for data and for erasure codes within the protection group. The value of b relates to the number of data stripes used to lay out that protection group and is covered below. A common and easily understood case is where b=1, implying that a protection group incorporates: N drives worth of data; M drives worth of redundancy, stored in erasure codes; and that the protection group should be laid out over exactly one stripe across a set of nodes. This allows for M members of the protection group to fail simultaneously and still provide 100% data availability. The M erasure code members are computed from the N data members. Figure 14 shows the case for a regular 4+2 protection group (N=4, M=2, b=1).
Because OneFS stripes files across nodes, this implies that files striped at N+M can withstand ùëÄ simultaneous node failures without loss of availability. OneFS therefore provides resiliency across any type of failure, whether it be to a drive, a node, or a component within a node (say, a card). Furthermore, a node counts as a single failure, regardless of the number or type of components that fail within it. Therefore, if five drives fail in a node, it only counts as a single failure for the purposes of N+M protection.
OneFS can uniquely provide a variable level of M, up to four, providing for quadruple-failure protection. This goes far beyond the maximum level of RAID commonly in use today, which is the double-failure protection of RAID 6. Because the reliability of the storage increases geometrically with this amount of redundancy, +4n protection can be orders of magnitude more reliable than traditional hardware RAID. This added protection means that large capacity SATA drives, such as 4 TB and 6 TB drives, can be added with confidence.
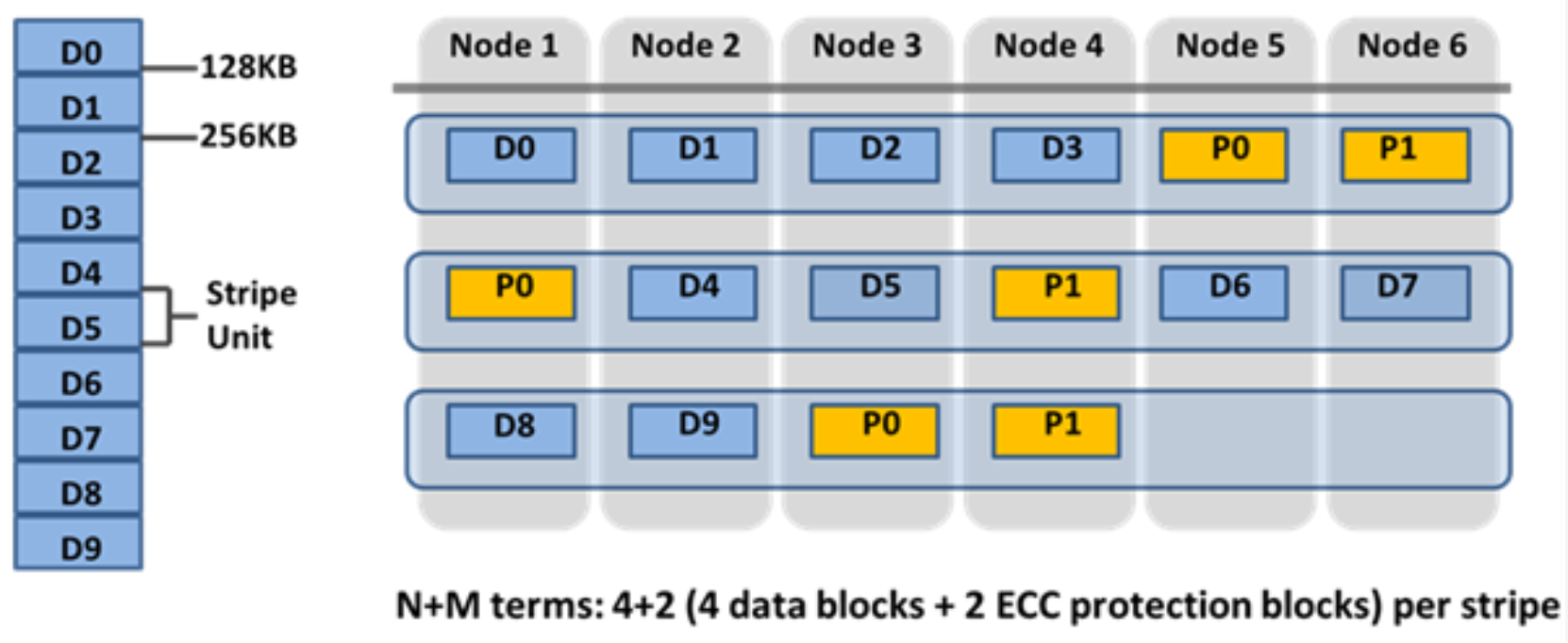
Figure 14. OneFS redundancy—N+M erasure code protection
Smaller clusters can be protected with +1n protection, but this implies that while a single drive or node could be recovered, two drives in two different nodes could not. Drive failures are orders of magnitude more likely than node failures. For clusters with large drives, it is desirable to provide protection for multiple drive failures, though single-node recoverability is acceptable.
