
None
None
-
The Riva services are validated by running the Riva ASR and Riva TTS tests.
Riva ASR workload
To run the Riva ASR test, start an interactive session with Riva client container, and run the following command. This command takes in the sample .wav file and converts it into text. The same .wav file is already present in the Riva client container.
[root@ocp411-admin Riva]# kubectl exec --stdin --tty $cpod /bin/bash
root@riva-client-668dd7594b-cr68q:/opt/riva# riva_streaming_asr_client \
> --audio_file=wav/en-US_sample.wav \
> --automatic_punctuation=true \
> --riva_uri=traefik.default.svc.cluster.local:80
Riva ASR service converts the .wav file into text as follows:
I0512 13:00:14.664886 47228 riva_streaming_asr_client.cc:150] Using Insecure Server Credentials
Loading eval dataset...
filename: /opt/riva/wav/en-US_sample.wav
Done loading 1 files
what
what
what is
what is
what is
what is now
what is natural
what is natural
what is natural language
what is natural language
what is natural language
what is natural language
what is natural language Processing
what is natural language Processing
what is natural language Processing
what is natural language Processing
what is natural language Processing
what is language Processing
what is language Processing
What is Natural Language Processing?
-----------------------------------------------------------
File: /opt/riva/wav/en-US_sample.wav
Final transcripts:
0 : What is Natural Language Processing?
Timestamps:
Word Start (ms) End (ms)
What 840 880
is 1160 1200
Natural 1800 2080
Language 2200 2520
Processing? 2720 3200
Audio processed: 4 sec.
-----------------------------------------------------------
Not printing latency statistics because the client is run without the --simulate_realtime option and/or the number of requests sent is not equal to number of requests received. To get latency statistics, run with --simulate_realtime and set the --chunk_duration_ms to be the same as the server chunk duration
Run time: 0.1486 sec.
Total audio processed: 4.152 sec.
