
SmartDedupe best practices
SmartDedupe best practices
-
OneFS SmartDedupe maximizes the storage efficiency of a cluster by decreasing the amount of physical storage required to house an organization’s data. Efficiency is achieved by scanning the on-disk data for identical blocks and then eliminating the duplicates. This approach is commonly referred to as post-process, or asynchronous, deduplication.
After duplicate blocks are discovered, SmartDedupe moves a single copy of those blocks to a special set of files known as shadow stores. During this process, duplicate blocks are removed from the actual files and replaced with pointers to the shadow stores.
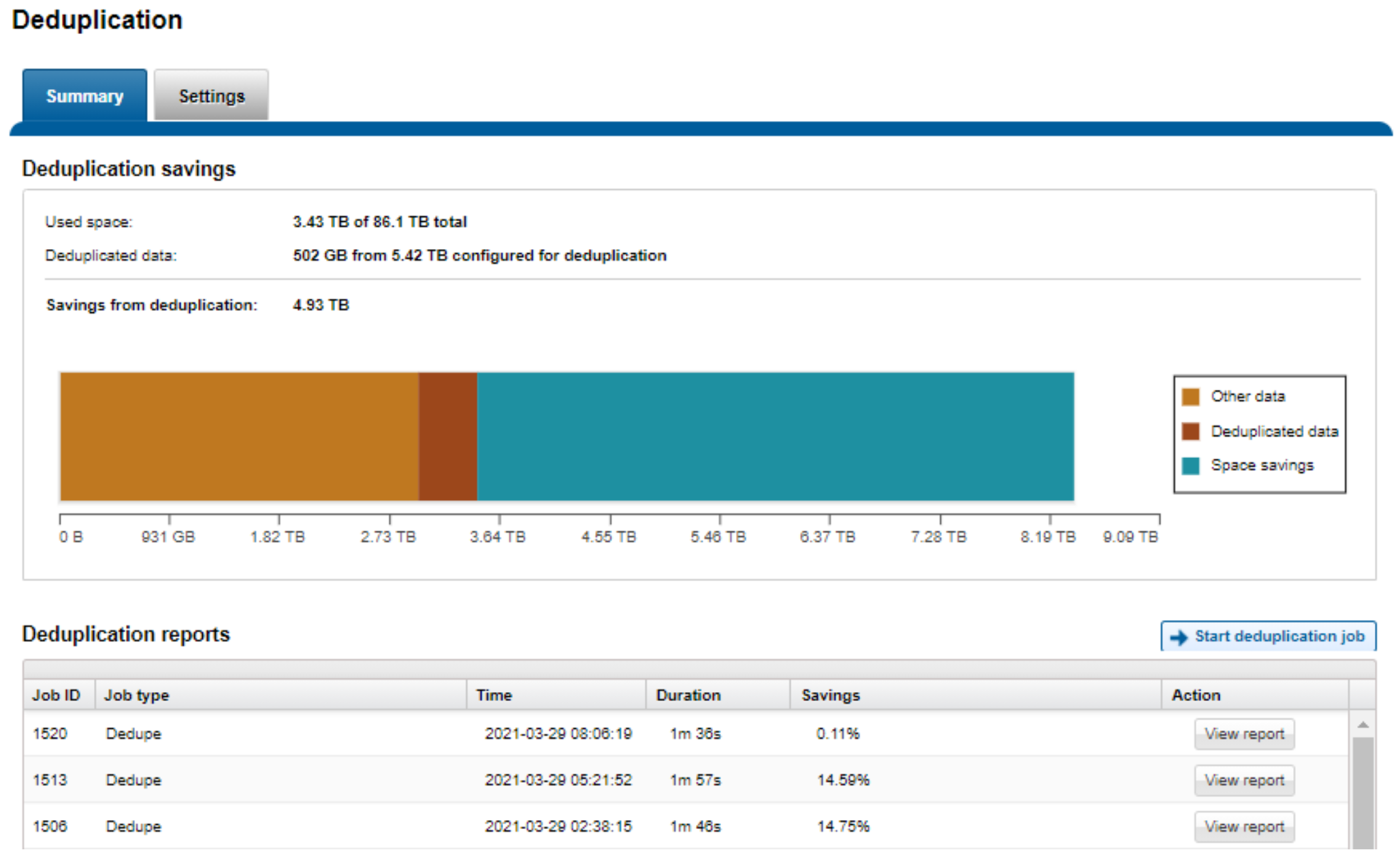
Figure 16. SmartDedupe capacity savings
For optimal cluster performance, we recommend the following SmartDedupe best practices. Some of this information is discussed elsewhere in this paper.
- Deduplication is typically applied to datasets with a lower rate of change – for example, file shares, home directories, and archive data.
- Enable SmartDedupe to run at subdirectory levels below /ifs.
- Avoid adding more than ten subdirectory paths to the SmartDedupe configuration policy,
- SmartDedupe is ideal for home directories, departmental file shares, and warm and cold archive datasets.
- Run SmartDedupe against a smaller sample dataset first to evaluate performance impact against space efficiency.
- Schedule deduplication to run during the cluster’s low usage hours—overnight or weekends. By default, the SmartDedupe job runs automatically.
- After the initial deduplication job has completed, schedule incremental deduplication jobs to run every two weeks or so, depending on the size and rate of change of the dataset.
- Always run SmartDedupe with the default ‘low’ impact Job Engine policy.
- Run the deduplication assessment job on a single root directory at a time. If multiple directory paths are assessed in the same job, you will not be able to determine which directory should be deduplicated.
- When replicating deduplicated data, to avoid running out of space on target, verify that the logical data size (the amount of storage space saved plus the actual storage space consumed) does not exceed the total available space on the target cluster.
Bear in mind that deduplication is not free. There is always trade-off between cluster resource consumption (CPU, memory, disk), and the benefit of increased space efficiency.