
Front-end connectivity considerations
Front-end connectivity considerations
-
For most workflows, the recommendation is to configure at least one front-end 25, 40, or 100 GbE connection per node to support the high levels of network utilization that take place. Archive nodes and cold data workloads can sometimes be fine with 10 Gb Ethernet connections per node.
A best practice is to bind multiple IP addresses to each node interface in a SmartConnect subnet pool. Generally, optimal balancing and failover are achieved when the number of addresses allocated to the subnet pool equals N * (N – 1), where N equals the number of node interfaces in the pool. For example, if a pool is configured with a total of five node interfaces, the optimal IP address allocation would total 20 IP addresses (5 * (5 – 1) = 20) to allocate four IP addresses to each node interface in the pool. For larger-scaled clusters, there is a practical number of IP addresses that is a good compromise between N * (N -1) approach and a single IP per node approach. Example: for a 35-node cluster, 34 IPs per node may not be necessary, depending on workflow.
Assigning each workload or data store to a unique IP address enables OneFS SmartConnect to move each workload to one of the other interfaces. This minimizes the additional work that a remaining node in the SmartConnect pool must absorb and ensuring that the workload is evenly distributed across all the other nodes in the pool.
For a SmartConnect pool with four-node interfaces, using the N * (N – 1) model will result in three unique IP addresses being allocated to each node. A failure on one node interface will cause each of that interface’s three IP addresses to fail over to a different node in the pool. This ensuring that each of the three active interfaces remaining in the pool receives one IP address from the failed node interface. If client connections to that node were evenly balanced across its three IP addresses, SmartConnect distributes the workloads to the remaining pool members evenly.
For more information, see the Dell PowerScale: Network Design Considerations white paper.
Optimal network settings
Jumbo frames, where the maximum transmission unit (MTU) is set to 9000 bytes, yield slightly better throughput performance with slightly less CPU usage than standard frames, where the MTU is set to 1500 bytes. For example, jumbo frames can provide about 5 percent better throughput and about 1 percent less CPU usage.
For more information, see the Dell PowerScale: Network Design Considerations white paper.
Network isolation
OneFS optimizes storage performance by designating zones to support specific workloads or subsets of clients. Different network traffic types can be isolated on separate subnets using SmartConnect pools.
For large clusters, partitioning the cluster’s networking resources and allocating bandwidth to each workload minimizes the likelihood that heavy traffic from one workload will affect network throughput for another. SyncIQ replication and NDMP backup traffic, in particular, can benefit from its own set of interfaces, separate from user and client I/O load.
Many customers as a best practice create separate SmartConnect subnets for the following traffic isolation:
- Workflow separation.
- SyncIQ Replication.
- NDMP backup on target cluster.
- Service Subnet for cluster administration and management traffic.
- Different node types and performance profiles.
OneFS includes a ‘Groupnets’ networking object as part of the support for multitenancy. Groupnets sit above subnets and pools and allow separate Access Zones to contain distinct DNS settings.
