
None
None
-
This section describes key CloudPools concepts including:
- SmartPools
- SmartLink files
- File pool policies
SmartPools
SmartPools is the OneFS data-tiering framework, of which CloudPools is an extension. SmartPools alone tiers data between different node types within a PowerScale cluster. CloudPools also adds to tier data outside of a PowerScale cluster.
SmartLink files
Although file data is moved to cloud storage, the files remain visible in OneFS. After file data has been archived to the cloud storage, the file is truncated to an 8 KB file. The 8 KB file is called a SmartLink file or stub file. Each SmartLink file contains a data cache and a map. The data cache is used to retain a portion of the file data locally, and the map points to all cloud objects.
The following figure shows the contents of a SmartLink file and the mapping to cloud objects.
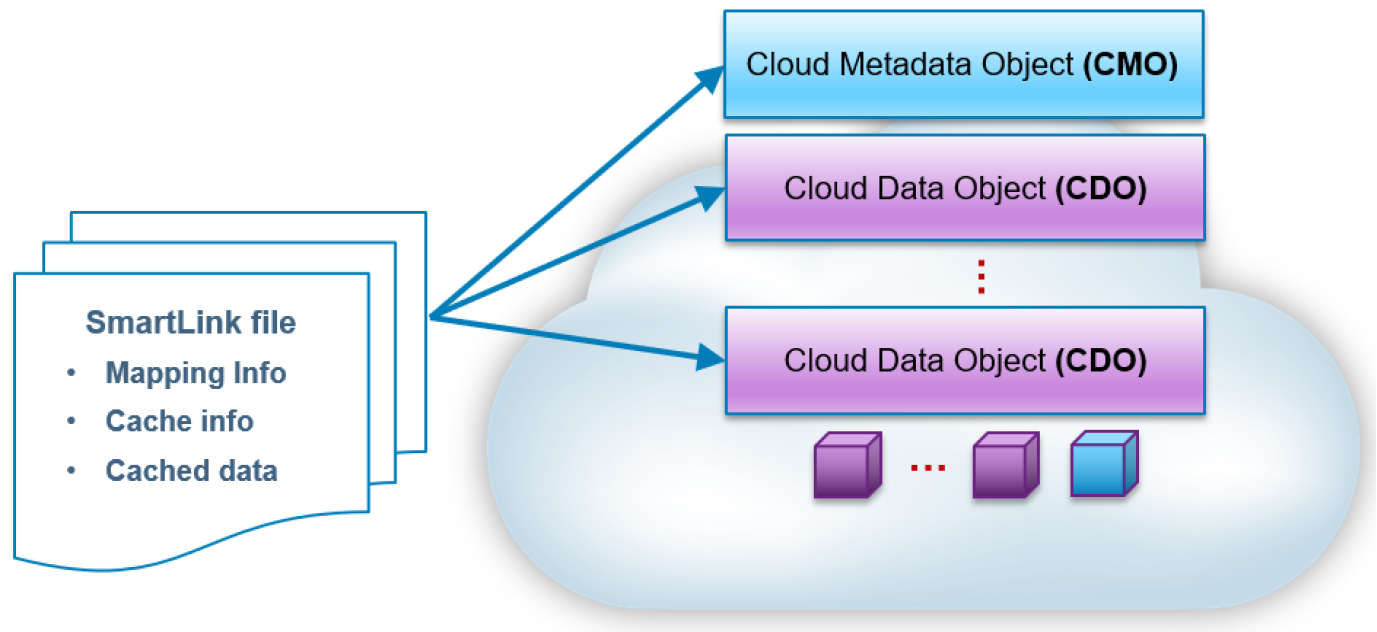
Figure 2. SmartLink file
File pool policies
Key options when configuring a file pool policy include:
- Encryption
- Compression
- File matching criteria
- Local data cache
- Date Retention
Encryption
CloudPools provides an option to encrypt data before the data is sent to the cloud storage. It uses the PowerScale key management module for data encryption and uses AES-256 as the encryption algorithm. The benefit of encryption is that only encrypted data is being sent over the network.
Compression
CloudPools provides an option to compress data before the data is sent to the cloud storage. It implements block-level compression using the zlib compression library. CloudPools does not compress data that is already compressed.
File-matching criteria
When files match a file pool policy, CloudPools moves the file data to the cloud storage. File-matching criteria enable defining a logical group of files as a file pool for CloudPools. The criteria define which data should be archived to cloud storage.
File matching criteria include:
- File name
- Path
- File type
- File attribute
- Modified
- Accessed
- Metadata changed
- Created
- Size
Any number of file-matching criteria can be added to refine a file pool policy for CloudPools.
Local data cache
Caching is used to support local reading and writing of SmartLink files. It reduces bandwidth costs by eliminating repeated fetching of file data for repeated reads and writes to optimize performance.
Note: The data cache is used for temporarily caching file data from the cloud storage on PowerScale disk storage for files that have been moved off cluster by CloudPools.
The local data cache is always the authoritative source for data. CloudPools looks for data in the local data cache first. If the file being accessed is not in the local data cache, CloudPools fetches the data from the cloud. CloudPools writes the updated file data in the local cache first and periodically sends the updated file data to the cloud.
CloudPools provides the following configurable data cache settings:
- Cache expiration: This option is used to specify the number of days until OneFS purges expired cache information in SmartLink files. The default value is one day.
- Writeback frequency: This option is used to specify the interval at which OneFS writes the data stored in the cache of SmartLink files to the cloud. The default value is nine hours.
- Cache read ahead: This option is used to specify the cache read ahead strategy for cloud objects (partial or full). The default value is partial.
- Accessibility: This option is used to specify how data is cached in SmartLink files when a user or application accesses a SmartLink file on the PowerScale cluster. Values are cached (default) and no cache.
Data retention
Data retention is a concept used to determine how long to keep cloud objects on the cloud storage. There are three different retention periods:
- Cloud data retention period: This option is used to specify the length of time cloud objects are retained after the files have been fully recalled or deleted. The default value is one week.
- Incremental backup retention period for NDMP incremental backup and SyncIQ: This option is used to specify the length of time that CloudPools retains cloud objects referenced by a SmartLink file. And SyncIQ replicates the SmartLink file or NDMP backs up the SmartLink file using an incremental NDMP backup. The default value is five years.
- Full backup retention period for NDMP only: This option is used to specify the length of time that OneFS retains cloud data referenced by a SmartLink file. And NDMP backs up the SmartLink file using a full NDMP backup. The default value is five years.
Note: If more than one period applies to a file, the longest period is applied.