
Level 3 cache
Level 3 cache
-
Also known as SmartFlash, level 3 (L3) cache is a subsystem which caches evicted L2 cache blocks on one or more SSDs on the node owning the L2 cache blocks. L3 cache is optional and requires one or more SSDs to function. Unlike with L1 and L2 cache, not all nodes or clusters have an L3 cache because SSDs must be present and exclusively reserved and configured for caching use. Conversely, all-flash nodes do not need an L3 cache because all data and metadata blocks already reside on SSDs.
OneFS L3 cache serves as a large, cost-effective method of extending of main memory per node from gigabytes to terabytes. This method allows clients to retain a larger working set of data in cache before being forced to retrieve data from spinning disk through a higher-latency hard drive operation.
At a high level, L3 cache serves as a cost-effective extension of main memory per node, from gigabytes to terabytes. This extension allows clients to manipulate a larger working set of data before forcing a cache miss to higher-latency spinning disks. The L3 cache is populated with “interesting” L2 cache blocks that are being dropped from memory as a result of L2 cache’s Least Recently Used (LRU) eviction algorithm.
Blocks evicted from L2 cache are candidates for inclusion in L3 cache, and a filter is employed to reduce the quantity and increase the value of incoming blocks. Because L3 cache is a first in, first out (FIFO) cache, filtering is performed ahead of time. By selecting blocks that are more likely to be read again, L3 cache can both limit SSD churn and enhance the quality of the L3 cache contents.
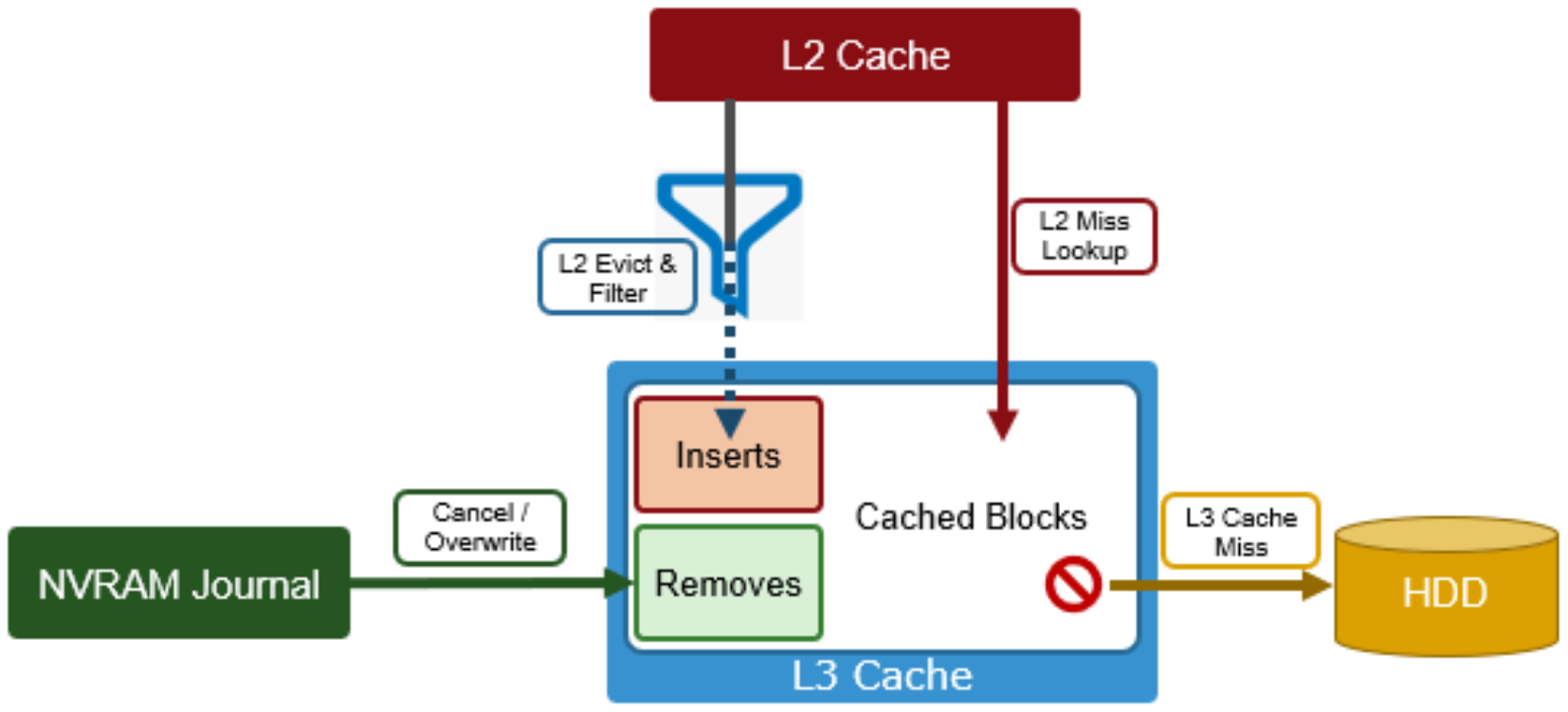
Figure 3. OneFS L3 cache operation
The L3 cache filter uses a few heuristics to decide which candidate blocks will go to L3 cache. These heuristics include:
- L3 cache prefers metadata/inode to data blocks.
- If a block is a random read (that is, there are no neighboring blocks on this disk in L2 cache), it is always in L3 cache.
- If the block is part of a cluster of blocks (contiguous on disk) smaller than 16 blocks and has been accessed twice or more, it may be in L3 cache.
- If the block is part of a sequential cluster of 16 or more blocks (128 KB), it is not evicted to L3 cache.
- Prefetched blocks are not considered to be user read blocks unless they are sent to the client.
