
General alert configuration considerations
General alert configuration considerations
-
The following sections list some general alert configuration considerations including the following:
- Alert granularity customization
- Alert severity configuration
- Alert configuration by the deny list
- Stop receiving alert notifications for heart beat events
- Cause Long vs. Cause Short
Alert granularity customization
As covered in the section Alert architecture, events are organized into event groups and event groups are categorized by the event group categories. Alerts can be configured in different granularities by event group categories or event groups through the web UI and the CLI command. The following examples demonstrate alert configuration using both of these granularities.
The following command creates an alert named demo_alerts, sets the alert condition to NEW and sets the event group categories to System disk events and Node status events subscribing to all new event groups in these categories. To view all the event group categories, see Table 2.
isi event channels create mychannel smtp --address my_email@xxx.com --smtp_host smtp.xxx.com
isi event alerts create demo_alerts --category "100000000,200000000" NEW mychannel
The following command creates an alert named demo_alerts, sets the alert condition to NEW and only subscribes to event groups 100010001 and 100010009.
isi event alerts create demo_alerts --eventgroup "100010001,100010009" NEW mychannel
To view all the event groups which can be subscribed through SMTP in the form of the combination of event group ID, event group name, event group description and the belonging event group category, use the following CLI command:
isi event types list –format list
Sample output:
--------------------------------------------------------------------------
ID: 900100017
Name: HW_NVRAM_SRAM_ECC_CORRECTABLE
Category: 900000000
Description: NVRAM SRAM correctable (single-bit) ECC error in chassis {chassis} slot {slot}
--------------------------------------------------------------------------
Note: The command isi event types list is only available in OneFS 8.0.0.5 and later versions.
Alert severity configuration
It is highly recommended to tune the alert severity based on each specific environment to minimize unnecessary email alerts. The only way to configure alert severity is to use the OneFS CLI.
The following command creates an alert named ExternalNetwork, sets the alert condition to NEW, sets the source event group to the event group with the ID number 400160001, sets the channel that will broadcast the event to RemoteSupport and sets the severity level to critical:
isi event alerts create ExternalNetwork NEW --eventgroup 400160001 --channel RemoteSupport --severity critical
The following example modifies the alert named ExternalNetwork to ExtNetwork, adding the event group with an event group ID number of 400160001, and filtering so that alerts will only be sent for event groups with a severity value of critical:
isi event alerts modify ExternalNetwork --name ExtNetwork --add-eventgroup 400160001 --severity critical
Alert configuration by the deny list
It is a quite common scenario to configure alerts by deny list which means to alert on all the types of event groups except type X, Y, and Z. The following examples will demonstrate how to achieve this function by a custom script. This example will subscribe to all event group types except 400160001 in the SMTP alerts configuration. The implementation is different between OneFS versions before 8.0.0.5 and later:
- In OneFS version 8.0.0.0 – 8.0.0.4, create a file called eventgroups.py containing the following code. This is to generate a collection of all the event group types.
#!/usr/bin/python
import json
efile="/etc/celog/events.json"
egfile="/etc/celog/eventgroups.json"
with open(efile, "r") as ef:
e = json.loads(ef.read())
with open(egfile, "r") as egf:
eg = json.loads(egf.read())
out = []
symptoms = []
for eg,v in eg.iteritems():
if eg != v["name"]:
print "warning.. name not same %s" % eg
out += [eg]
for s in v["symptoms"]:
symptoms += [s]
for e,v in e.iteritems():
if e not in symptoms:
out += [e]
print ",".join(out)
- Create an SMTP channel and associate it with a customized alert to exclude event group type 400160001.
isi event channels create mychannel smtp --address my_email@xxx.com --smtp_host smtp.xxx.com
isi event alert create myalert NEW mychannel --eventgroup `./eventgroups.py | sed 's/,400160001//'`
- To verify the configuration, send a test alert by leveraging the following script. The expected outcome is that the SMTP alert for event group type 40005002 is sent to the subscriber.
/usr/bin/isi_celog/celog_send_events.py -o 400160001
/usr/bin/isi_celog/celog_send_events.py -o 400050002
In 8.0.0.5 and later versions, the list of event group types is available by isi event type list. It will do the same job as the scripts in the above step 1 to generate a collection of all the event group types. Setting up an SMTP alert for all event group types except 40016001 is described below:
- Create an SMTP channel and associate it to a customized alert to exclude event group type 400160001.
isi event channels create mychannel smtp --address my_email@xxx.com --smtp_host smtp.xxx.com
isi event type list --format json | python -c 'import json;import sys;print ",".join([eg["id"] for eg in json.loads(sys.stdin.read())])' | sed 's/,400160001//' > a.txt
isi event alert create myalert NEW mychannel --eventgroup `cat a.txt`
- To verify the configuration, send the test alert by leveraging the following script. The expected outcome is that the SMTP alert for event group type 40005002 is sent to the subscriber.
/usr/bin/isi_celog/celog_send_events.py -o 400160001
/usr/bin/isi_celog/celog_send_events.py -o 400050002
Starting in OneFS 9.4.0.0, you can use PAPI to achieve the same purpose. Send event IDs that you want to exclude in an HTTP PUT request to /platform/15/event/alert-conditions/<alert rule name>
The following is an example data body:
{"exclude_eventgroup_ids": ["100010001", "100010002"]}
The following figure shows an example to exclude the event ID 100010001 and 100010002 from the alert – DemoAlertRule:
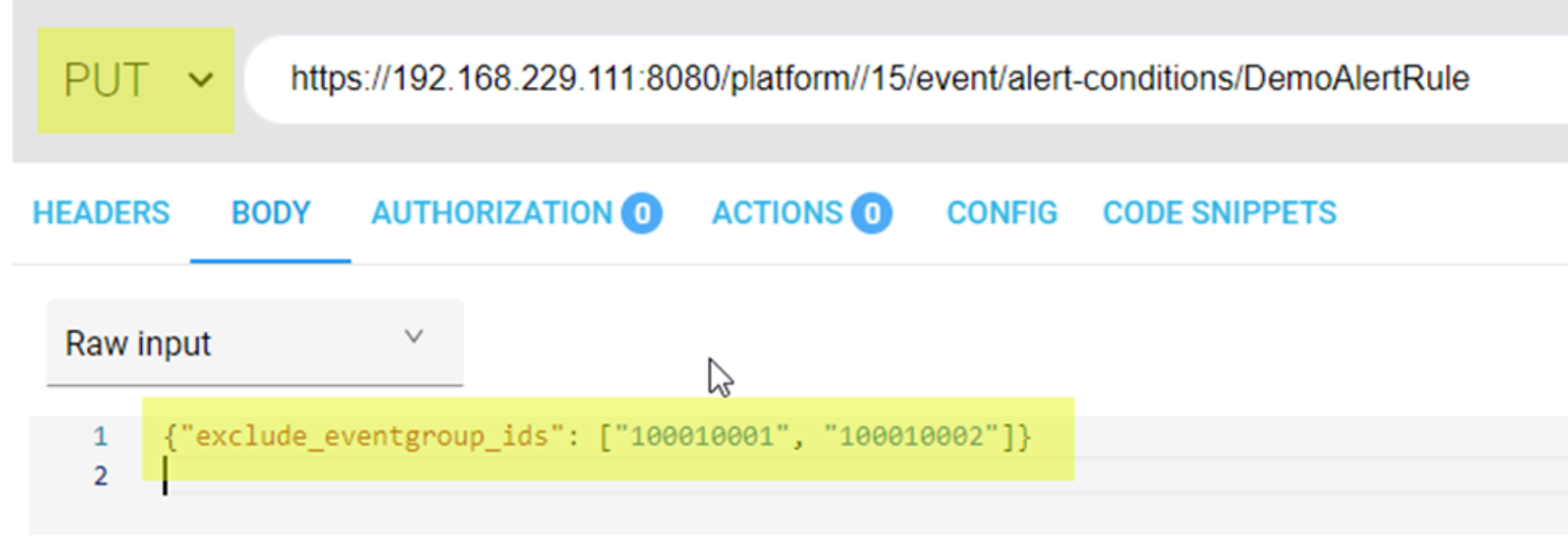
Figure 3. An example to exclude the events from an alert
Stop receiving alert notification for heartbeat events
In OneFS 8.0 and later versions, PowerScale cluster will generate a number of heartbeat events every day. Heartbeat alerts are intended to tell you when a node is unable to send alerts. Normally these events are only for informational purposes. The total number of heartbeat alert notifications is equal to the total number of nodes in the PowerScale cluster. For example, if you have configured SMTP alerts in a 60-node PowerScale cluster; you will get 60 email alert notifications for heart beat events every day. The event group ID for heart beat events is 400050004. So you can either add event group ID 400050004 to the deny list or you can set a non-informational severity for this event as discussed in the section Alert severity configuration. The following examples will demonstrate both ways.
