None
None
-
Before OneFS 8.2.0, CloudPools 1.0 supported archiving files with existing snapshots. However, CloudPools 1.0 had a limitation when archiving files that have existing snapshots: the copy-on-writes (CoW) process copied the entire contents of the file into the snapshot. Archiving files with existing snapshots therefore did not save space on the PowerScale cluster until the previously CoW-created snapshots expired. CloudPools 1.0 offered an option (clear the Archive files with snapshots checkbox in the WebUI) to skip such files with snapshots. A user might have not chosen to archive files with snapshots if the previously CoW-created snapshots had long retentions. This case is to avoid creating another copy on cloud storage where the retention period meant it would persist on PowerScale storage anyway.
CloudPools 2.0 eliminates CoW on the primary data source PowerScale cluster when archiving files with snapshots to the cloud. The file data is only stored in the cloud storage, which saves space on the PowerScale cluster. For more information about data CoW for snapshots, see the Data Protection with Dell PowerScale SnapshotIQ white paper.
However, CloudPools 2.0 does not archive files on the target cluster in a SyncIQ relationship. In an environment with long snapshot retentions and an expectation that the same snapshots are maintained in both clusters. It is possible for storage usage on a target cluster to grow larger than the storage on the primary cluster that has CloudPools enabled. For space efficiency, a user with requirements for long snapshot retentions on two clusters in a SyncIQ relationship might choose to use natively tiered PowerScale archive storage, rather than CloudPools.
SnapshotIQ can take read-only, point-in-time copies of any directory or subdirectory within OneFS. A file in one directory can be either a regular file or a SmartLink file before creating a snapshot. A regular file can be truncated to a SmartLink file after archiving its file data to the cloud. A SmartLink file can be converted to a regular file after recalling its file data to the PowerScale cluster. When a snapshot is taken, it preserves the exact state of