The principle here is that the per-block cost of re-reading a sequential cluster of blocks from disk is lower than performing random reads from disk. As such, the L3 cache can be most effective, per capacity, by addressing random reads.
Also, any uncached Job Engine metadata requests always come from disk, and bypass L3 cache. That way they do not displace user-cached blocks from L3 cache.
- As new versions are written, the journal notifies L3 cache, which invalidates and removes the dirty blocks.
- If its SSDs become full, L3 cache will prefer to evict user I/O data before metadata blocks.
Unlike RAM-based caches, because L3 cache is based on persistent flash storage, once the cache is populated, or warmed, it is highly durable and persists across node reboots.
To be beneficial, L3 cache must provide performance gains in addition to the memory cost it imposes on L2. To achieve this benefit, L3 cache uses a custom log-based file system with an index of cached blocks. The SSDs provide excellent random read access characteristics, such that a hit in L3 cache is only slightly slower than a hit in L2 cache.
Testing has proven that a streaming write pattern is optimal for both reliable drive-write performance, and to extend drive longevity. Both data and metadata blocks are written in a log pattern across the entire disk, wrapping around when the drive is full. These streaming writes assist the drive’s wear-leveling controller resulting in increased drive longevity.
To use multiple SSDs for cache effectively and automatically, L3 cache uses a consistent hashing approach to associate an L2 cache block address with one L3 cache SSD. If an L3 drive fails, a portion of the cache will obviously disappear, but the remaining cache entries on other drives will still be valid. Before a new L3 drive may be added to the hash, some cache entries must be invalidated.
The following diagram illustrates how clients interact with the full OneFS read cache infrastructure and the write coalescer. L1 cache still interacts with the L2 cache on any node it requires, and the L2 cache interacts with both the storage subsystem and L3 cache. L3 cache is stored on an SSD within the node and each node in the same node pool has L3 cache enabled. The diagram also illustrates a separate node pool where L3 cache is not enabled. This node pool either does not contain the required SSDs, or has L3 cache disabled, with the SSDs being used for a filesystem-based SmartPools SSD data or metadata strategy.