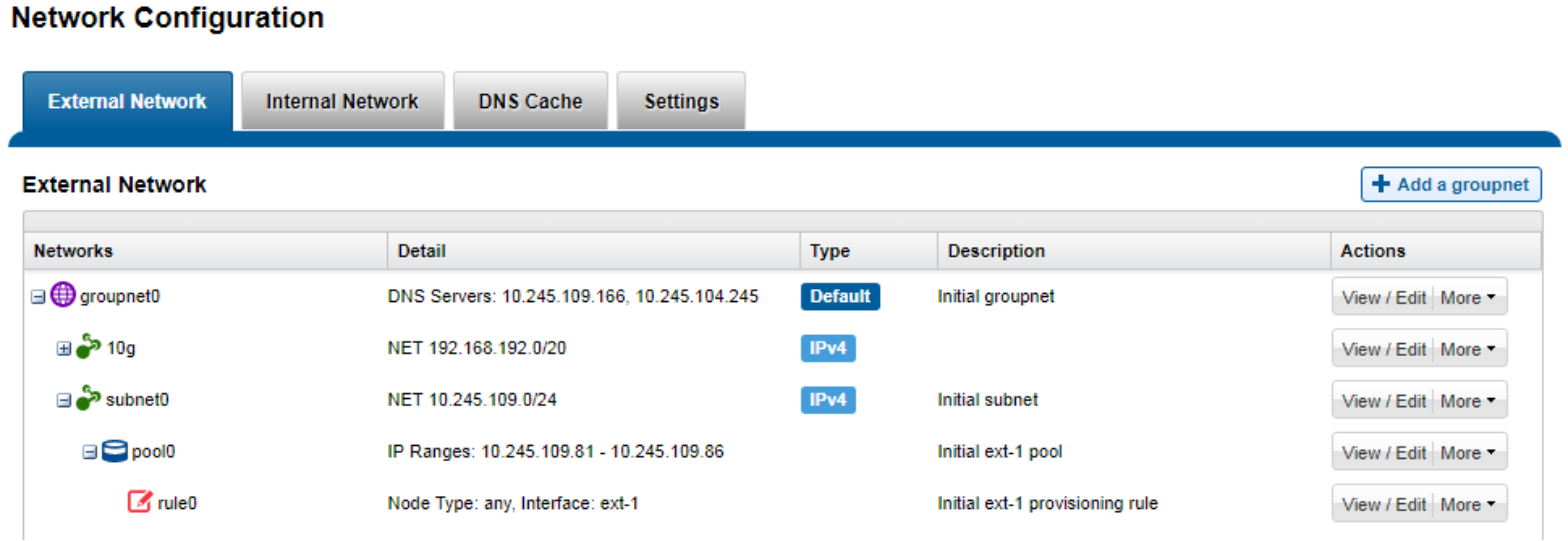
Figure 10. OneFS network object hierarchy
Connection-balancing and failover policies
By default, OneFS SmartConnect balances connections among nodes by using a round-robin policy and a separate IP pool for each subnet. A SmartConnect license adds advanced balancing policies to evenly distribute CPU usage, client connections, or throughput. It also lets you define IP address pools to support multiple DNS zones in a subnet.
Table 5. Example of usage scenarios and recommended balancing options
Load-balancing policy
General of other
Few clients with extensive usage
Many persistent NFS and SMB connections
Many transitory connections (HTTP, FTP, S3)
NFS automounts or UNC paths
Round Robin
Connection Count *
CPU Utilization *
Network Throughput *
* Metrics are gathered every 5 seconds for CPU utilization and every 10 seconds for Connection Count and Network Throughput. In cases where many connections are created at the same time, these metrics may not be accurate, creating an imbalance across nodes.
A ‘round robin’ load balancing strategy is the recommendation for both client connection balancing and IP failover.
Dynamic failover
SmartConnect supports IP failover to provide continuous access to data when hardware or a network path fails. Dynamic failover is recommended for high availability workloads on SmartConnect subnets that handle traffic from NFS clients.
For optimal network performance, observe the following SmartConnect best practices:
- Do not mix interface types (40 Gb, 10 Gb, 1 Gb) in the same SmartConnect Pool
- Do not mix node types with different performance profiles (for example, H700 and A300 interfaces).
- Use the ‘round-robin’ SmartConnect Client Connection Balancing and IP-failover policies.
SmartConnect pool sizing
To evenly distribute connections and optimize performance, the recommendation is to size SmartConnect for the expected number of connections and for the anticipated overall throughput likely to be generated. The sizing factors for a pool include:
- The total number of active client connections expected to use the pool’s bandwidth at any time.
- Expected aggregate throughput that the pool needs to deliver.
- The minimum performance and throughput requirements in case an interface fails.
Because OneFS is a single volume, fully distributed file system, a client can access all the files and associated metadata that are stored on the cluster, regardless of the type of node a client connects to or the node pool on which the data resides. For example, data stored for performance reasons on a pool of all-flash nodes can be mounted and accessed by connecting to an archive node in the same cluster. The different types of platform nodes, however, deliver different levels of performance.
To avoid unnecessary network latency under most circumstances, the recommendation is to configure SmartConnect subnets such that client connections are to the same physical pool of nodes on which the data resides. In other words, if a workload’s data lives on a pool of F-series nodes for performance reasons, the clients that work with that data should mount the cluster through a pool that includes the same F-series nodes that host the data.