
PowerScale OneFS Best Practices
Executive summary
Data layout recommendations
Node hardware recommendations
OneFS data protection
Data tiering and layout recommendations
Network recommendations
Protocol recommendations
New cluster best practices
Data availability and protection recommendations
Data management recommendations
OneFS data reduction best practices
Data immutability recommendations
OneFS security hardening
Permissions, authentication, and access control recommendations
Job Engine recommendations
Cluster management recommendations
Best practices checklist
Summary
User action jobs
User action jobs
-
Storage administrators run user action jobs jobs directly to accomplish some data management goal. Examples include parallel tree deletes and permissions maintenance.
The Job Engine allows up to three jobs to be run simultaneously. This concurrent job process is governed by the following criteria:
- Job priority.
- Exclusion sets—These jobs cannot run together (FlexProtect and AutoBalance).
- Cluster health—Most jobs cannot run when the cluster is in a degraded state.
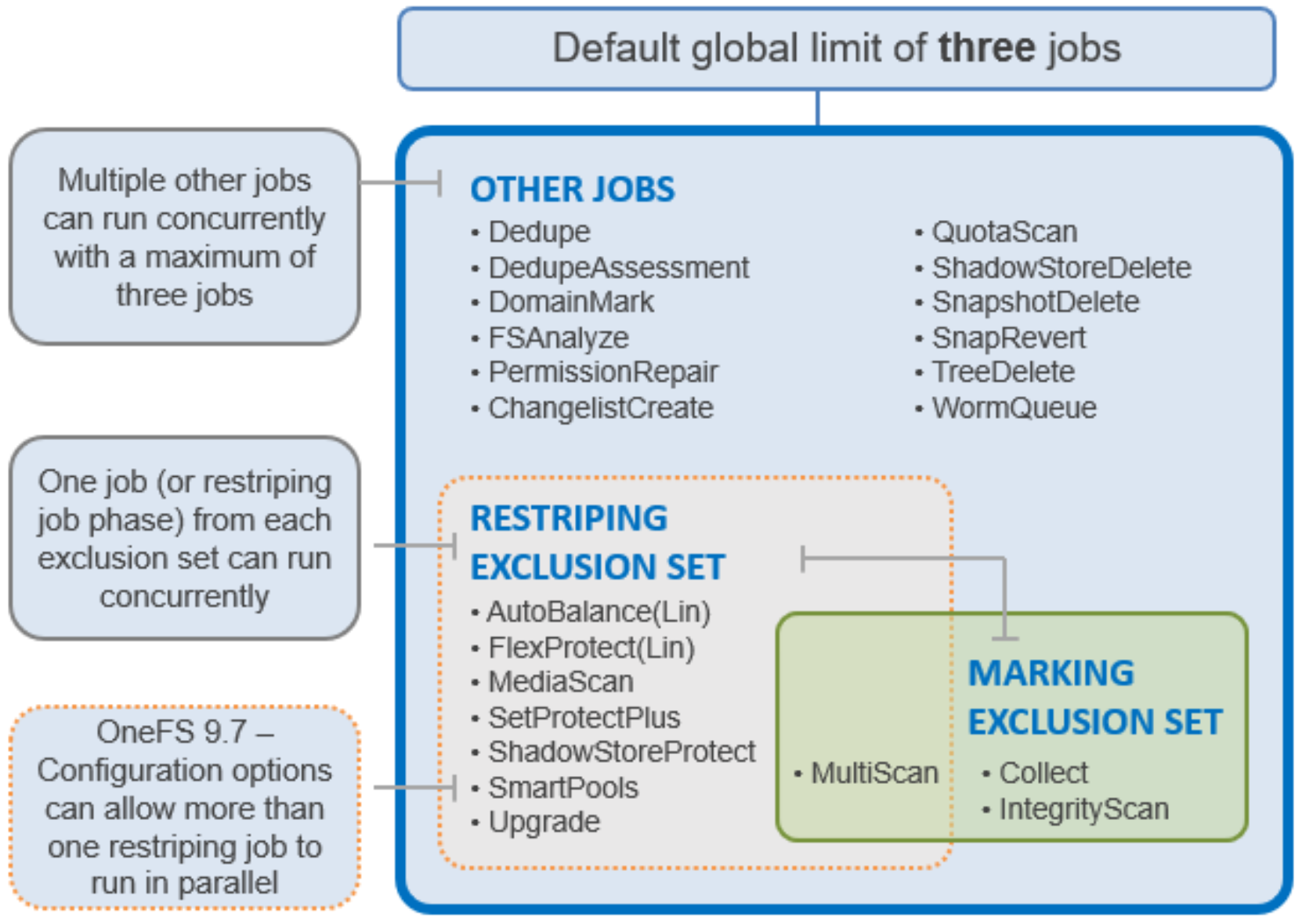
Figure 19. Job Engine exclusion sets
The default, global limit of three jobs does not include jobs for striping or marking; one job from each of those categories can also run concurrently.