To provide for a situation where we want to have double-disk redundancy and single-node redundancy, we can build up double or triple width protection groups of size. These double or triple width protection groups will “wrap” once or twice over the same set of nodes, as they are laid out. Since each protection group contains exactly two disks worth of redundancy, this mechanism will allow a cluster to sustain either a two or three drive failure or a full node failure, without any data unavailability.
Most important for small clusters, this method of striping is highly efficient, with an on-disk efficiency of M/(N+M). For example, on a cluster of five nodes with double-failure protection, were we to use N=3, M=2, we would obtain a 3+2 protection group with an efficiency of 1‚àí2/5 or 60%. Using the same 5-node cluster but with each protection group laid out over 2 stripes, N would now be 8 and M=2, so we could obtain 1-2/(8+2) or 80% efficiency on disk, retaining our double-drive failure protection and sacrificing only double-node failure protection.
OneFS supports several protection schemes. These include the ubiquitous +2d:1n, which protects against two drive failures or one node failure.
The best practice is to use the recommended protection level for a particular cluster configuration. This recommended level of protection is clearly marked as ‘suggested’ in the OneFS WebUI storage pools configuration pages and is typically configured by default. For all current Gen6 hardware configurations, the recommended protection level is “+2d:1n’.
The hybrid protection schemes are useful for Gen6 chassis high-density node configurations, where the probability of multiple drives failing far surpasses that of an entire node failure. In the unlikely event that multiple devices have simultaneously failed, such that the file is “beyond its protection level,” OneFS will re-protect everything possible and report errors on the individual files affected to the cluster’s logs.
OneFS also provides various mirroring options ranging from 2x to 8x, allowing from two to eight mirrors of the specified content. Metadata, for example, is mirrored at one level above FEC by default. For example, if a file is protected at +2n, its associated metadata object will be 3x mirrored.
The full range of OneFS protection levels is summarized in the following table:
Table 3. OneFS protection levels
Protection level
Description
+1n
Tolerate failure of 1 drive OR 1 node
+2d:1n
Tolerate failure of 2 drives OR 1 node
+2n
Tolerate failure of 2 drives OR 2 nodes
+3d:1n
