Test results and performance analysis
Test results and performance analysis
-
Training throughput
The following figure shows the Single Shot MultiBox Detector model training benchmark throughput results. It is obvious from the results that image throughput scales linearly from 8 to 32 A100 GPUs.
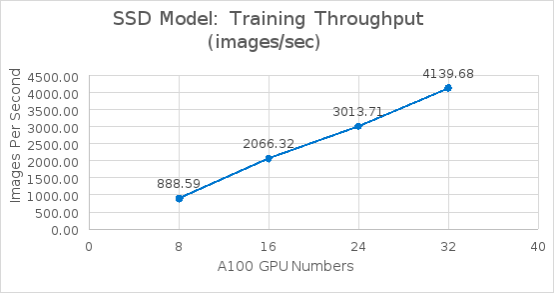
Figure 14. SSD model training benchmark from 8 GPUs to 32 GPUs
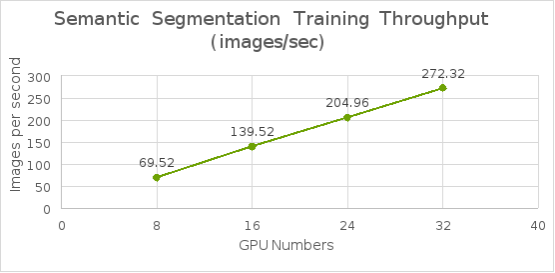
Figure 15. Semantic segmentation training benchmark from 8 GPUs to 32 GPUs
Training time and system metrics: SSD model
The following table shows the test results for the SSD model training time and bandwidth for each epoch. As shown in Figure 16, the average storage throughput grew almost linearly from 8 to 32 GPUs and reduced training time as well.
Table 6. SSD training time and storage bandwidth for each epoch with 2.8 TB dataset
GPUs
Average training time for each epoch
Average storage bandwidth per epoch
Peak storage bandwidth per epoch
8
18 minutes 15 seconds
2,080 MB/s
2,267 MB/s
16
7 minutes 51 seconds
2,350 MB/s
4,177 MB/s
24
5 minutes 23 seconds
2,860 MB/s
4,680 MB/s
32
3 minutes 55 seconds
3,420 MB/s
5,363 MB/s
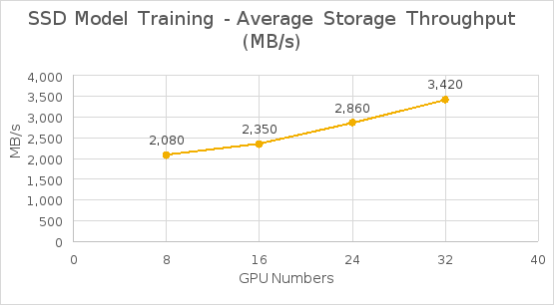
Figure 16. SSD model training average storage bandwidth from 8 GPUs to 32 GPUs
The following table lists the system metrics during the training. This indicates that the GPUs were fully utilized by leveraging the NVIDIA DALI library.
Table 7. SSD model training system metrics
System metrics
Percentage
Average GPU utilization
94%
Average GPU memory utilization
50%
Average compute node CPU utilization
35%
Average compute node memory utilization
99%
As shown in the following figure, during the training time, the peak storage throughput reached to 42.9Gb/s (5.36GB/s) with three DGX systems with 24 GPUs. We observed that the training is a heavily read intensive workload as it needed to read entire dataset from storage for training.
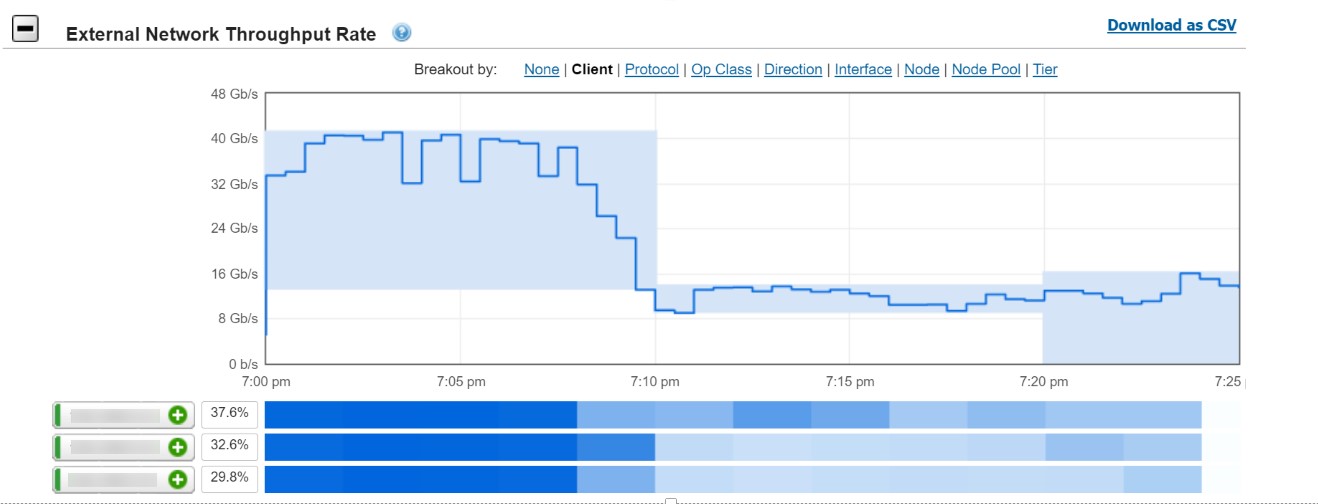
Figure 17. SSD model training storage throughput with three DGX A100 systems
We also observed that the storage throughput dropped after one epoch training. This was because the total dataset is only 2.8 TB. While running more than one epoch with three DGX systems (total 3 TB RAM), the system cache exceeded the total dataset. During the training, some of the data became cached on the system side, which reduced the storage throughput required during the training.