a file system at that instant. A file in the snapshot directory (/ifs/.snapshot) is a SmartLink file if the same file in the source directory is a SmartLink file. A file in the snapshot directory is a regular file if the same file in the source directory is a regular file. The earlier version of data can be accessed later in the snapshot directory.
The following scenarios address CloudPools 2.0 and snapshots. HEAD is the current version of a SmartLink file in the source directory.
- The file is already a SmartLink file in the source directory before creating a snapshot.
- Scenario 1: Update HEAD
- Scenario 2: Update HEAD multiple times and a new snapshot is created between multiple updates
- Scenario 3: Read file data from a snapshot
- The file is still a regular file in the source directory before creating a snapshot. Then, the regular file is archived to the cloud after a snapshot creation.
- Scenario 4: Update HEAD
- Scenario 5: Read file data from a snapshot
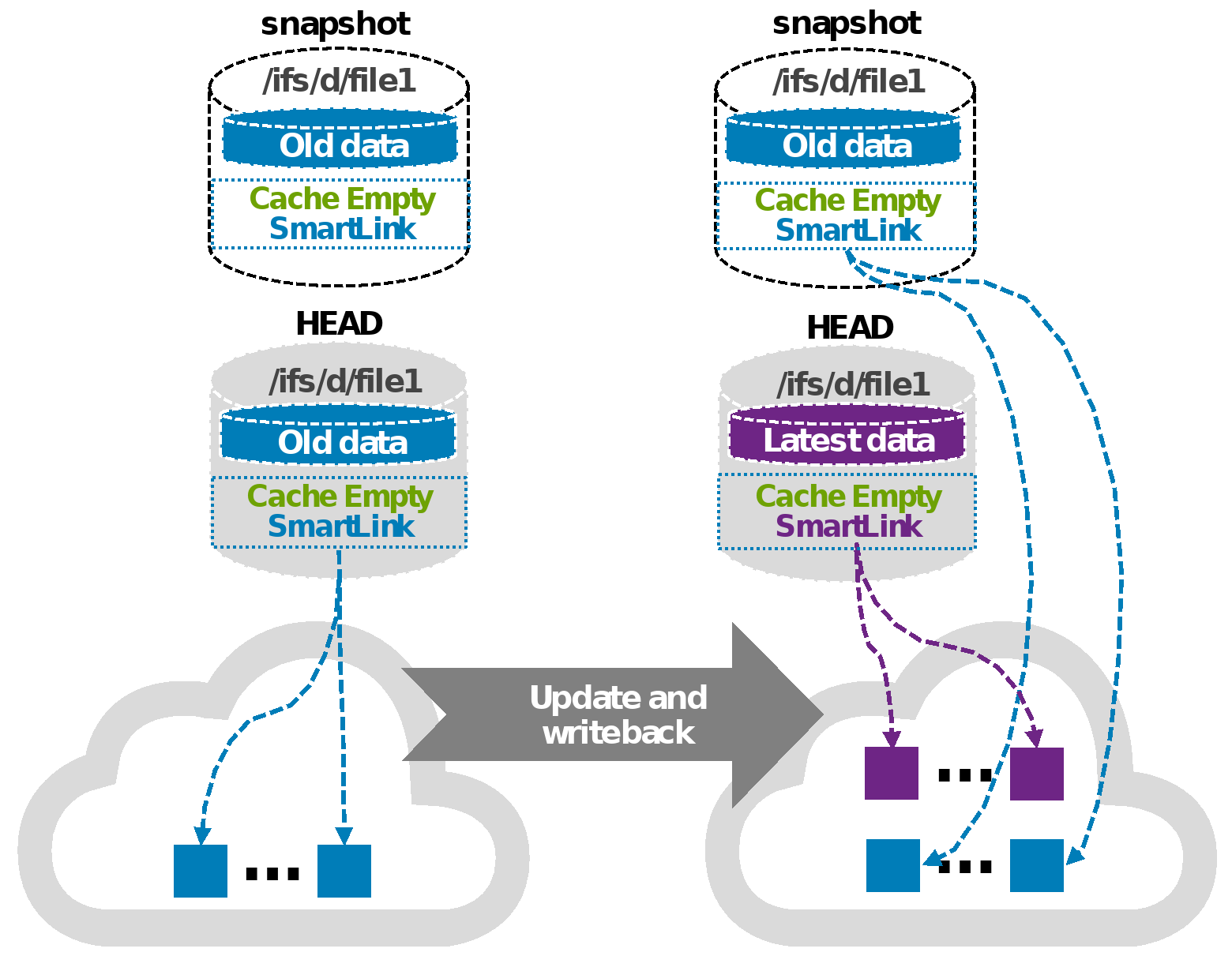
Scenario 1
When updating HEAD (SmartLink files in snapshot), a new SmartLink is generated for HEAD when updating HEAD and write-back to the cloud. Cache for HEAD will be empty once its own cache expires. For the workflow of updating a SmartLink file, see Update. The original version SmartLink file is still used for the next snapshot of HEAD. This scenario does not cause the snapshot space to grow. Figure 7 shows the process of scenario 1 to update HEAD when SmartLink files are in the snapshot directory.
Figure 7. Scenario 1: Update HEAD when SmartLink files are in the snapshot directory
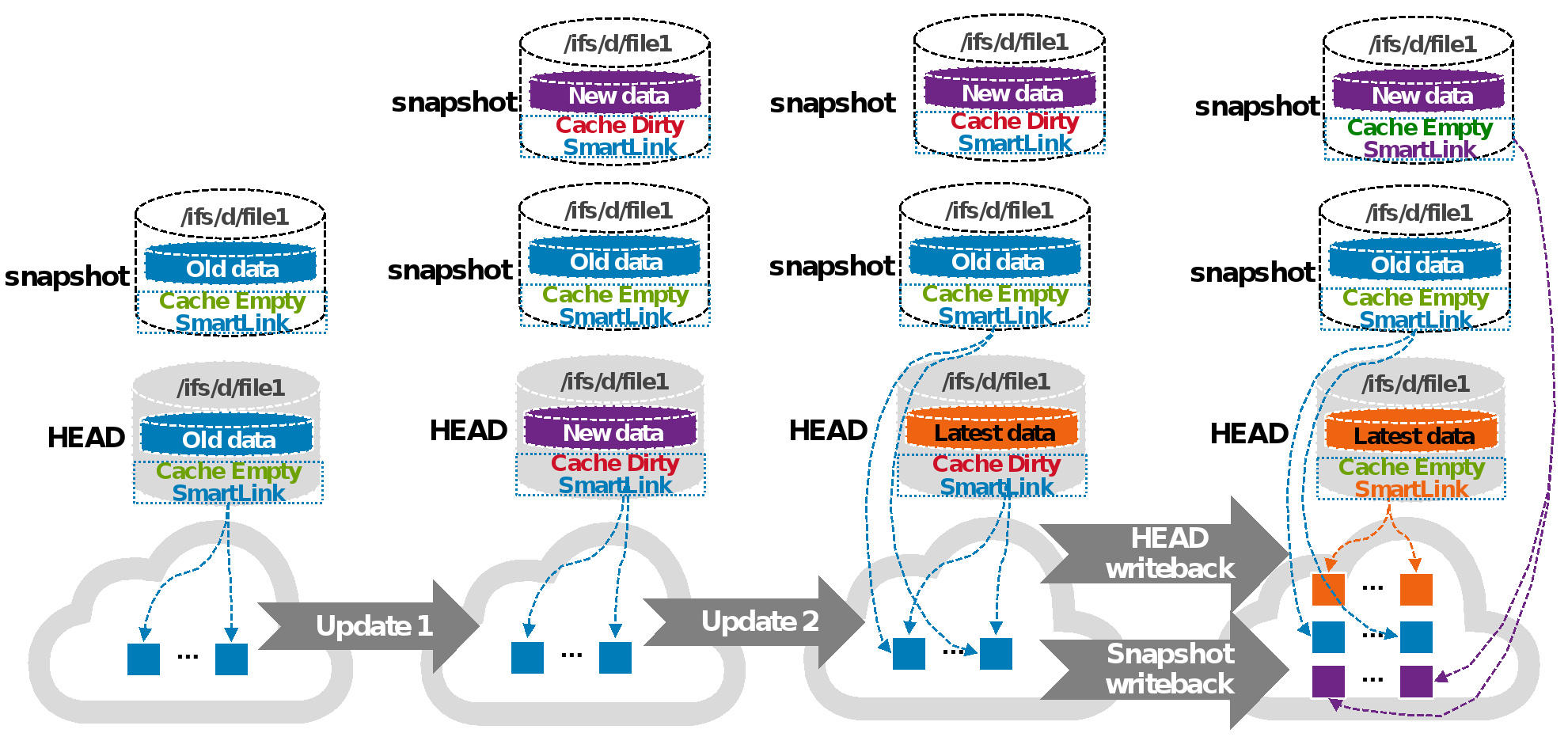
Scenario 2
This scenario describes updating HEAD multiple times, and a new snapshot is created between multiple updates (SmartLink files in snapshot). For example, a user updates HEAD (the first update) while a new (most recent) snapshot is created before the first update write-back is made to the cloud. Then, another user updates (the second update) HEAD again after the new (most recent) snapshot is created. Now there are two snapshots: one snapshot is the next snapshot of HEAD, the other is the most recent snapshot of HEAD.