Tolerate failure of 3 drives OR 1 node
Tolerate failure of 3 drives OR 1 node AND 1 drive
+3n
Tolerate failure of 3 drives or 3 nodes
+4d:1n
Tolerate failure of 4 drives or 1 node
+4d:2n
Tolerate failure of 4 drives or 2 nodes
+4n
Tolerate failure of 4 nodes
2x to 8x
Mirrored over 2 to 8 nodes, depending on configuration
OneFS enables an administrator to modify the protection policy in real time, while clients are attached and are reading and writing data.
Be aware that increasing a cluster’s protection level may increase the amount of space consumed by the data on the cluster.
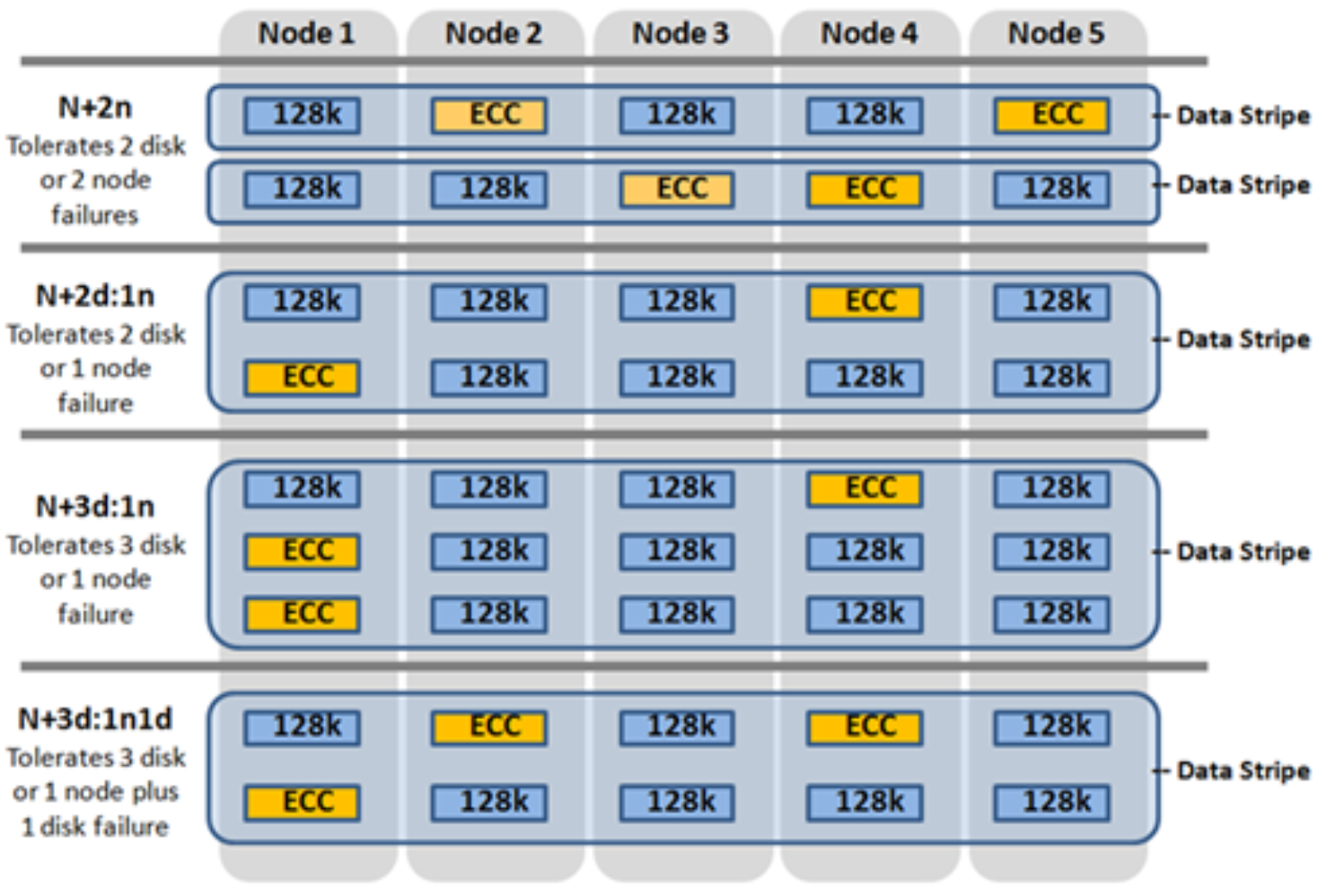
Figure 15. OneFS hybrid erasure code protection schemes
OneFS also provides under-protection alerting for new cluster installations. If the cluster is under-protected, the cluster event logging system (CELOG) will generate alerts, warning the administrator of the protection deficiency and recommending a change to the appropriate protection level for that particular cluster’s configuration.
Further information is available in the OneFS high availability and data protection white paper.
Automatic partitioning
Data tiering and management in OneFS is handled by the SmartPools framework. From a data protection and layout efficiency point of view, SmartPools facilitates the subdivision of large numbers of high-capacity, homogeneous nodes into smaller, more ‘Mean Time to Data Loss’ (MTTDL) friendly disk pools. For example, an 80-node H500 cluster would typically run at a +3d:1n1d protection level. However, partitioning it into four, twenty node disk pools would allow each pool to run at +2d:1n, thereby lowering the protection overhead and improving space utilization, without any net increase in management overhead.
In keeping with the goal of storage management simplicity, OneFS will automatically calculate and partition the cluster into pools of disks, or ‘node pools’, which are optimized for both MTTDL and efficient space usage. This means that protection level decisions, such as the eighty-node cluster example above, are not left to the customer.
With Automatic Provisioning, every set of compatible node hardware is automatically divided into disk pools consisting of up to forty nodes and six drives per node. These node pools are protected by default at +2d:1n, and multiple pools can then be combined into logical tiers and managed with SmartPools file pool policies. By subdividing a node’s disks into multiple, separately protected pools, nodes are significantly more resilient to multiple disk failures than previously possible.