Use the following CLI commands to exclude the heart beat event group (400050004) in the SMTP alert configuration. (OneFS 8.0.0.5 and later)
isi event channels create mychannel smtp --address my_email@xxx.com --smtp_host smtp.xxx.com
isi event type list --format json | python -c 'import json;import sys;print ",".join([eg["id"] for eg in json.loads(sys.stdin.read())])' | sed 's/,400050004//' > a.txt
isi event alert create myalert NEW mychannel --eventgroup `cat a.txt`
Use the following CLI command to set the severity level for heart beat event group (400050004) to emergency, critical, and warning.
isi event alerts create demo_alerts --eventgroup "400050004" --severity "emergency,critical,warning" NEW mychannel
Causes long or causes short
Starting from OneFS 8.0, the related events are organized into event groups. In this case, the CLI command isi event is an abbreviation for isi event group. To view a list of groups of correlated event occurrences, we can use either isi event list or isi event groups list to achieve this. This command will list a short description (causes short) for each event group as shown in Figure 4.

Figure 4. Causes short
If more details are preferred, we recommend you use the CLI command isi event list -v or isi event group list -v to view the long description (Causes Long). Here is another example:
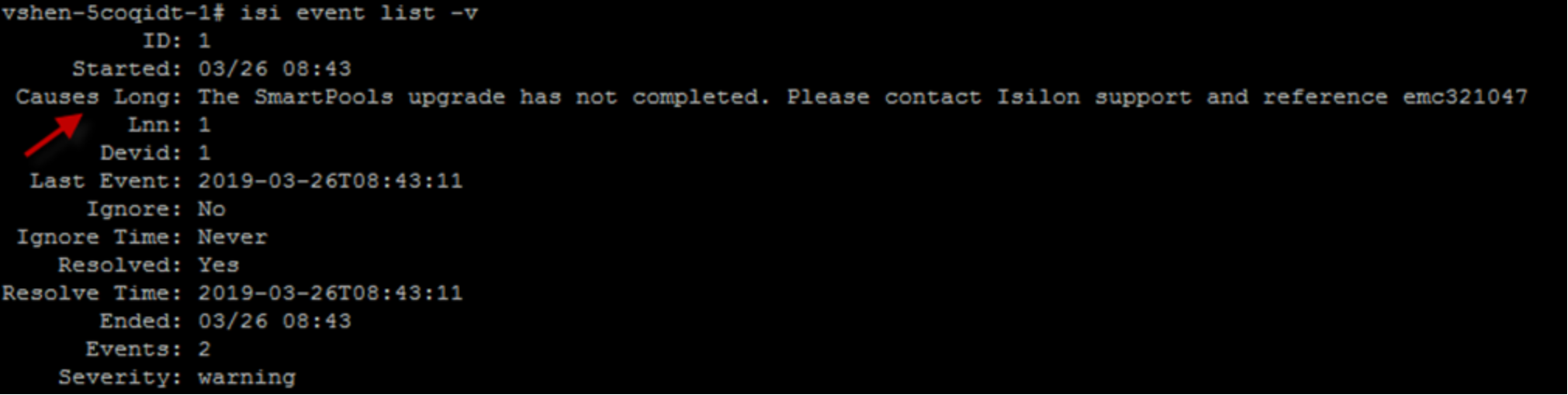
Figure 5. Causes long
Configurable event threshold
This feature is introduced in OneFS 9.1.0.0 and allows users to customize event thresholds to a level listed below other than the defaults.
- Info
- Warn
- Crit.
- Emerg.
In OneFS 9.1.0.0, seven events are configurable with their thresholds. For the configurable events and their default threshold values, see Table 3:
Table 3. Configurable event thresholds and their default values
ID
Name
Description
Info
Warn
Crit.
Emerg.
