
Job Engine
Job Engine
-
The Job Engine includes a comprehensive check-pointing system that allows jobs to be paused and resumed, in addition to stopped and started. The Job Engine framework also includes an adaptive impact management system, drive-sensitive impact control, and the ability to run multiple jobs at once.
The PermissionRepair job consists of a single phase, which is composed of several work chunks, or tasks. The tasks, which consist of multiple individual work items, are divided and load balanced across the nodes in the cluster. Successful execution of a work item produces an item result that might contain a count of the number of retries required to repair a file, plus any errors that occur during processing.
PermissionRepair performs a directory tree walk. It works similarly to common UNIX utilities, such as the find utility –in a far more efficient, distributed way. For parallel execution, the various job tasks are each assigned a separate subdirectory tree. Unlike LIN scans, tree walks might prove to be heavily unbalanced, due to varying subdirectory depths and file counts.
The Job Engine is based on a delegation hierarchy consisting of coordinator, director, manager, and worker processes.
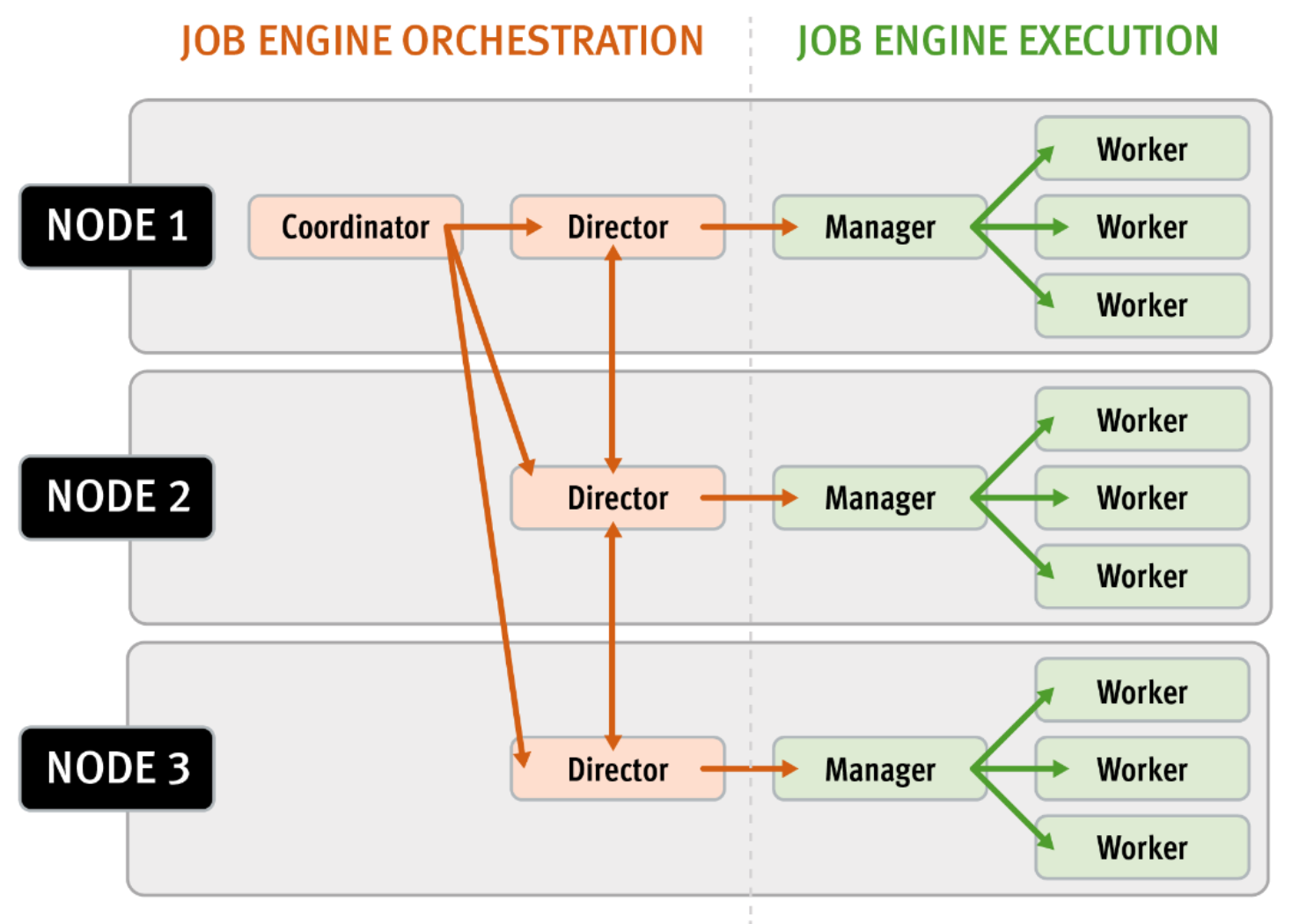
Figure 1. OneFS Job Engine distributed work allocation model
Once the work is initially allocated, the Job Engine uses a shared work distribution model to perform the work. The coordinator process, which runs on one of the nodes in a cluster, handles the Job Engine’s orchestration.