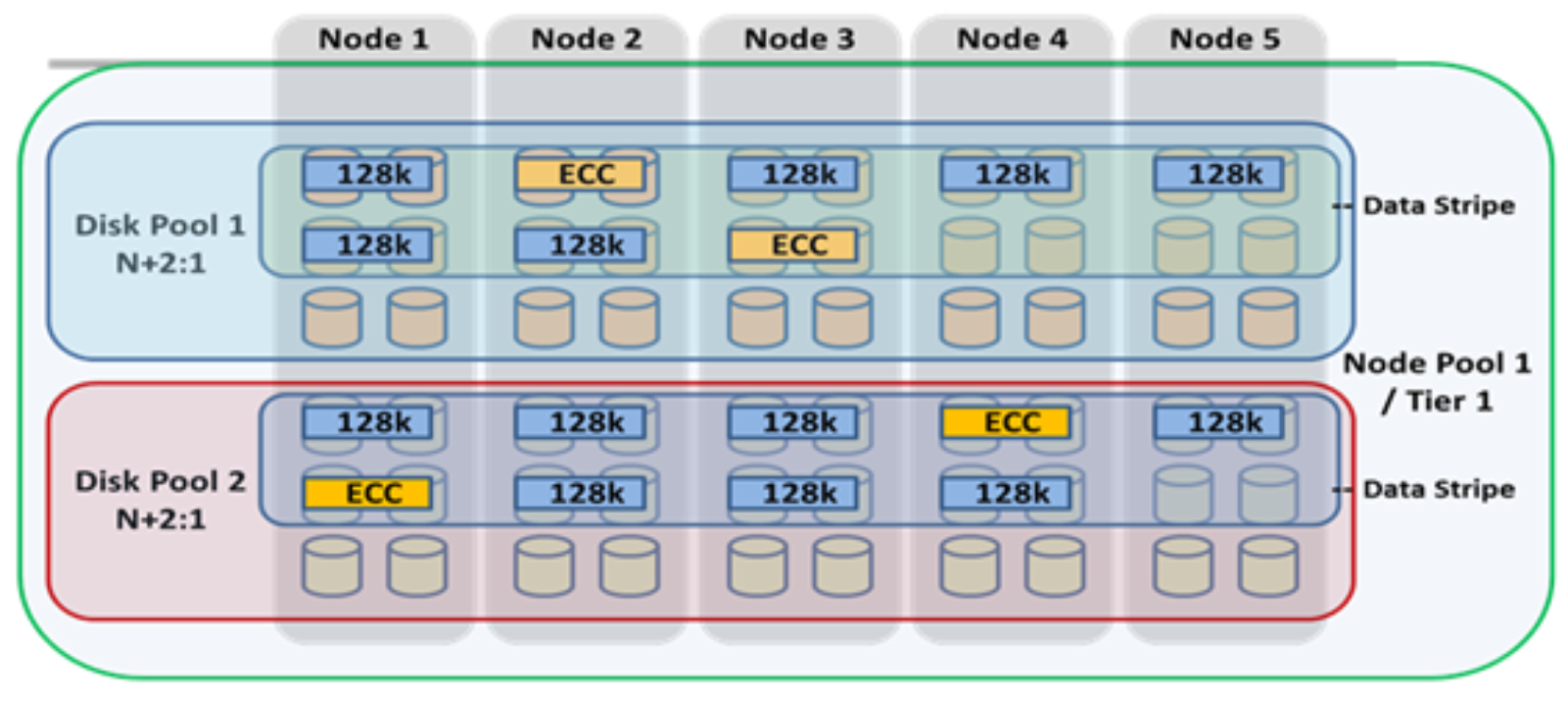
Figure 16. Automatic partitioning with SmartPools
More information is available in the SmartPools white paper.
PowerScale Gen6 modular hardware platforms feature a highly dense, modular design in which four nodes are contained in a single 4RU chassis. This approach enhances the concept of disk pools, node pools, and ‘neighborhoods’ - which adds another level of resilience into the OneFS failure domain concept. Each Gen6 chassis contains four compute modules (one per node), and five drive containers, or sleds, per node.

Figure 17. Gen6 platform chassis front view showing drive sleds
Each sled is a tray which slides into the front of the chassis and contains between three and six drives, depending on the configuration of a particular chassis. Disk pools are the smallest unit within the Storage Pools hierarchy. OneFS provisioning works on the premise of dividing similar nodes’ drives into sets, or disk pools, with each pool representing a separate failure domain. These disk pools are protected by default at +2d:1n (or the ability to withstand two drives or one entire node failure).
