
In-line data reduction best practices
In-line data reduction best practices
-
OneFS in-line data reduction is available exclusively on the PowerScale F910, F900, F810, F710, F600, F210, F200, H700/7000, H5600, and A300/3000 platforms. The OneFS architecture has the following principal components:
- Data Reduction Platform
- Compression Engine and Chunk Map
- Zero block removal phase
- Deduplication In-memory Index and Shadow Store Infrastructure
- Data Reduction Alerting and Reporting Framework
- Data Reduction Control Path
The in-line data reduction write path consists of three main phases:
- Zero Block Removal
- In-line Deduplication
- In-line Compression
If both in-line compression and deduplication are enabled on a cluster, zero block removal is performed first, followed by deduplication, and then compression. This order allows each phase to reduce the scope of work each subsequent phase.

Figure 17. In-line data reduction workflow
OneFS provides software-based compression for the F910, F900, F710, F600, F210, F200, and H5600 platform, as fallback in the event of an F810 hardware failure, and in a mixed cluster for use in nodes without a hardware offload capability. Both hardware and software compression implementations are DEFLATE compatible.
The F810 platform includes a compression offload capability, with each node in an F810 chassis containing a Mellanox Innova-2 Flex Adapter. Thus, the Mellanox adapter transparently performs compression and decompression with minimal latency, and avoids the need for consuming a node’s expensive CPU and memory resources.
The OneFS hardware compression engine uses zlib, with a software implementation of igzip as fallback in the event of a compression hardware failure. OneFS employs a compression chunk size of 128 KB, with each chunk consisting of sixteen 8 KB data blocks. This chunk size is optimal because it is the same size that OneFS uses for its data protection stripe units, providing simplicity and efficiency, by avoiding the overhead of additional chunk packing.
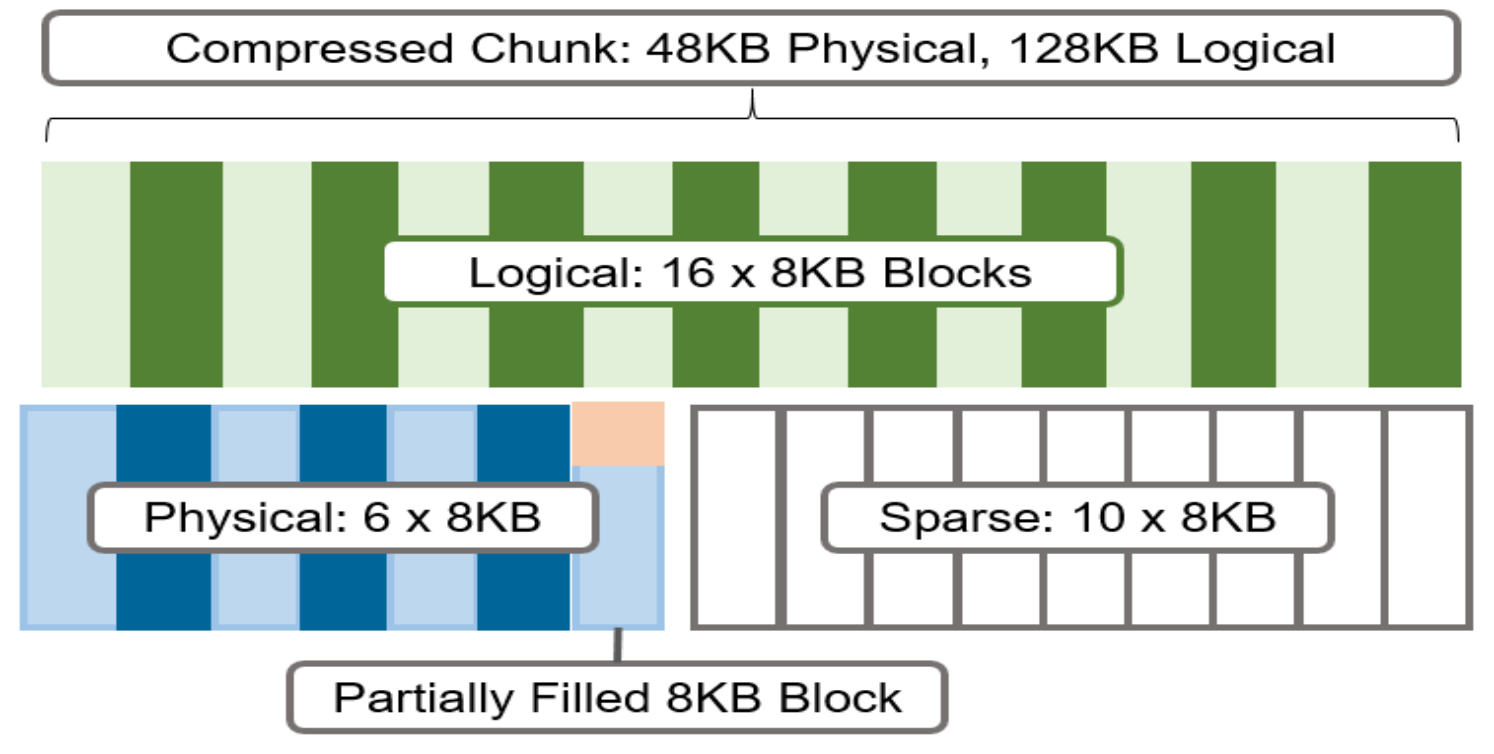
Figure 18. Compression chunks and OneFS transparent overlay
Consider the preceding diagram. After compression, this chunk is reduced from sixteen to six 8 KB blocks in size, which means that this chunk is now physically 48 KB in size. OneFS provides a transparent logical overlay to the physical attributes. This overlay describes whether the backing data is compressed or not and which blocks in the chunk are physical or sparse, such that file system consumers are unaffected by compression. As such, the compressed chunk is logically represented as 128 KB in size, regardless of its actual physical size.
Efficiency savings must be at least 8 KB (one block) in order for compression to occur, otherwise that chunk or file will be passed over and remain in its original, uncompressed state. For example, a file of 16 KB that yields 8 KB (one block) of savings would be compressed. Once a file has been compressed, it is then FEC protected.
Compression chunks will never cross node pools. This avoids the need to decompress or recompress data to change protection levels, perform recovered writes, or otherwise shift protection-group boundaries.
For optimal cluster performance, we recommend the following in-line compression best practices. Some of this information is provided elsewhere in this paper.
- In-line data reduction is for F910, F900, F810, F710, F600, F210, F200, and H5600 installations only. Legacy Isilon F800 nodes cannot be upgraded or converted to F810 nodes.
- Run the assessment tool on a subset of the data to be compressed/deduplicated.
- When replicating compressed and/or deduplicated data, to avoid running out of space on target, verify that the logical data size (the amount of storage space saved plus the actual storage space consumed) does not exceed the total available space on the target cluster.
- In general, additional capacity savings may not warrant the overhead of running SmartDedupe on node pools with in-line deduplication enabled.
- Data reduction can be disabled on a cluster if the overhead of compression and deduplication is considered too high and/or performance is impacted.
- The software data reduction fall back option is less performant, more resource intensive, and less efficient (lower compression ratio) that hardware data reduction. Consider removing F810 nodes with failing offload hardware from the node pool.
- Run the deduplication assessment job on a single root directory at a time. If multiple directory paths are assessed in the same job, you will not be able to determine which directory should be deduplicated.