
Data ingestion and data management
Data ingestion and data management
-
Here are some key design considerations for data ingestion and data management for ADAS DL workflow:
- Large scale sensor data and metadata management: Dealing with data access, data ingestion and metadata management with HPC jobs can become a significant distraction for the data scientist, wasting time and effort better spent on algorithm design and validation. To alleviate this, Dell Technologies has created a custom-tailored Data Management System (DMS), shown in the following figure, which is available as part of our PowerScale based ADAS solution offering.
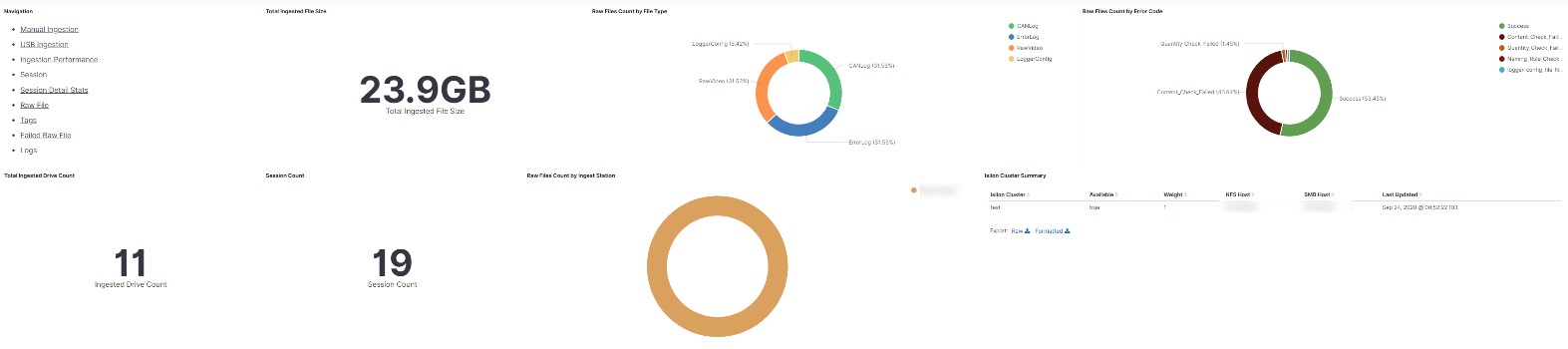
Figure 7. Dell EMC Data Management System dashboard
DMS is integrated into the managed service offering for ingesting data from test vehicles in an automated fashion. Specific metadata types and tags are configurable and can be customized for each customer. The service provider can manage logistics to receive the storage media from the vehicles and insert them into ingestion stations. This will automatically initiate processes that dynamically decide which cluster/location to upload the raw data to—in such a fashion that all ingestion processes are well balanced across the storage environment. DMS then initiates the data transfer automatically while enriching the data with appropriate metadata tagging, resulting in all data and tags being logged in a global index that tracks the data sets across the namespace and clusters. At the completion of the data transfer and indexing, DMS can launch post-processing jobs within the DL and HPC server grid as preconfigured through the scheduling platform. Functions available can include accurately splitting and merging data files as required, decoding the data into human readable form, automatically updating the index upon completion and other functions as defined by the customer. These processes are wrapped within a series of real-time monitoring, status dashboards, and logs to alert of any errors or anomalies.
- Hybrid Cloud Solution for ADAS Development: Auto organizations are investing heavily in new technologies to develop ADAS. One of the key hurdles these companies face is the fact that sensor data often span multiple platforms and geographic locations. This results in large, disconnected data silos that many companies find difficult to manage as these sensor files must be made available to a range of test environments and AI tools. In addition, sensor files are typically kept for multiple years or even decades after testing – the “life of the car” – and must be brought online quickly (often within weeks) should the need to update and validate algorithms ever occur. The new Dell EMC DataIQ product, as shown in the following figure, solves these challenges with its ability to break down storage silos and unify the unstructured data environment. It provides a single UI to view sensor data across heterogenous storage environments including the public cloud.

Figure 8. New hybrid cloud solution for ADAS development with Dell EMC DataIQ
DataIQ also equips organizations with the ability to rapidly search across billions of files and locate data, which can then be precisely moved or copied to on-prem or public cloud storage as needed, ensuring the right projects have access to pertinent data. This can help free up space on higher performance tiers and enables organizations to archive data as long as is required. The cost savings can be immense, and data can be retrieved easily from a well-curated, searchable archive for re-simulation and DL development in the future.