Disk pools are laid out across all five sleds in each Gen6 node. For example, a node with three drives per sled will have the following disk pool configuration:
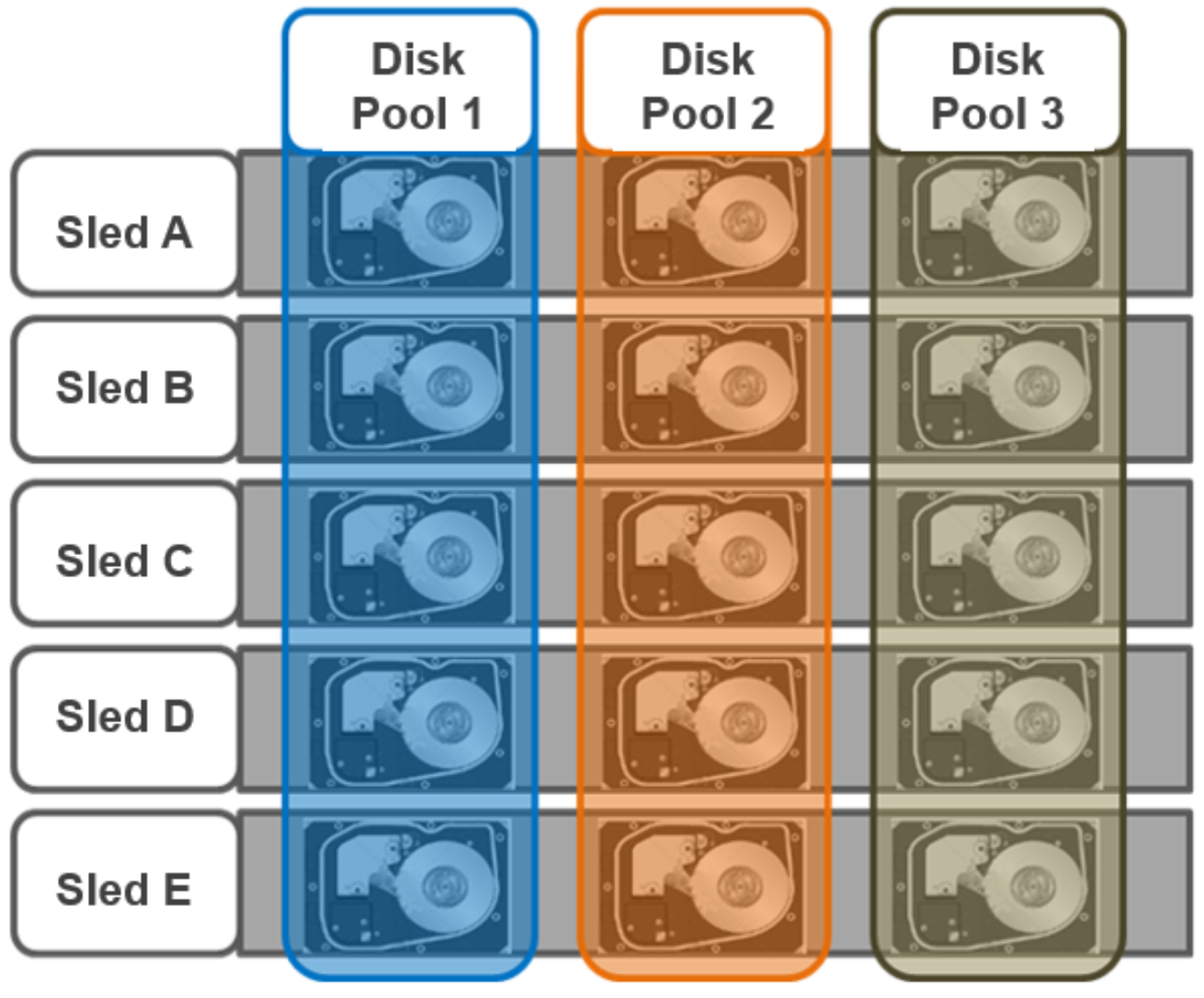
Figure 18. OneFS disk pools
Node pools are groups of Disk pools, spread across similar storage nodes (compatibility classes). This is illustrated in Figure 19. Multiple groups of different node types can work together in a single, heterogeneous cluster. For example: one Node pool of F-Series nodes for I/Ops-intensive applications, one Node pool of H-Series nodes, primarily used for high-concurrent and sequential workloads, and one Node pool of A-series nodes, primarily used for nearline and/or deep archive workloads.
This allows OneFS to present a single storage resource pool consisting of multiple drive media types—SSD, high-speed SAS, or large-capacity SATA—providing a range of different performance, protection, and capacity characteristics. This heterogeneous storage pool in turn can support a diverse range of applications and workload requirements with a single, unified point of management. It also facilitates the mixing of older and newer hardware, allowing for simple investment protection even across product generations, and seamless hardware refreshes.
Each Node pool only contains disk pools from the same type of storage nodes and a disk pool may belong to exactly one node pool. For example, F-Series nodes with 1.6 TB SSD drives would be in one node pool, whereas A-Series nodes with 10 TB SATA Drives would be in another. Today, a minimum of four nodes (one chassis) are required per node pool for Gen6 hardware, such as the PowerScale H700, or three nodes per pool for self-contained nodes like the PowerScale F910.
OneFS ‘neighborhoods’ are fault domains within a node pool, and their purpose is to improve reliability in general, and guard against data unavailability from the accidental removal of drive sleds. For self-contained nodes like the PowerScale F200, OneFS has an ideal size of 20 nodes per node pool, and a maximum size of 39 nodes. On the addition of the 40th node, the nodes split into two neighborhoods of twenty nodes. With the Gen6 platform, the ideal size of a neighborhood changes from 20 to 10 nodes. This protects against simultaneous node-pair journal failures and full chassis failures.