100010001
SYS_DISK_VARFULL
Percentage at which /var partition is near capacity
75%
85%
90%
NA
100010002
SYS_DISK_VARCRASHFULL
Percentage at which /var/crash partition is near capacity
NA
90%
NA
NA
100010003
SYS_DISK_ROOTFULL
Percentage at which /(root) partition is near capacity
NA
90%
95%
NA
100010015
SYS_DISK_POOLFULL
Percentage at which a nodepool is near capacity
75%
80%
90%
97%
100010018
SYS_DISK_SSDFULL
Percentage at which an SSD drive is near capacity
75%
85%
90%
NA
600010005
SNAP_RESERVE_FULL
Percentage at which snapshot reserve space is near capacity
NA
90%
99%
NA
800010006
FILESYS_FDUSAGE
Percentage at which the system is near capacity for open file descriptors
85%
90%
95%
NA
To configure the event thresholds, use WebUI or CLI as the following:
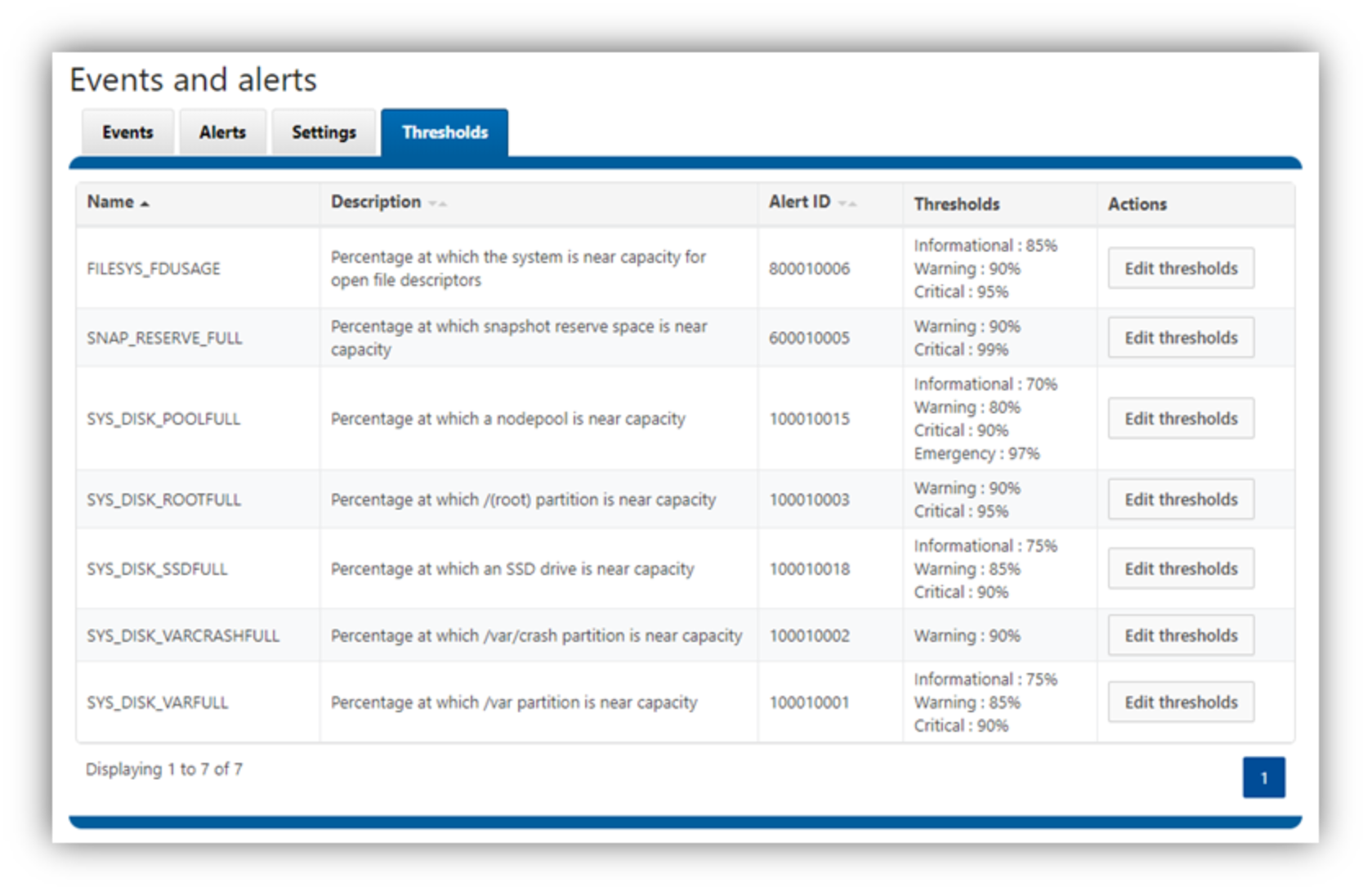
Figure 6. WebUI to configure the event thresholds
The following are examples of how to use CLI to list, view, modify, and reset the event thresholds:
vshen-llh7eh7-1# isi event thresholds view 100010001
ID: 100010001
ID Name: SYS_DISK_VARFULL
Description: Percentage at which /var partition is near capacity
Defaults: info (75%), warn (85%), crit (90%)
Thresholds: info (75%), warn (85%), crit (90%)
vshen-llh7eh7-1# isi event thresholds modify 100010001 --info 50 --crit 95
vshen-llh7eh7-1# isi event thresholds view 100010001
ID: 100010001
ID Name: SYS_DISK_VARFULL
Description: Percentage at which /var partition is near capacity
Defaults: info (75%), warn (85%), crit (90%)
Thresholds: info (50%), warn (85%), crit (95%)
vshen-llh7eh7-1# isi event thresholds reset 100010001
Are you sure you want to reset info, warn, crit from event 100010001?? (yes/[no]): yes
vshen-llh7eh7-1# isi event thresholds view 100010001
ID: 100010001
ID Name: SYS_DISK_VARFULL
Description: Percentage at which /var partition is near capacity
Defaults: info (75%), warn (85%), crit (90%)
Thresholds: info (75%), warn (85%), crit (90%)
New WebUI for CELOG
In OneFS 9.2.0.0, the user interface (UI) for CELOG has been re-designed to make sure everything is in good order and easy to use. You can easily:
- Show events for
- Today
- This week
- This month
- Custom range/
- All
- Categorize all the events by their status like
- Active
- Ignored
- Resolved
- All
- Filter the event by the severity like
- Emergency
- Critical
- Warning
- Information
- Search for a specific event in the event history
- Resolve a bulk of events
- Ignore a bulk of events
Figure 7 shows a screenshot of the new WebUI for Event group history. You can get to this new UI by clicking Event and alerts under Cluster management in OneFS WebUI. Please click around and let us know if you have any comments or suggestions about it.