When a snapshot is taken, it preserves the exact state of a file system at that instant. Data for the next snapshot of HEAD is the old data that is already archived to the cloud and its cache is empty. Data for the most recent snapshot is the new data and its cache is dirty before the new data write-back is made to the cloud. The new data contains old data with the first update. Data for HEAD is the latest data and its cache is dirty before the latest data write-back is made to the cloud. The latest data contains old data with the first update and the second update. A new version SmartLink is generated for the most recent snapshot after the new data write-back is made to the cloud (write-back in the snapshot). The new data contains old data with the first update. Also, a new version SmartLink is generated for HEAD after the latest data write-back is made to the cloud (write-back in HEAD). Cache for the most recent snapshot or HEAD becomes empty once its own cache expires. Now, all file data is only stored on the cloud and saves space on the PowerScale cluster. Users can read file data from its own SmartLink file at any time.
Figure 8 shows the process of scenario 2.
Figure 8. Scenario 2: Update HEAD multiple times and perform a write-back in the snapshot
Scenario 3
This scenario describes reading file data from a snapshot (SmartLink files in snapshot). The files in the next snapshot and HEAD use the same version of SmartLink file when not updating HEAD after the snapshot is created. This scenario is no different than reading the same file from HEAD or the next snapshot of HEAD. For the workflow of reading a SmartLink file, see Read. The same local data cache is used when reading the same file from HEAD and the next snapshot of HEAD simultaneously. This scenario does not cause the snapshot space to grow. The file in the snapshot directory uses its version of SmartLink file when updating HEAD and performing a write-back to the cloud like in scenario 1 or scenario 2. Users can read earlier versions of file data in the snapshot directory. The snapshot space could grow temporarily for cache data, and the grown space is released once its own cache expires.
