
Data orchestration challenge – Object storage is not file storage
Data orchestration challenge – Object storage is not file storage
-
Comparing object storage and file storage
There is still confusion about the differences between object and file storage. Cloud native architectures rely on object storage to store data, while most client systems and humans interact directly with file storage. There are some important differences that are worth noting.
PowerScale OneFS is a file storage platform. Files are accessed using protocols such as NFS or SMB. (There are others too, but we will stick with these protocols for now.) The storage is organized in a hierarchy of directories, subdirectories, and files.
Files stored in PowerScale OneFS (and other file storage) can be created, read, deleted, and modified. For instance, a 100GB file could have several bytes in the middle modified without having to rewrite the entire file.
PowerScale OneFS is optimized for high-performance data access. This performance is critical for workflows such as video edit, where multiple high throughput streams of video are accessed simultaneously. Performance is also crucial for render workflows where thousands of render processes may be accessing the PowerScale cluster simultaneously.
Object storage, such as Dell Elastic Cloud Storage (ECS) and Amazon S3, works differently. The data in an object store is accessed by object APIs. APIs are ideal for systems interacting with systems. APIs are less friendly for human to system interaction. There is no file hierarchy, data is stored in a flat bucket with unique identifiers, though many object stores use long object IDs to simulate the structure of file storage.
These objects can be created, read, or deleted, but objects cannot be modified. To revisit the example above, if a large 100 GB object needs a few bytes in the middle modified, the entire object needs to be rewritten to the storage.
While there are some performant object storage platforms (such as the all-flash ECS EFX900), in general object storage is not designed for high performance. Object storage is designed for massive scale. While it is possible to scale out file storage to hundreds of petabytes, that kind of massive capacity is the domain of object storage. ECS and some other object stores also have multitenancy capabilities. Multitenancy allows for data ingested in one location to be read natively in another location with the object storage platform handling replication and consistency in the background.
Object storage in media workflows
Object storage in media workflows has been rapidly evolving. Historically, object storage was an archive target, and archive is still a common use case. However, with the advent of cloud native workflows, object storage is fast becoming the first place where video data lands.
This shift in paradigm aligns with the Movie Labs 2030 Vision for content creation. One of the visions outlined in the paper is that production data should go the “cloud” as soon as possible. “Cloud” here is defined as a shared pool of storage and compute resources, be it private data center, co-location facility, or hyperscalar.
There are advantages for having video data land on object storage first. The low cost and massive scale of object storage easily accommodates the rapidly increasing volume of media production data. And depending on the multitenancy configuration of the object store, that data may now be accessible (or at least visible) in multiple locations quickly.
However, for humans to interact with that data directly and for most media applications, file storage is required.
File storage in media workflows
File storage is the working storage for most media applications. It has the file and folder hierarchy that humans are familiar with. OneFS PowerScale is file storage, and with its high throughput and low latency, PowerScale is suited to the many real-time operations in content creation.
File storage may be near the object store, such as when ECS and PowerScale are in the same data center. It may be cloud adjacent, such as a co-location facility with direct connects into public cloud providers. Or the object store may be in geographically diverse locations. The trick is to move data only when value is added.
Right tool for the job
Wherever the data lands initially, orchestration is crucial. Data that originates on object storage needs to be accessible natively by systems that can speak object APIs. Also, some subset of data needs to be moved to file storage for further processing. Production data that originates on file storage similarly needs native access. That file data will need to be moved to object storage for long-term retention and to make it accessible to globally distributed resources.
Content creation workflows are spread across multiple teams working in many locations. Multisite productions require distributed storage ecosystems that can span geographies. This architecture is well suited to a core of object storage as the “central source of truth”. Pools of highly performant file storage serve teams in their various global locations. Deciding when, where, and how to move data is crucial for success.