Partner nodes are nodes whose journals are mirrored. With the Gen6 platform, rather than each node storing its journal in NVRAM as in previous platforms, the nodes’ journals are stored on SSDs - and every journal has a mirror copy on another node. The node that contains the mirrored journal is referred to as the partner node. There are several reliability benefits gained from the changes to the journal. For example, SSDs are more persistent and reliable than NVRAM, which requires a charged battery to retain state. Also, with the mirrored journal, both journal drives have to die before a journal is considered lost. As such, unless both of the mirrored journal drives fail, both of the partner nodes can function as normal.
With partner node protection, where possible, nodes will be placed in different neighborhoods - and hence different failure domains. Partner node protection is possible once the cluster reaches five full chassis (20 nodes) when, after the first neighborhood split, OneFS places partner nodes in different neighborhoods:
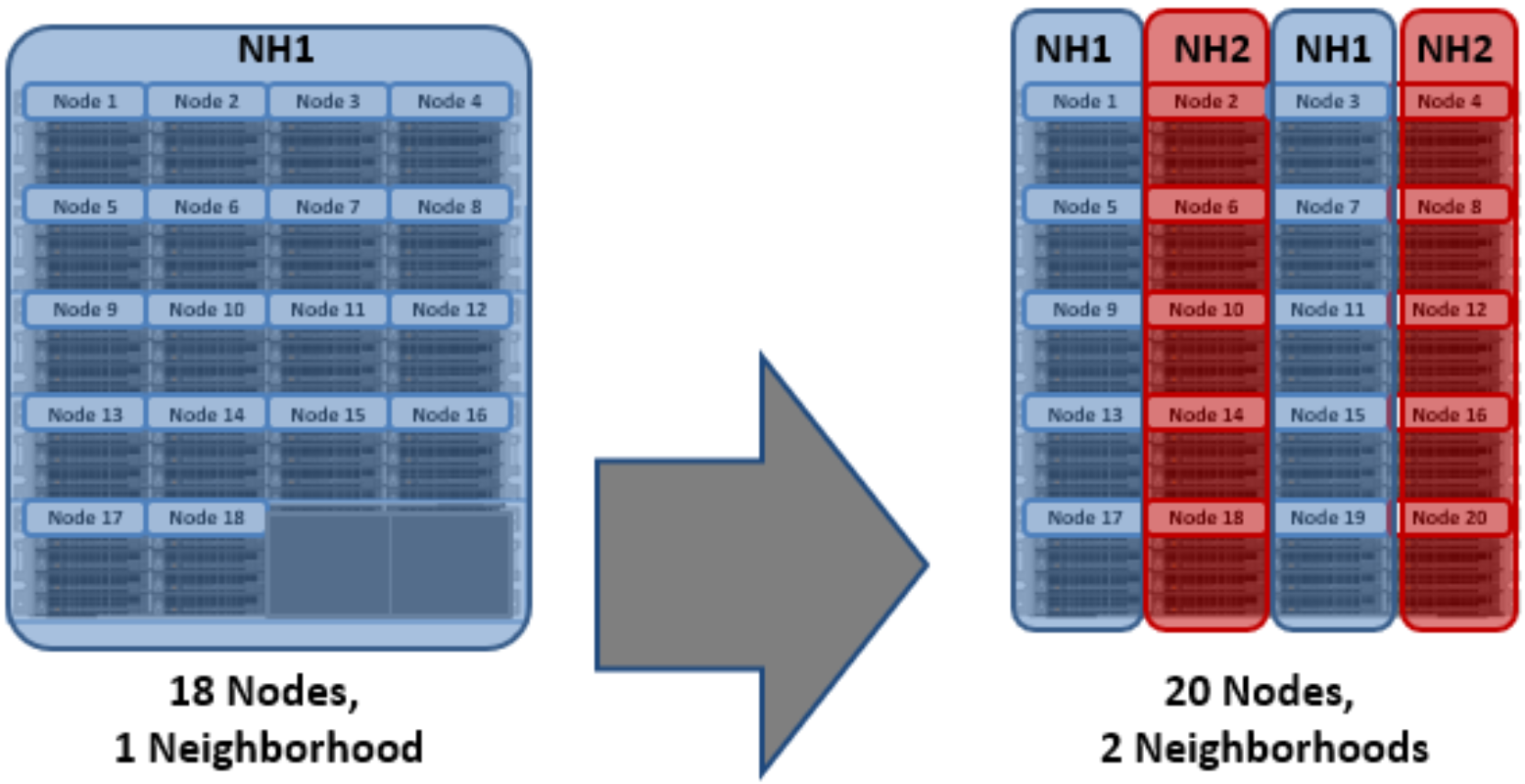
Figure 19. Split to two neighborhoods at twenty nodes
Partner node protection increases reliability because if both nodes go down, they are in different failure domains, so their failure domains only suffer the loss of a single node.