Scenario 4
In this scenario, when updating HEAD (regular files in snapshot). A SmartLink file is used for HEAD, and a regular file is used for the same file in the next snapshot of HEAD. A new SmartLink file is generated for HEAD when updating HEAD and performing a write-back to the cloud. The cache for HEAD is empty once its own cache expires. Meanwhile, OneFS enables the Block Allocation Manager Cache Manager (BCM) on the regular file in the next snapshot of HEAD. BCM contains the metadata of mapping to cloud objects for the regular file in the next snapshot of HEAD. This scenario does not cause the snapshot space to grow.
Figure 9 shows scenario 4.
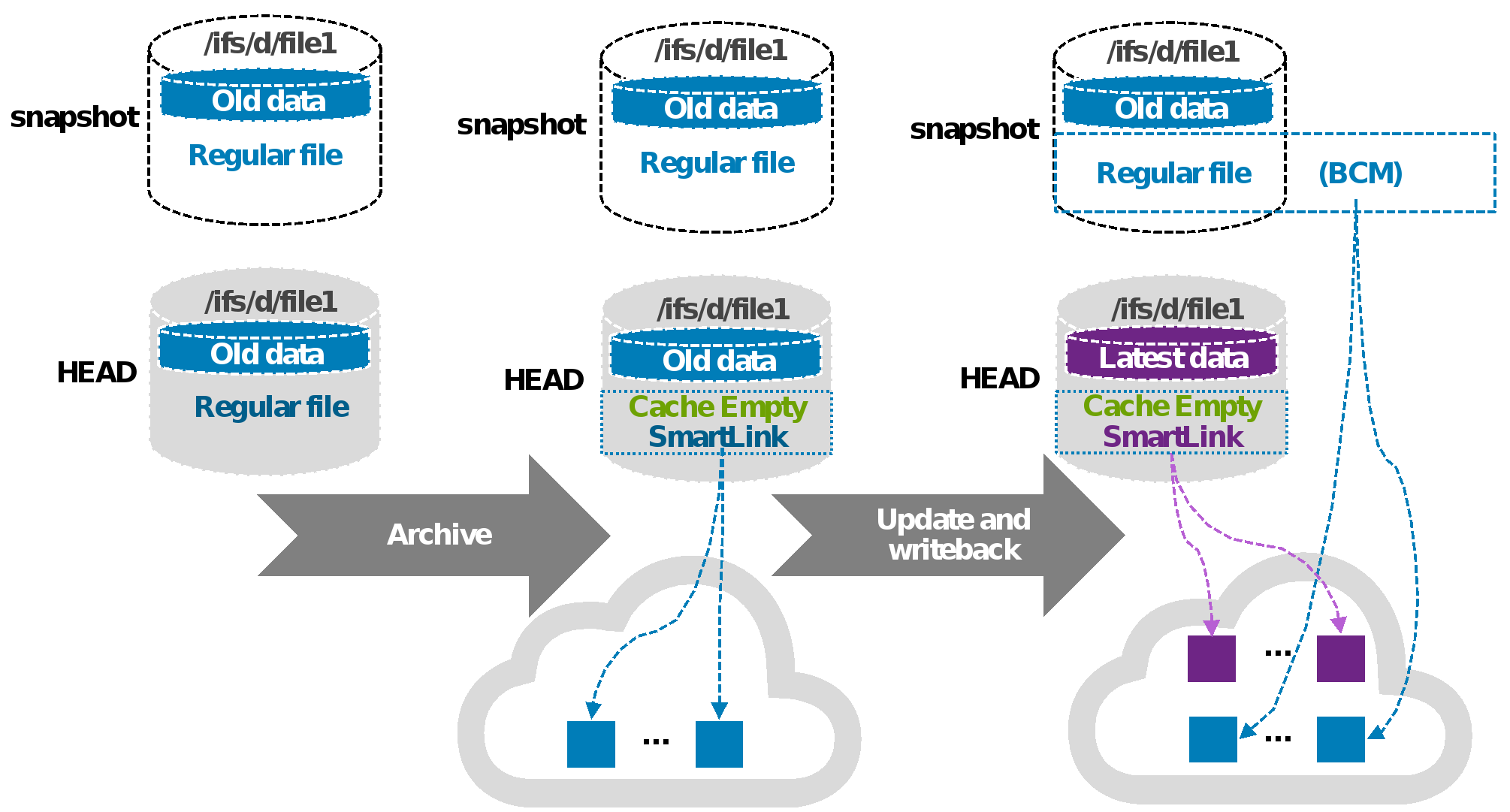
Figure 9. Scenario 4: Update HEAD when regular files are in the snapshot directory
Scenario 5
In this scenario, when reading file data from a snapshot (regular files in snapshot). File data is the same for HEAD (SmartLink file) and the same file (regular file) in the next snapshot of HEAD when not updating HEAD after the snapshot creation. File data is read from HEAD when reading the same file in the next snapshot of HEAD. This scenario does not cause the snapshot space to grow. The file in the next snapshot of HEAD is a regular file (enabled BCM). And the file has the earlier version of data when updating HEAD and performing a write-back to the cloud like in scenario 4. The earlier version of data is retrieved from the cloud by BCM. File data is stored on the PowerScale cluster when reading the earlier version of data from the regular file in the next snapshot of HEAD. The snapshot space grows, and the grown space is not released unless the snapshot is deleted.
Note: In OneFS 8.2.0, CloudPools 2.0 supports write-back in a snapshot. For details, see Scenario 3. However, CloudPools 2.0 does not support archiving and recalling files in the snapshot directory. Consider the case when there is already file data in a snapshot on a cluster running a OneFS release earlier than OneFS 8.2.0. That data takes up storage space on the PowerScale cluster, and then the cluster is upgraded to OneFS 8.2.0. Because CloudPools 2.0 does not support archiving files in snapshots to the cloud, the storage space for this snapshot cannot be released when the cluster is upgraded.