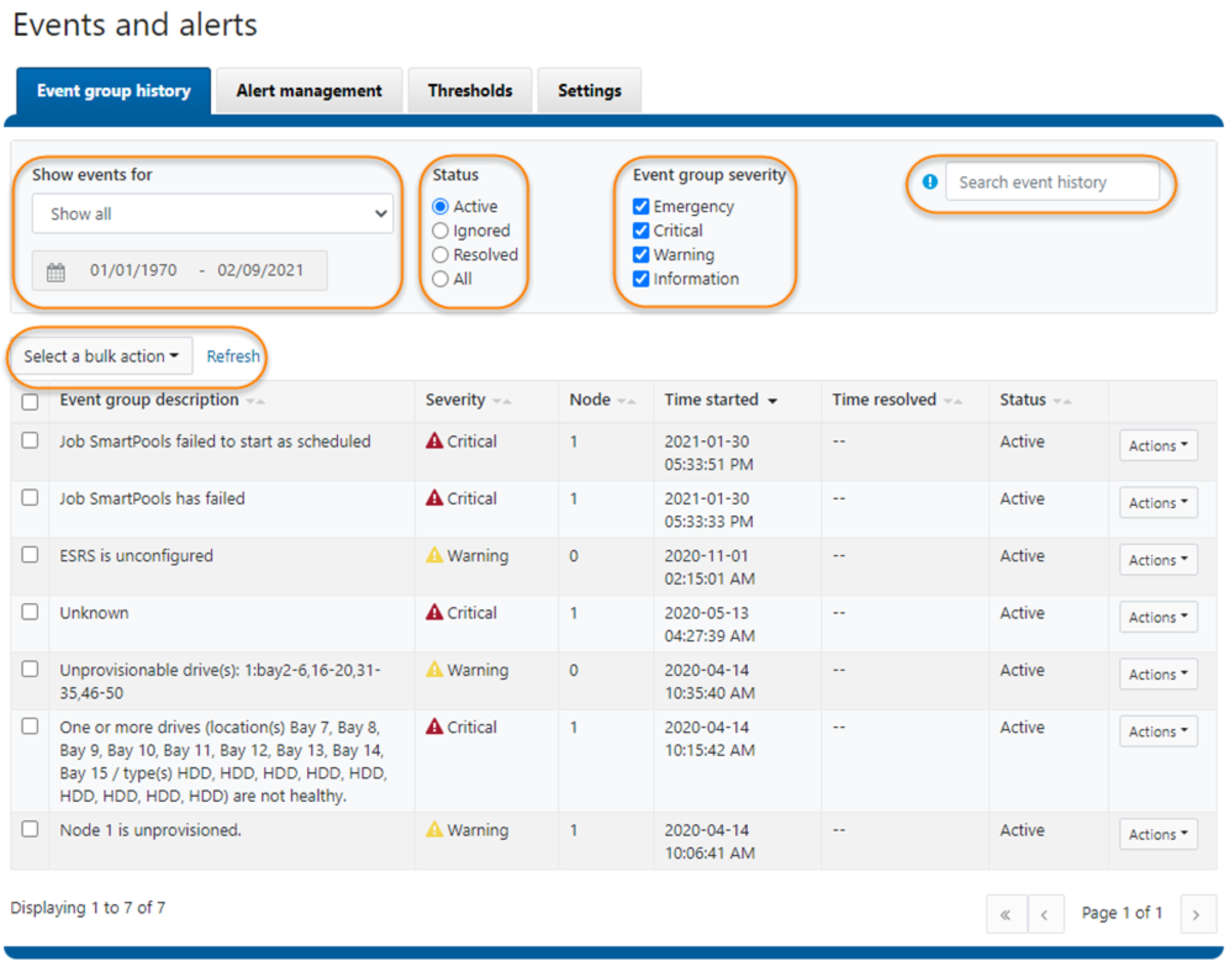
Figure 7. New WebUI for Event group history
CELOG maintenance mode
In OneFS 9.2.0.0, you can manually enable and disable CELOG maintenance mode. During a CELOG maintenance window, the system will continue to log events, but no alerts will be generated. You will have the opportunity to review all events that took place during the maintenance window when disabling maintenance mode. Active event groups will automatically resume generating alerts when the scheduled maintenance period ends.
The following steps will lead you to go through this feature:
- To enable CELOG maintenance mode, in OneFS WebUI, click Event and alerts under Cluster management. Click the Alert management tab, and click Enable CELOG maintenance mode. In the prompt window, click Enable CELOG maintenance mode shown in Figure 8:
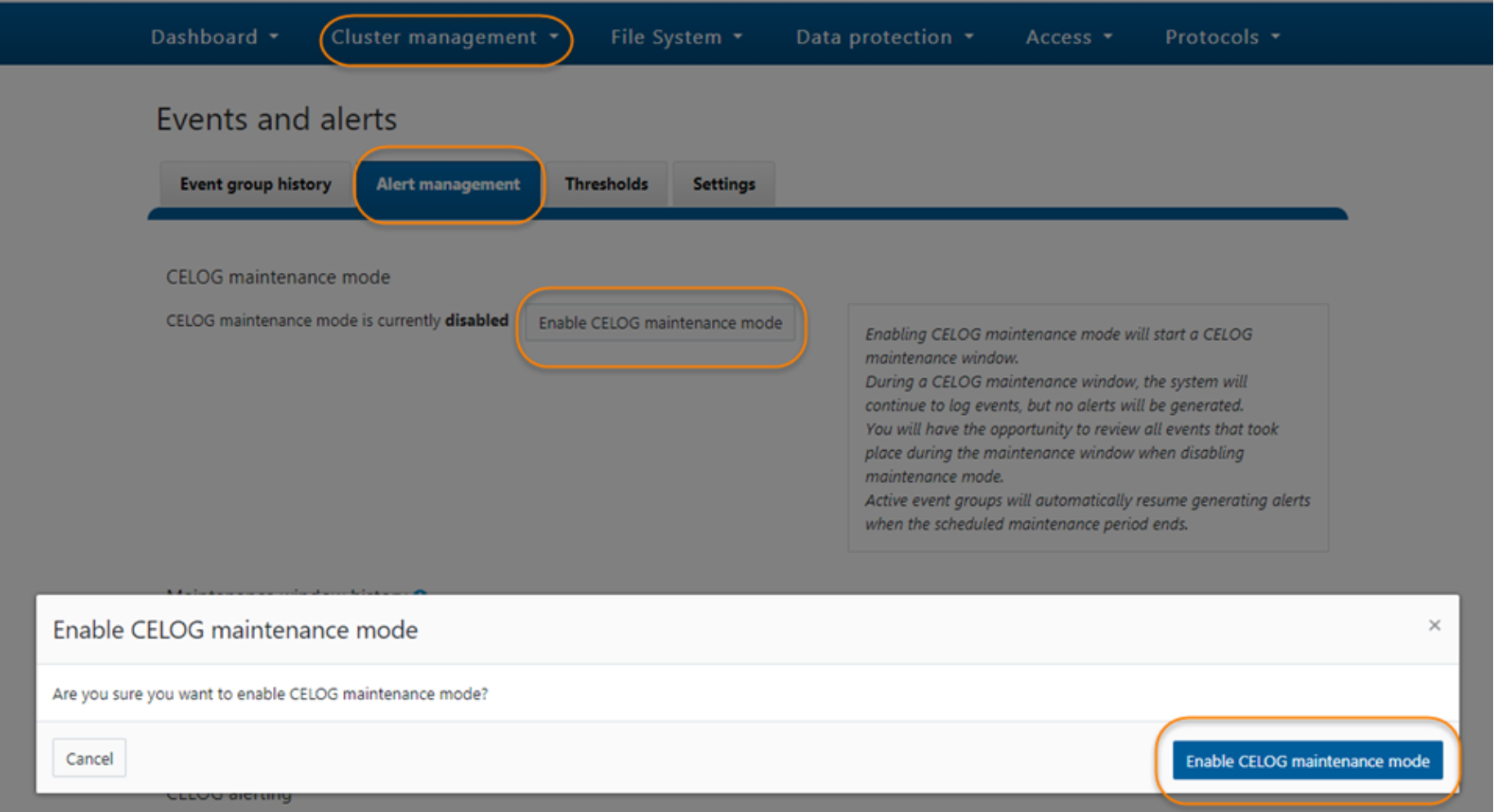
Figure 8. Enable CELOG maintenance mode
- Create an Alert channel for testing. This operation depends on your specific environment, for example, you can either choose SMTP or SNMP channel as what you have pre-configured in your environment. In this example, I create an SMTP channel in the lab. To create a channel, click Create channel under Alert channel in the CELOG alerting section as shown in Figure 9.
