
Cache prefetching
Cache prefetching
-
For read caching to be beneficial for reads, the cache must already contain data before it is requested. The storage system must accurately determine file access patterns and prepopulate the cache with data, and metadata blocks, before they are requested. OneFS uses two primary sources of information for predicting a file’s access pattern:
- OneFS attributes that can be set on files and directories to provide hints to the file system.
- The read activity occurring on the file.
This technique is known as prefetching, whereby predictively copying data into a cache before it has been requested mitigates the latency of an operation. Data prefetching is employed frequently and is a significant benefactor of the OneFS flexible file allocation strategy.
The most straightforward application of prefetch is file data, where linear access is common for unstructured data, such as media files. Reading and writing of such files generally starts at the beginning and continues unimpeded to the end of the file. After a few requests, it becomes highly likely that a file is being streamed to the end.
OneFS data prefetch strategies can be configured either from the command line or using SmartPools. File data prefetch behavior can be controlled down to a per-file granularity using the isi set command’s access pattern setting. The available selectable file access patterns include concurrency (the default), streaming, and random.
Metadata prefetch occurs for the same reason as file data, particularly benefiting scanning operations, such as finds and tree walks. To ensure that metadata keeps up with data block prefetching, OneFS 9.5 and later releases include both a metadata prefetcher and lock prefetcher. They are automatically enabled for concurrent and streaming data access patterns but remain inactive for random access where there is typically little benefit.
Default settings
Concurrency is the default setting for all file data.
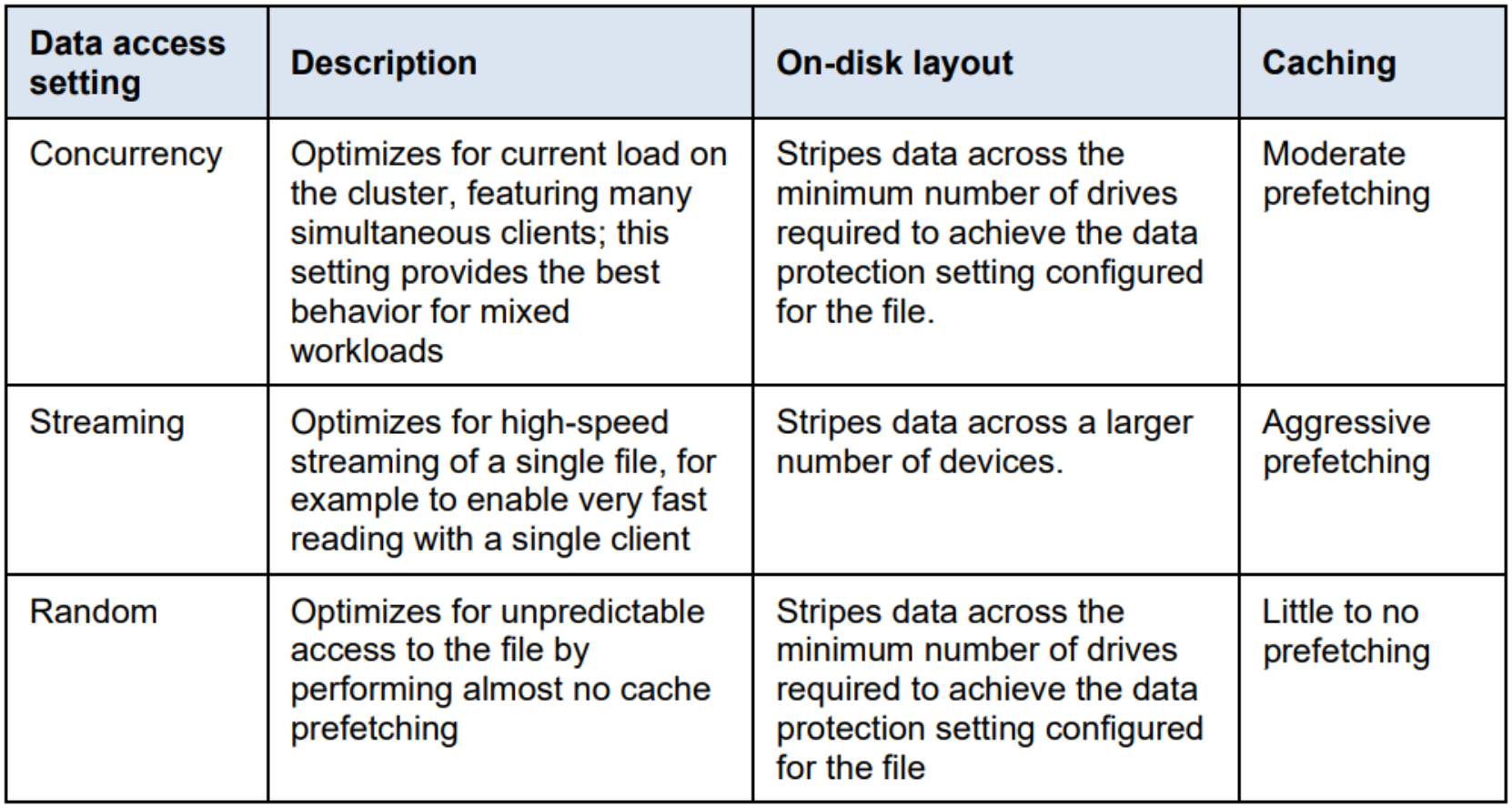
Figure 9. OneFS data access settings
Recommended settings
EDA workloads perform huge amount of concurrent I/O operations when thousands of jobs are running and accessing the same project folders.
Optimize for concurrent access (the default setting for all file data) is the recommended access setting for mixed EDA workloads.
Update the tunable
WebUI > File System > Storage pools > File pool policies > view/edit Default policy.

Figure 10. Set data access pattern optimization.