With chassis protection, when possible, each of the four nodes within a chassis will be placed in a separate neighborhood. Chassis protection becomes possible at 40 nodes, as the neighborhood split at 40 nodes enables every node in a chassis to be placed in a different neighborhood. As such, when a 38 node Gen6 cluster is expanded to 40 nodes, the two existing neighborhoods will be split into four 10-node neighborhoods:
Chassis protection ensures that if an entire chassis failed, each failure domain would only lose one node.
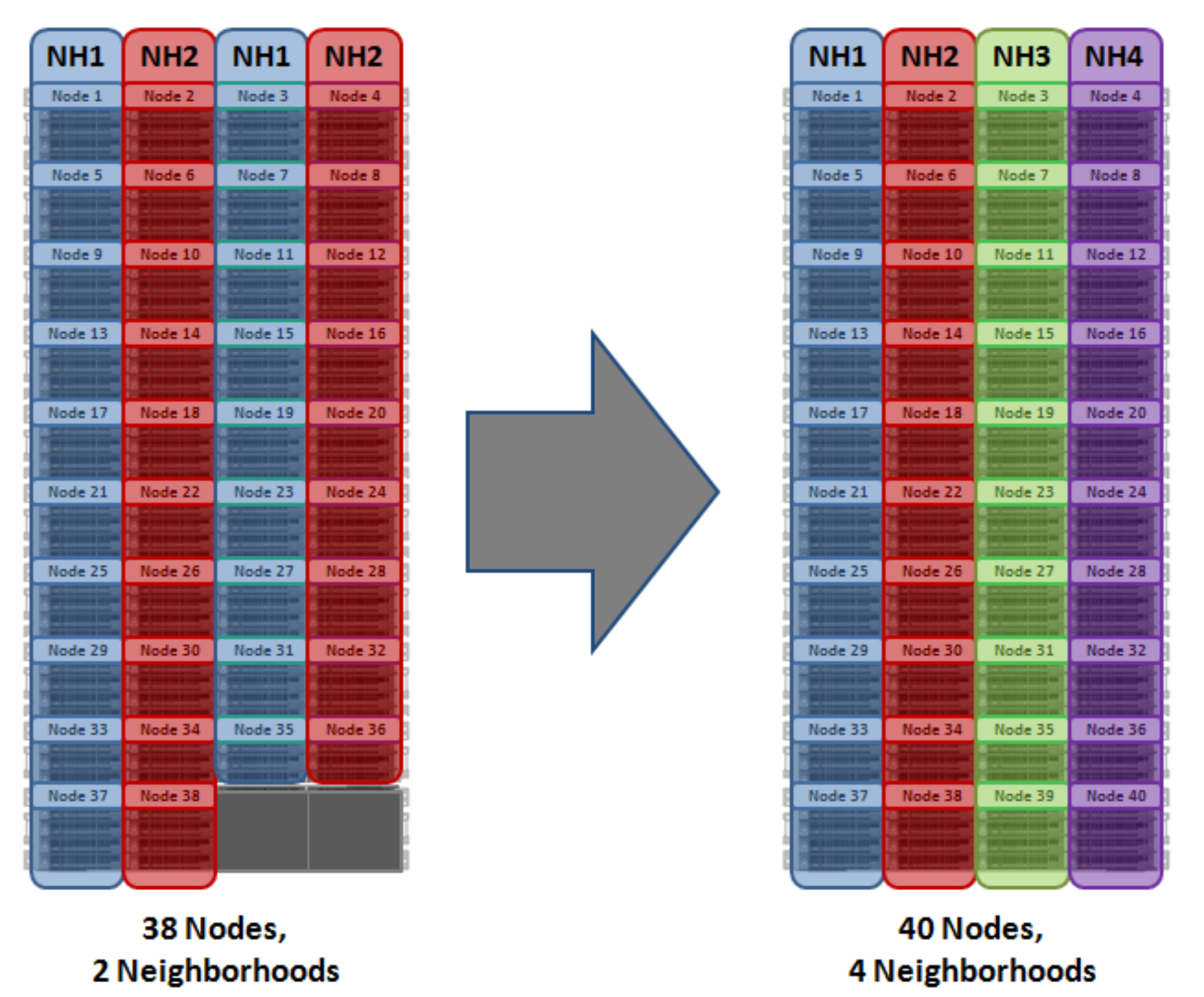
Figure 20. OneFS neighborhoods—Four neighborhood split
A 40 node or larger cluster with four neighborhoods, protected at the default level of +2d:1n can sustain a single node failure per neighborhood. This protects the cluster against a single Gen6 chassis failure.