For storage configuration considerations, it is crucial to plan sizing for peak throughput on Isilon F800 storage during the training in order to minimize training times as required for business development needs.
During the training time, GPUs are fully utilized at 94%, as shown in the following figure.
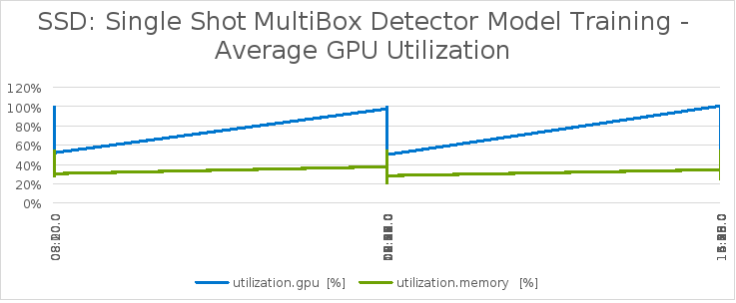
Figure 18. SSD model training with average 32 A100 GPU utilization
Training time and system metrics: Semantic segmentation model
The following table shows the test results for the semantic segmentation model training time and bandwidth. As shown in Figure 19, the average throughput scaled linearly from 8 to 32 GPUs and reduced training time as well.
Table 8. Semantic segmentation training time and storage bandwidth for each epoch with 5 TB dataset
GPUs
Training Time for each epoch
Average storage bandwidth for each epoch
Peak storage bandwidth for each epoch
8
8 hours 5 minutes
145.64 MB/s
138.43 MB/s
16
4 hours 2 minutes
303.75 MB/s
385.69 MB/s
24
2 hours 44 minutes
451.25 MB/s
570.32 MB/s
32
2 hours 4 minutes
550.34 MB/s
698.85 MB/s
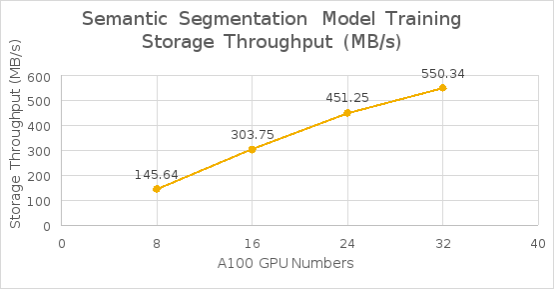
Figure 19. Semantic segmentation model training throughput from 8 GPUs to 32 GPUs
The following table lists the system metrics during the training. This indicates that the GPUs were fully utilized by leverage NVIDIA DALI library.
Table 9. DeepLabv3+ model training system metrics
System metrics
Percentage
Average GPU utilization
96%
Average GPU memory utilization
36.7%
Average compute node CPU utilization
9.86%
Average compute node memory utilization
98%
As shown in the next figure, during the training time, the average storage throughput reached to 4.4Gb/s (0.55 GB/s) and was read intensive. The storage throughput is consistent during the training because the total dataset exceeded the total compute server cache.