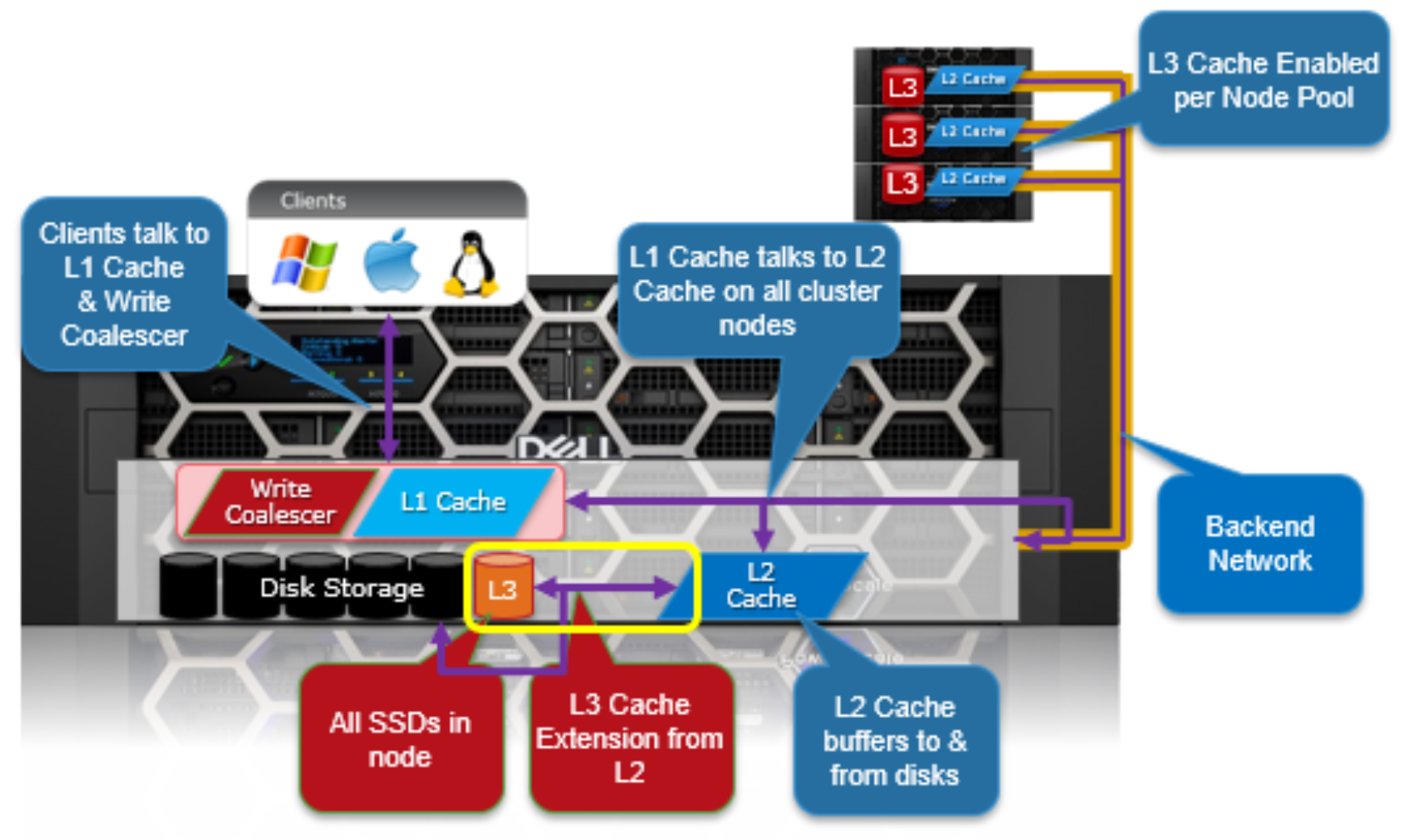
Figure 4. OneFS L1, L2, and L3 caching architecture