Overall, a Gen6 platform cluster will have a reliability of at least one order of magnitude greater than previous generation clusters of a similar capacity as a direct result of the following enhancements:
- Mirrored Journals
- Smaller Neighborhoods
- Mirrored Boot Drives
Compatibility
Certain similar, but non-identical, node types can be provisioned to an existing node pool by node compatibility. OneFS requires that a node pool must contain a minimum of three nodes.
Due to significant architectural differences, there are no node compatibilities between the Gen6 platform, previous hardware generations, or the PowerScale nodes.
OneFS also contains an SSD compatibility option, which allows nodes with dissimilar capacity SSDs to be provisioned to a single node pool.
The SSD compatibility is created and described in the OneFS WebUI SmartPools Compatibilities list and is also displayed in the Tiers & Node Pools list.
When creating this SSD compatibility, OneFS automatically checks that the two pools to be merged have the same number of SSDs, tier, requested protection, and L3 cache settings. If these settings differ, the OneFS WebUI will prompt for consolidation and alignment of these settings.
More information is available in the SmartPools white paper.
Supported protocols
Clients with adequate credentials and privileges can create, modify, and read data using one of the standard supported methods for communicating with the cluster:
- NFS (Network File System)
- SMB/CIFS (Server Message Block/Common Internet File System)
- FTP (File Transfer Protocol)
- HTTP (Hypertext Transfer Protocol)
- HDFS (Hadoop Distributed File System)
- REST API (Representational State Transfer Application Programming Interface)
- S3 (Object Storage API)
For the NFS protocol, OneFS supports both NFSv3 and NFSv4, plus NFSv4.1 in OneFS 9.3. Also, OneFS 9.2 and later include support for NFSv3overRDMA.
On the Microsoft Windows side, the SMB protocol is supported up to version 3. As part of the SMB3 dialect, OneFS supports the following features:
- SMB3 Multi-path
- SMB3 Continuous Availability and Witness
- SMB3 Encryption
SMB3 encryption can be configured on a per-share, per-zone, or cluster-wide basis. Only operating systems that support SMB3 encryption can work with encrypted shares. These operating systems can also work with unencrypted shares if the cluster is configured to allow non-encrypted connections. Other operating systems can access non-encrypted shares only if the cluster is configured to allow non-encrypted connections.
The file system root for all data in the cluster is /ifs (the OneFS file system). This can be presented through the SMB protocol as an ‘ifs’ share (\\<cluster_name\ifs), through the NFS protocol as a ‘/ifs’ export (<cluster_name>:/ifs), and through the S3 protocol as an object interface.
Data is common between all protocols, so changes made to file content through one access protocol are instantly viewable from all others.
SmartQoS, introduced in OneFS 9.5, provides the ability to limit NFS3, NFS4, NFSoRDMA, S3 or SMB protocol operations per second (Protocol Ops), including mixed traffic to the same workload.
OneFS also provides full support for both IPv4 and IPv6 environments across the front-end Ethernet network(s), SmartConnect, and the complete array of storage protocols and management tools.
Additionally, OneFS CloudPools supports the following cloud providers’ storage APIs, allowing files to be stubbed out to several storage targets, including:
- Amazon Web Services S3
- Microsoft Azure
- Google Cloud Service
- Alibaba Cloud
- Dell ECS
- OneFS RAN (RESTful Access to Namespace)
More information is available in the CloudPools administration guide.
Non-disruptive operations - protocol support
OneFS contributes to data availability by supporting dynamic NFSv3 and NFSv4 failover and failback for Linux and UNIX clients, and SMB3 continuous availability for Windows clients. This ensures that when a node failure occurs, or preventative maintenance is performed, all in-flight reads and writes are handed off to another node in the cluster to finish its operation without any user or application interruption.
During failover, clients are evenly redistributed across all remaining nodes in the cluster, ensuring minimal performance impact. If a node is brought down for any reason, including a failure, the virtual IP addresses on that node is seamlessly migrated to another node in the cluster.
When the offline node is brought back online, SmartConnect automatically rebalances the NFS and SMB3 clients across the entire cluster to ensure maximum storage and performance utilization. For periodic system maintenance and software updates, this functionality allows for per-node rolling upgrades, affording full-availability throughout the duration of the maintenance window.
File filtering
OneFS file filtering can be used across NFS and SMB clients to allow or disallow writes to an export, share, or access zone. This feature prevents certain types of file extensions to be blocked, for files which might cause security problems, productivity disruptions, throughput issues or storage clutter. Configuration can be either using an exclusion list, which blocks explicit file extensions, or an inclusion list, which explicitly allows writes of only certain file types.