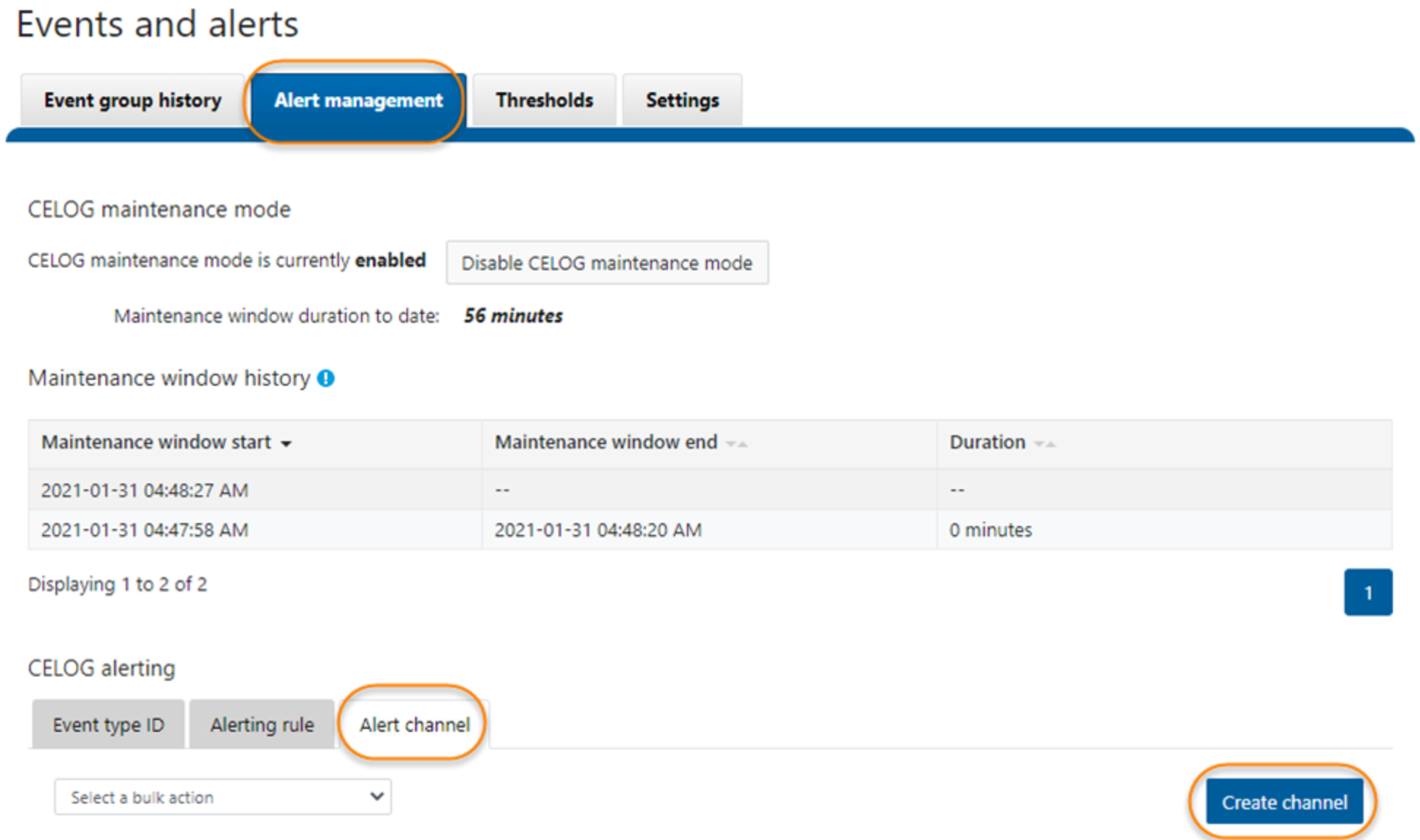
Figure 9. Create channel
- To create an alert rule, click the tab Alerting rule and then click the button Create alert rule
- In the prompt window, fill the Rule name, set the Rule condition to NEW, apply it to all the Alert categories, and attached it to the channel you have just created.
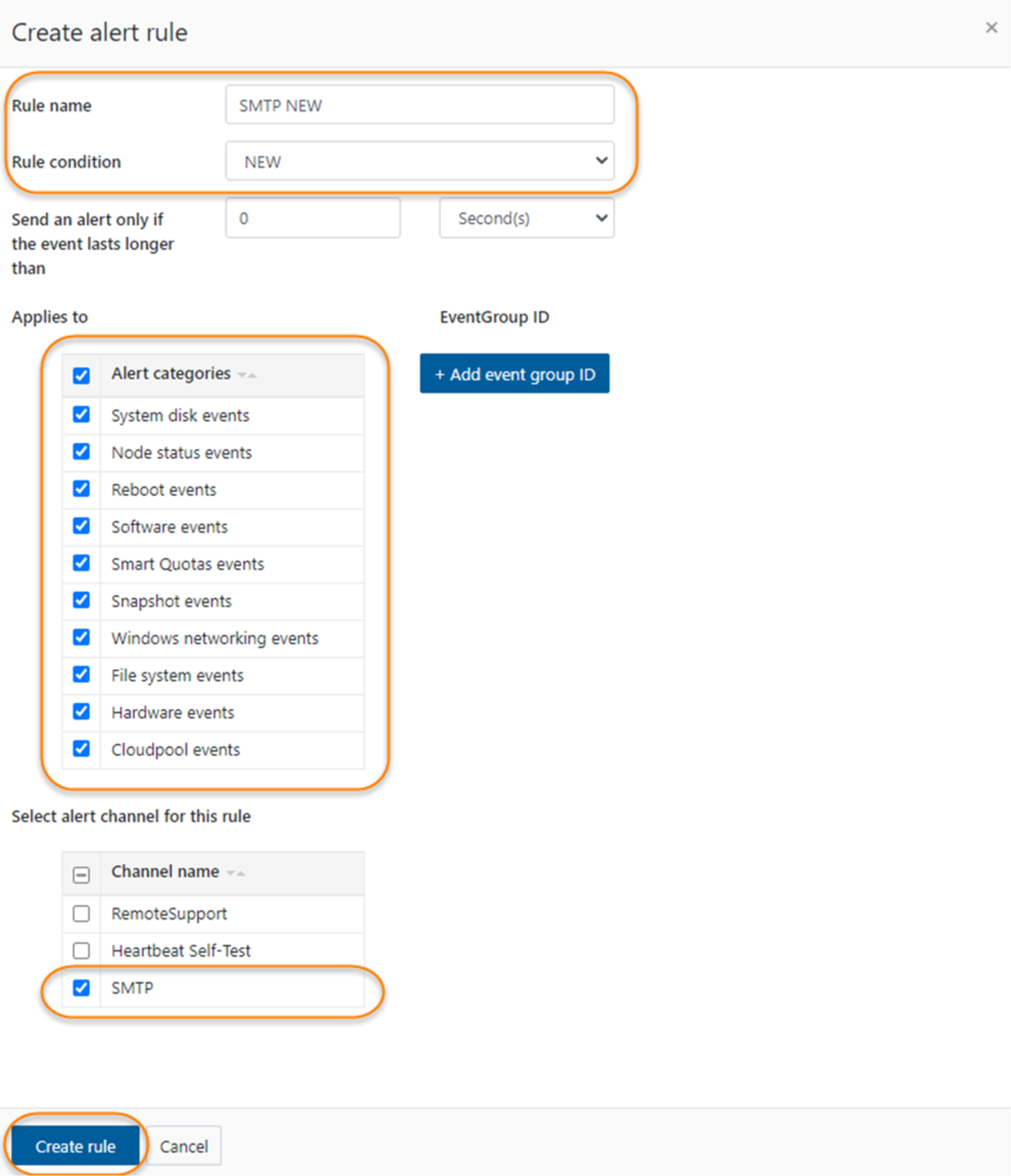
Figure 10. Rule configuration
- Open an SSH connection to any node in the cluster and log in using the root account. Use the following command to create several events:
# /usr/bin/isi_celog/celog_send_events.py -o 940100002
The output is like below:
Heap looptimes: [-1]
running -1 [940100002]
1612871342 :: Sending eventids [940100002] with specifier None
940100002 message is OneFS {version} is currently running on unsupported nodes (devid(s) {devids}). {msg}.