For optimal cluster performance, we recommend observing the following Job Engine best practices.
- Schedule jobs to run during the cluster’s low usage hours—overnight, weekends.
- Where possible, use the default priority, impact, and scheduling settings for each job.
- To complement the four default impact profiles, create additional profiles such as “daytime_medium”, “after_hours_medium”, “weekend_medium”, to fit specific environment needs.
- Ensure the cluster, including any individual node pools, is less than 90% full, so performance is not impacted and that there is always space to reprotect data in the event of drive failures. Also enable virtual hot spare (VHS) to reserve space in case you need to smartfail devices.
- Configure and pay attention to alerts. Set up event notification rules so that you will be notified when the cluster begins to reach capacity thresholds. Make sure to enter a current email address to ensure you receive the notifications.
- It is recommended not to disable the snapshot delete job. In addition to preventing unused disk space from being freed, disabling the snapshot delete job can cause performance degradation.
- Delete snapshots in order, beginning with the oldest. Do not delete snapshots from the middle of a time range. Newer snapshots are mostly pointers to older snapshots, and they look larger than they really are.
- If you need to delete snapshots and there are down or smartfailed devices on the cluster, or the cluster is in an otherwise “degraded protection” state, contact Dell Technical Support for assistance.
- Only run the FSAnalyze job if you are using InsightIQ and/or require file system analytics. FSAnalyze creates data for InsightIQ file system analytics tools, providing details about data properties and space usage within /ifs. Unlike SmartQuotas, FSAnalyze only updates its views when the FSAnalyze job runs. Because FSAnalyze is a relatively low-priority job, higher-priority jobs can sometimes preempt it, so it can take a long time to gather all the data.
- Schedule deduplication jobs to run every 10 days or so, depending on the size of the dataset.
- SmartDedupe will automatically run with a “low-impact” Job Engine policy. However, this policy can be manually reconfigured.
- In a heterogeneous cluster, tune job priorities and impact policies to the level of the lowest performance tier.
- Before running a major (nonrolling) OneFS upgrade, allow active jobs to complete, where possible, and cancel out any outstanding running jobs.
- Before running TreeDelete, ensure there are no quotas policies set on any directories under the root level of the data for deletion. TreeDelete cannot delete a directory if a quota has been applied to it.
- If FlexProtect is running, allow it to finish completely before powering down any nodes or the entire cluster. While shutting down the cluster during restripe will not hurt anything directly, it does increase the risk of a second device failure before FlexProtect finishes reprotecting data.
- When using metadata read or metadata write acceleration, always run a job with the *LIN suffix where possible. For example, favor the FlexProtectLIN job, rather than the regular FlexProtect job.
- TreeDelete can delete a directory to which a quota has been applied using the ‘--delete-quota’ flag. For example: #isi job start TreeDelete --paths=/ifs/quota –delete quota
- Avoid data movement as much as possible during daily operations. SmartPools data placement requires resources which can contend with client IO. With a mixed node cluster where data tiering is required, the recommendation is to schedule the SmartPools job to run during off-hours (nights and/or weekends) when the client activity is at its lowest.