
Data transform
Data transform
-
Training neural networks with images requires developers to first normalize those images. Moreover, images are often compressed to save storage. Developers have therefore built multi-stage data processing pipelines that include loading, decoding, cropping, resizing and many other augmentation operators. Here are some key design considerations for data ingestion and data management for an ADAS DL workflow:
- Consider Data augmentation strategy: Dataset augmentation applies transformations to training data. Transformations can be as simple as flipping an image, or as complicated as applying neural style transfer. By performing data augmentation, it is possible to increase training dataset size and diversity. This can help to prevent a neural network from learning irrelevant patterns (common with small datasets) that would degrade overall training accuracy. Here are two common methods for data augmentation:
- Offline augmentation is to create new augmented data which is stored on the filesystem. This can help effectively increase the training sample size many times over with variety of different augmentation technologies.
- Online augmentation is to apply augmentation to data in real time before the images are fed to the neural network. CPUs are used heavily in the background and in parallel for online augmentations during the training.
- Use NVIDIA Data Loading Library (DALI): The DALI is a portable, open source library for decoding and augmenting images, videos, and speech to accelerate DL applications. As shown in the following figure, DALI is a set of highly optimized building blocks plus an execution engine used to accelerate input data pre-processing for DL applications.
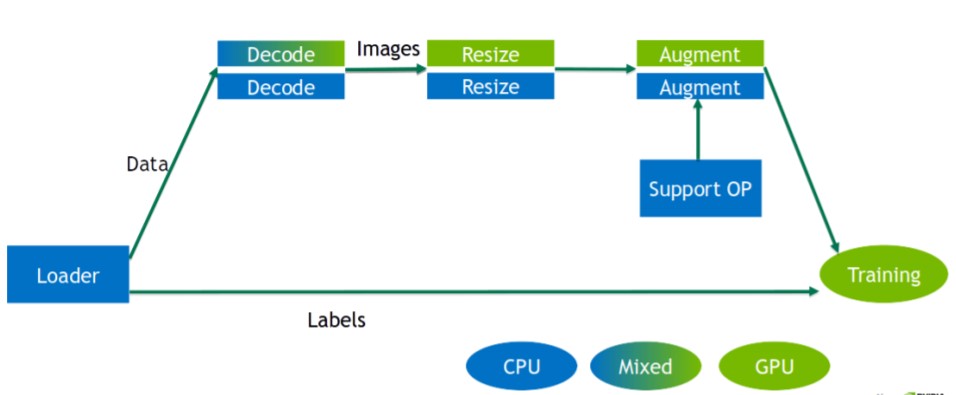
Figure 9. DALI inside architecture (©NVIDIA)
DALI provides performance and flexibility for accelerating different data pipelines. DALI reduces latency and training time, mitigating bottlenecks, by overlapping training and pre-processing. It provides a drop-in replacement for built in data loaders and data iterators in popular DL frameworks for easy integration and retargeting to different frameworks. Here are some key features:
- Easy-to-use Python API
- Transparent scaling across multiple GPUs
- Accelerated image classification (ResNet-50), object detection (SSD) workloads and speech recognition models such as Jasper and RNN-T
- Flexible graphs that let developers create custom pipelines
- Support of multiple data formats—LMDB, RecordIO, TFRecord, COCO, JPEG, wav, Free Lossless Audio Codec (FLAC), Ogg, H.264, and HEVC
- Ability for developers to add custom audio, image, and video processing
For more information, refer to NVIDIA blog.