1.195 (70368744177859) corresponds to eventid 940100002
Out of events to run. Exiting.
# /usr/bin/isi_celog/celog_send_events.py -o 940100001
The output is like below:
Heap looptimes: [-1]
running -1 [940100001]
1612872343 :: Sending eventids [940100001] with specifier None
940100001 message is OneFS {version} is currently running and is not supported on this hardware: {msg}.
1.196 (70368744177860) corresponds to eventid 940100001
Out of events to run. Exiting.
- During maintenance mode, OneFS will still show the event but there will be no alert. In this example, there is no SMTP alert email triggered. In the Event group history, this event is shown in Figure 11.
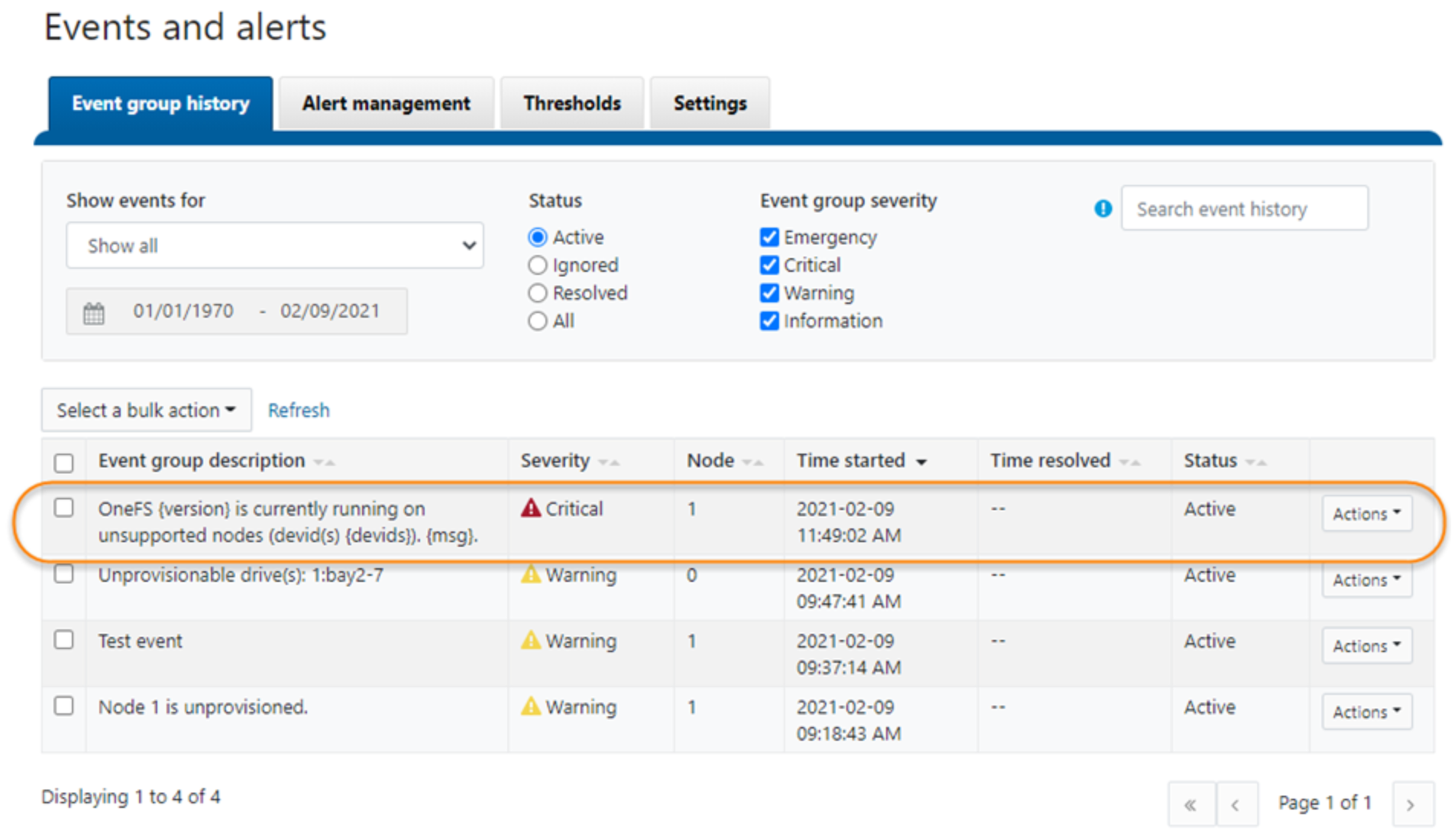
Figure 11. Event in history
You can also use the following command to filter all the events which happened during the CELOG maintenance mode:
# isi event groups list --maintenance-mode=true
The output is like the following:
ID Started Ended Causes Short Lnn Events Severity
------------------------------------------------------------------------------------------
16 02/09 11:49 -- HW_CLUSTER_ONEFS_VERSION_NOT_SUPPORTED 1 1 critical
17 02/09 12:05 02/09 12:19 HW_ONEFS_VERSION_NOT_SUPPORTED 1 1 critical
------------------------------------------------------------------------------------------
- Click the button Disable CELOG maintenance mode. In the following prompt window, it will list all the events during the CELOG maintenance mode and you can:
- View event details
- Ignore event
- Resolve event
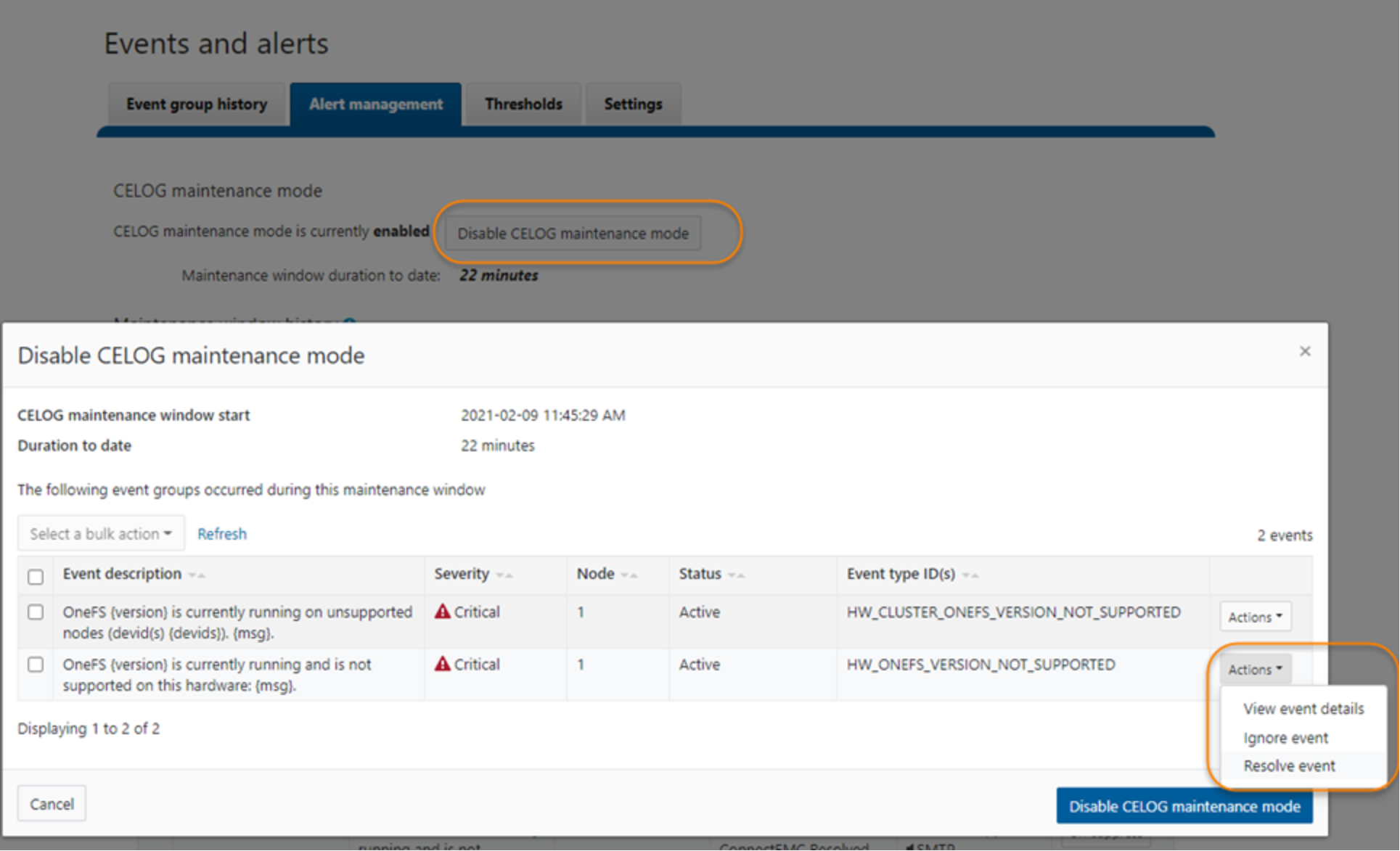
Figure 12. Disable CELOG maintenance mode
In this example, the event HW_ONEFS_VERSION_NOT_SUPPORTED is marked resolved by clicking Action and Resolve event.
After the CELOG maintenance mode is disabled, you will get the email notification only for HW_CLUSTER_ONEFS_VERSION_NOT_SUPPORTED. The event which has been marked resolved will not trigger any notification.
Suppress Event Notification
When an event type is suppressed, it prevents an event from alerting on all configured CELOG channels. But the event will still show in the event group history.
The following steps will lead you to go through this feature:
- To suppress an event type, click the button Suppress for a specific event under the Event type ID tab as shown in Figure 13. In this example, both 930100006 and 930100005 have been suppressed.
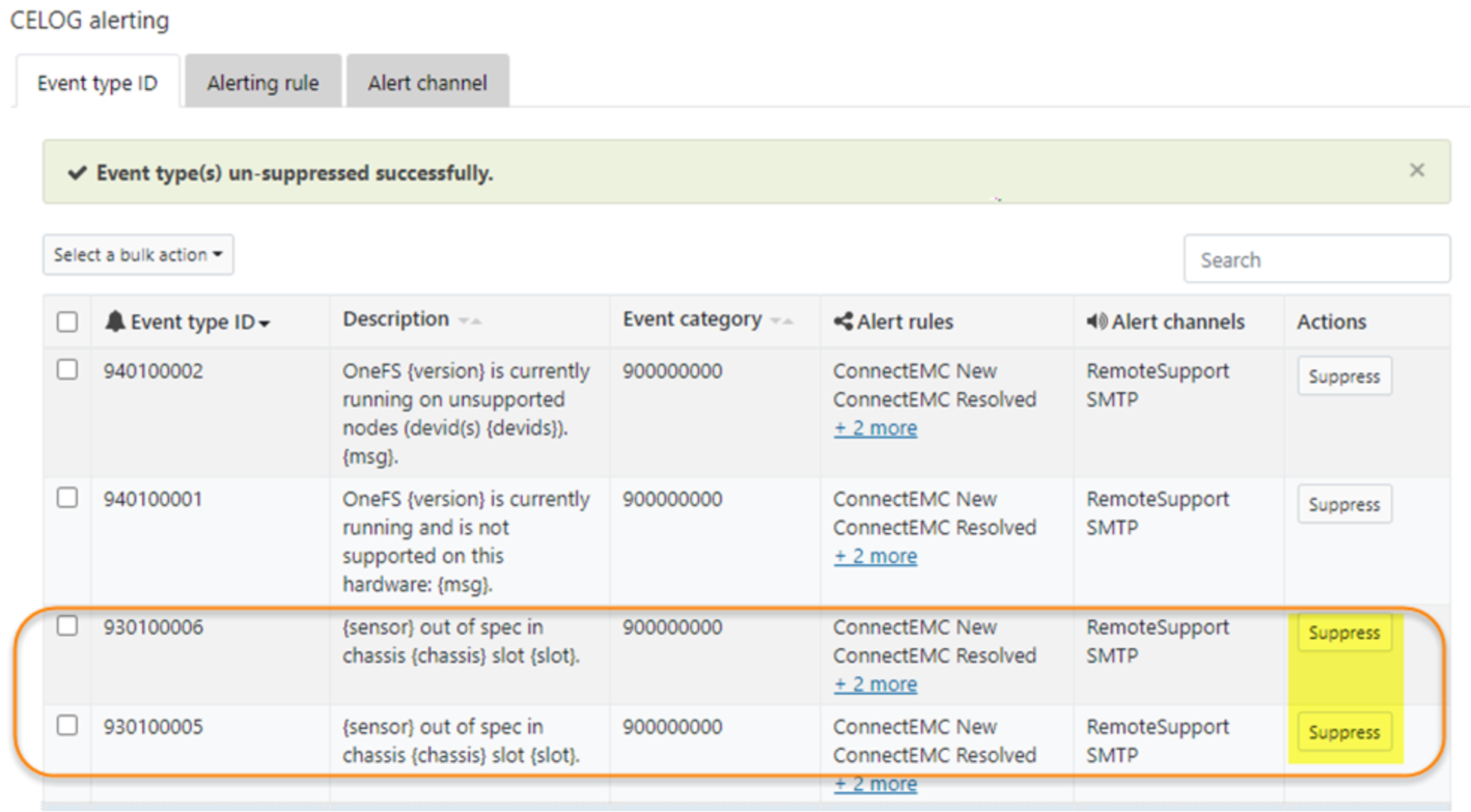
Figure 13. Suppress events
- Open an SSH connection to any node in the cluster and log in using the root account. Use the following command to create several events:
# /usr/bin/isi_celog/celog_send_events.py -o 930100006
The output is:
Heap looptimes: [-1]
running -1 [930100006]
1612873812 :: Sending eventids [930100006] with specifier None
930100006 message is {sensor} out of spec in chassis {chassis} slot {slot}.