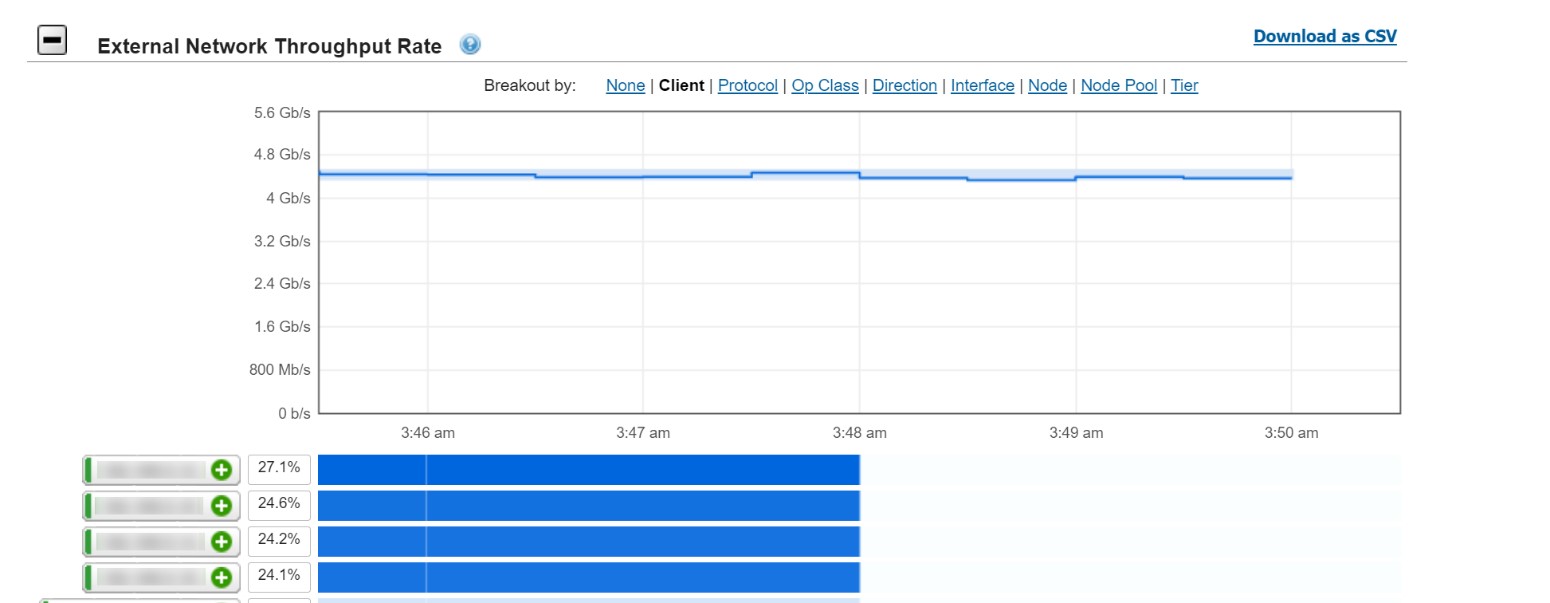
Figure 20. Semantic segmentation model training with 32 GPU storage throughput
Test results comparison
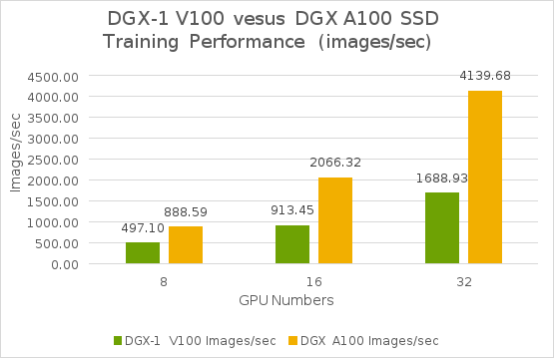
From our test results shown in the following figure, DGX A100 systems delivered over twice the training performance of an eight V100 GPU system, such as the NVIDIA DGX-1 system. The combination of the groundbreaking A100 GPUs with massive computing power and high-bandwidth access to large DRAM, and fast interconnect technologies, makes the DGX A100 system optimal for dramatically accelerating complex networks.
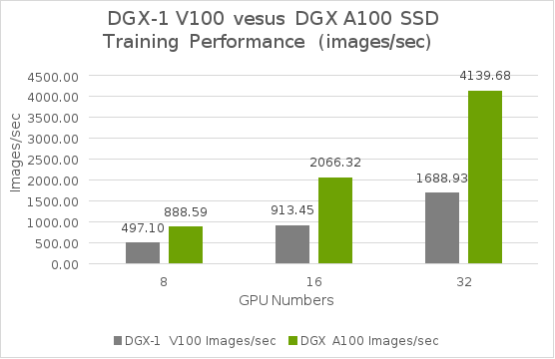
Figure 21. SSD model training performance comparisons
The DGX A100 system required higher storage throughput over V100 GPU system, as shown in the next figure. In our test results, we observed the average storage throughput dropped after testing with four DGX A100 systems. This was because the total dataset is only 2.8 TB. While running more with three DGX systems (total 3 TB RAM), the system cache exceeded the total dataset.