If SyncIQ or NDMP backs up the SmartLink files, the mapping file data should be retrieved from the cloud using the backup copy of the SmartLink file. If the backup retention has not expired, the CDOs of the mapping file data cannot be deleted even though the snapshot has been deleted. The reason is that the SmartLink file backup still references the CDOs of the mapping file data. When the backup retention period has expired and the CDOs of the mapping file data are no longer used, the CDOs of the mapping file data are deleted. For more information about data retention, see Data retention. If SyncIQ or NDMP does not back up SmartLink files, the CDOs of the mapping file data are deleted after the snapshot is deleted.
Users can revert a snapshot or access snapshot data through the snapshots directory (/ifs/.snapshot). The main methods for restoring data from a snapshot are as follows:
- Revert a snapshot through the SnapRevert job.
- Restore a file or directory by using Microsoft Shadow Copy Client on Windows or running the cp command on Linux.
- Clone a file from a snapshot (CloudPools does not support cloning a file from a snapshot).
For details on restoring snapshot data, see the OneFS 8.2.0 Web Administration Guide. CloudPools does not support cloning a file from a snapshot. The other two methods for restoring data from a snapshot in a CloudPools environment are described as follows.
When using the SnapRevert job to restore data from a snapshot, it reverts a directory back to the state it was in when a snapshot was taken. For example, there is a /ifs/test directory including a regular.txt regular file, and a smartlink.txt SmartLink file that has its file data archived to the cloud. A snap01 snapshot is created on the /ifs/test directory, and updates are made on the two files. The regular.txt file is then archived to the cloud, and it is truncated to a SmartLink file. Then, the SmartLink file smartlink.txt is recalled and it is converted to a regular file. If the snapshot snap01 is restored, it overwrites the files in directory /ifs/test. The regular.txt file reverts to a regular file, and smartlink.txt reverts to a SmartLink file. The directory /ifs/test is reverted to the state it was in when snap01 was taken.
When you use Microsoft Shadow Copy Client on Windows or run the cp command on Linux, the file data is retrieved from the cloud through SmartLink files in a snapshot. This copy operation creates new regular files. That means extra space is required for the new regular files restored from a snapshot.