1.200 (70368744177864) corresponds to eventid 930100006
Out of events to run. Exiting.
# /usr/bin/isi_celog/celog_send_events.py -o 930100005
The output is:
Heap looptimes: [-1]
running -1 [930100005]
1612873817 :: Sending eventids [930100005] with specifier None
930100005 message is {sensor} out of spec in chassis {chassis} slot {slot}.
1.201 (70368744177865) corresponds to eventid 930100005
Out of events to run. Exiting.
- To list all the events in the suppressed list, use the following command:
# isi event suppress list
The output is:
ID Name
----------------------------
930100005 HWMON_ANY_DISCRETE
930100006 HWMON_ANY_METERS
----------------------------
- These suppressed events will only show in the event history and will not trigger any notification in any channels.
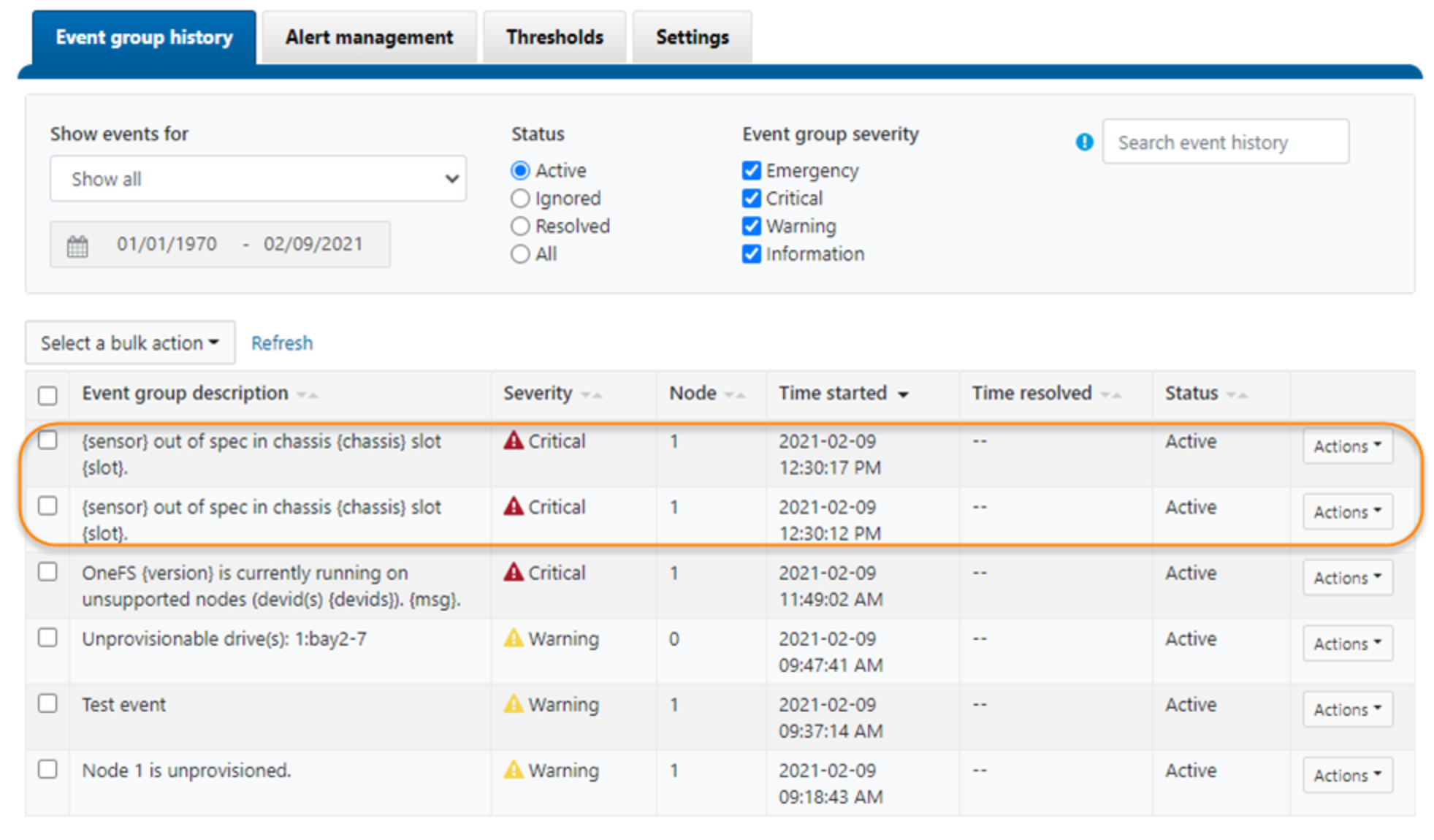
Figure 14. Suppressed events
- Un-suppress the event types by clicking the Un-supress button.
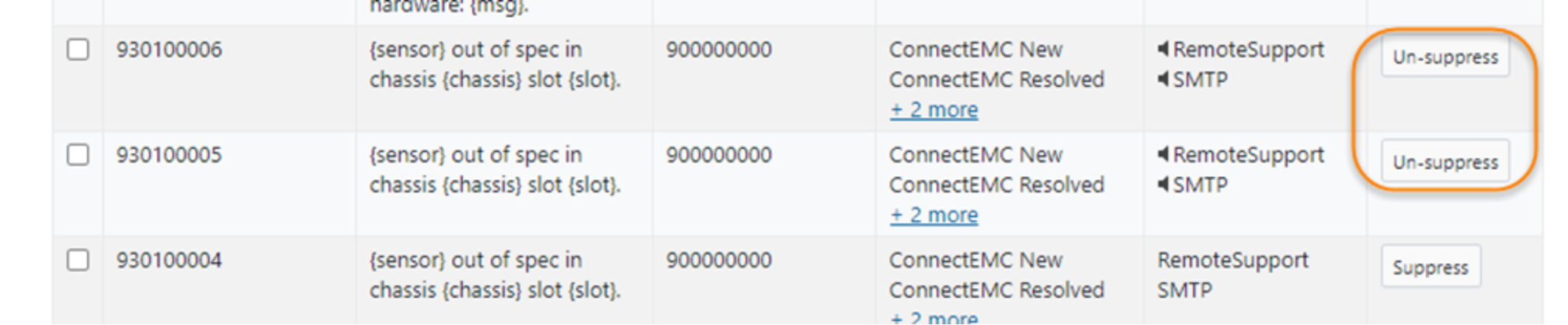
Figure 15. Un-suppress events