While the individual nodes manage the work item allocation, the coordinator node takes control, divides the job, and evenly distributes the resulting tasks across the nodes in the cluster. The coordinator is also responsible for starting and stopping jobs, and for processing work results as they are returned during the execution of a job.
Each node in the cluster has a Job Engine director process, which runs continuously and independently in the background. The director process is responsible for monitoring, governing, and overseeing all Job Engine activity on a particular node, constantly waiting for instruction from the coordinator to start a new job. The director process serves as a central point of contact for all the manager processes running on a node, and as a liaison with the coordinator process across nodes.
The manager process is responsible for arranging the flow of tasks and task results throughout the duration of a job. The manager processes both request and exchange work, and supervises the worker threads assigned to them. At any point in time, each node in a cluster can have up to three manager processes, one for each job currently running. These managers are responsible for overseeing the flow of tasks and task results.
Each manager controls and assigns work items to multiple worker threads working on items for the designated job. Every worker thread is given a task, if available, which it processes item by item until the task is complete or the manager unassigns the task. The isi job statistics view CLI command can provide the status of the nodes’ workers. In addition to the number of current worker threads per node, a sleep to work (STW) ratio average is also provided, giving an indication of the worker thread activity level on the node.
The Job Engine allocates a specific number of threads to each node by default, controlling the impact of a workload on the cluster. If little client activity occurs, more worker threads are spun up to allow more work, up to a predefined worker limit. For example, the worker limit for a:
- Low-impact job might allow one or two threads per node to be allocated.
- Medium-impact job might allow from four to six threads to be allocated.
- High-impact job might allow a dozen or more threads to be allocated.
When this worker limit is reached (or before, if client load triggers impact management thresholds first), worker threads are throttled back or terminated.
As jobs are processed, the coordinator consolidates the task status from the constituent nodes, and periodically writes the results to checkpoint files. These checkpoint files allow jobs to be paused and resumed, either proactively, or if there is a cluster outage. For example, if the node on which the Job Engine coordinator was running goes offline for any reason, a new coordinator is automatically started on another node. This new coordinator reads the last consistency checkpoint file. Job control and task processing resume across the cluster from where it left off, and no work is lost.
The Job Engine resource monitoring and execution framework allows jobs to be throttled based on both CPU and disk I/O metrics. The granularity of the resource utilization monitoring data provides the coordinator process with visibility into exactly what is generating IOPS on any drive across the cluster. This level of insight allows the coordinator to make precise determinations about exactly where and how impact control is best applied. The coordinator itself does not communicate directly with the worker threads, but rather with the director process. The director process then instructs a node’s manager process for a specific job to cut back threads.
Certain jobs, if left unchecked, can consume vast quantities of a cluster’s resources, contending with and impacting client I/O. To counteract this impact, the Job Engine employs a comprehensive work throttling mechanism that can limit the rate at which individual jobs can run. Throttling is employed at a per-manager process level, so job impact can be managed both granularly and gracefully.
Further information is available in the Dell PowerScale OneFS Job Engine White Paper.