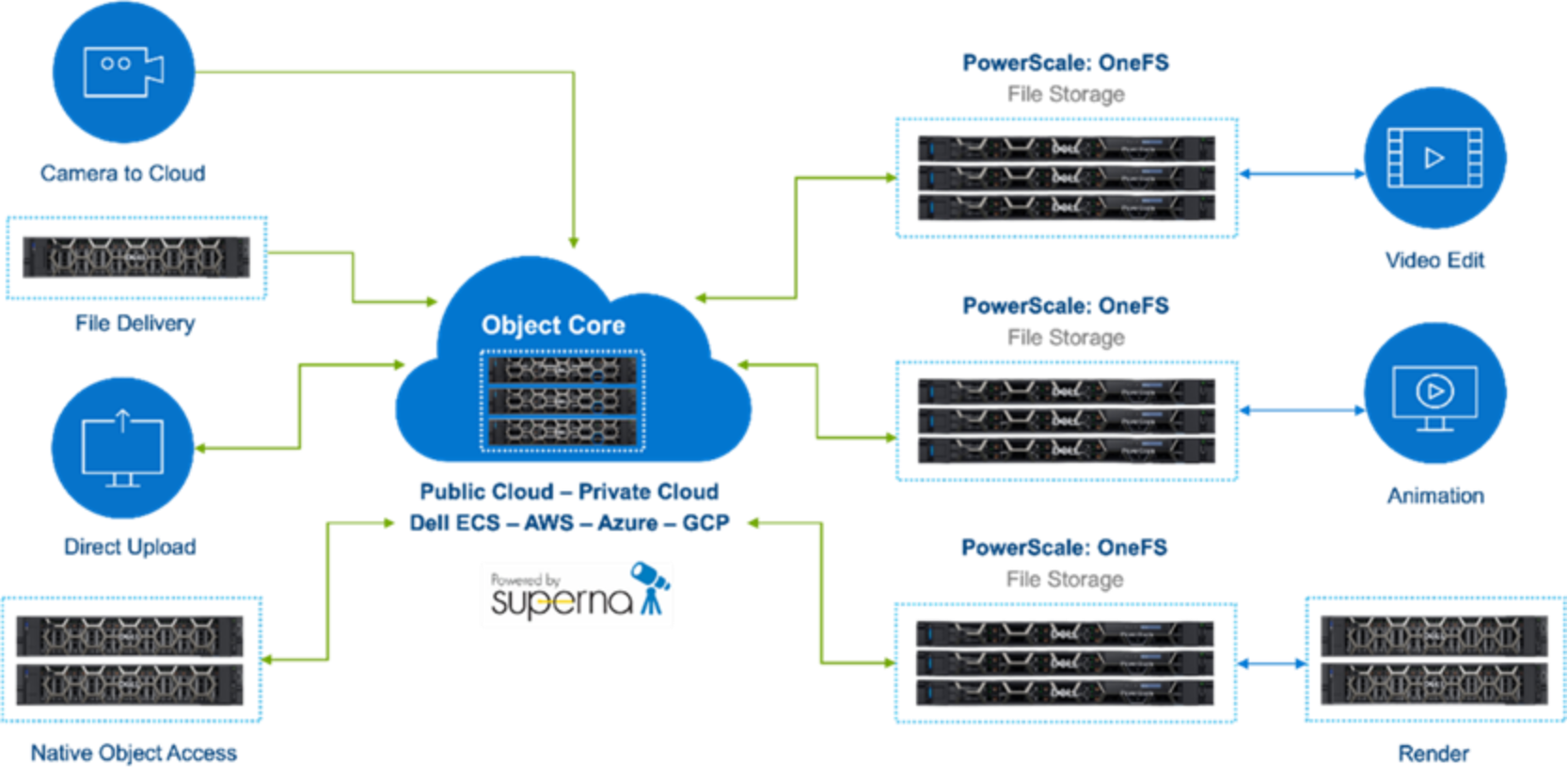
Figure 2. Object core with performant OneFS file edge