Throughput: 27.9407 RTFX
Next, performance testing of Riva ASR service occurs. The Riva streaming client riva_streaming_asr_client, which is provided in the Riva image, is used with the simulate_realtime flag to simulate the transcription from a microphone, where each stream was doing three iterations over a sample audio file (1272-135031-0000.wav) from the LibriSpeech dev-clean dataset. The Librispeech datasets are available from Open SLR.
The command used to measure validation is:
riva_streaming_asr_client \
--chunk_duration_ms=<chunk_duration> \
--simulate_realtime=true \
--automatic_punctuation=true \
--num_parallel_requests=<num_streams> \
--word_time_offsets=true \
--print_transcripts=false \
--interim_results=false \
--num_iterations=<3*num_streams> \
--audio_file=1272-135031-0000.wav \
--output_filename=/tmp/output.json
The preceding command is run for various streams starting with 1. Then, for each run, the stream is changed to 8,16, 32, 48, and 64 as shown in the following graph. During the performance test, the average latency is calculated along with the throughput.
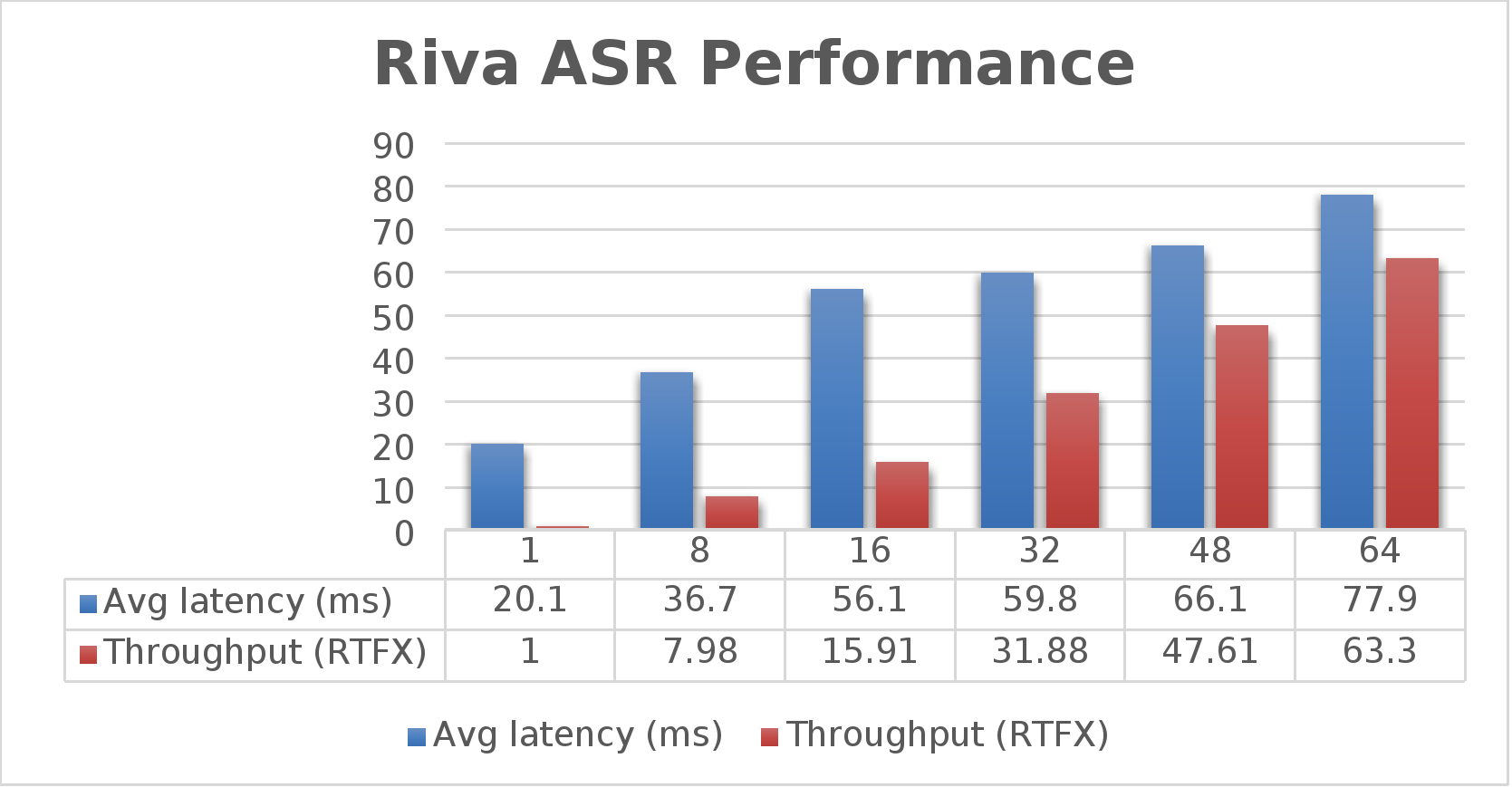
Figure 7. Riva ASR performance (low latency)
To measure the performance of the GPU on the PowerFlex CO node, the NVIDIA GPU administration dashboard is enabled. The OpenShift Console NVIDIA GPU plugin is a dedicated administration dashboard for visualizing the NVIDIA GPU usage in the OpenShift Container Platform (OCP) console.
To get the streaming and high throughput numbers for Riva ASR, the chunk size (ms) is kept at 900 and the maximum effective number of streams without language model (greedy generation) is set to 750. For each run, the stream is changed to 1,64, 128, 256, 384, and 512 as shown in the following graph. During the performance test, the average latency is calculated along with the throughput.
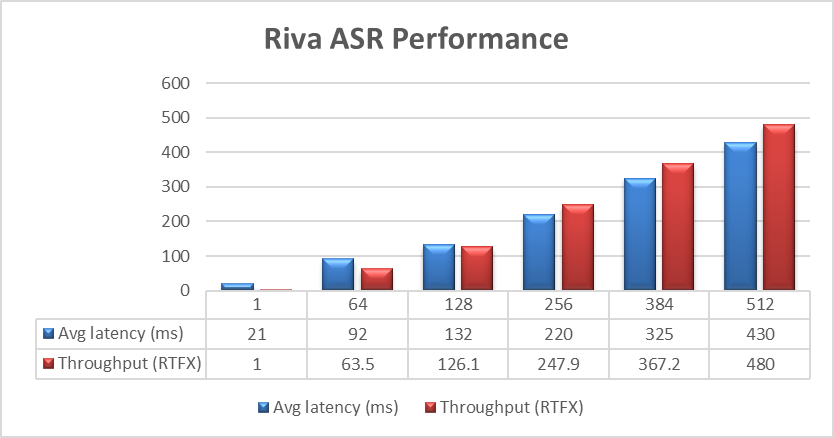
Figure 8. Riva ASR performance (high throughput)
Note: During the test of every stream, the GPU utilization was about 48 percent. No PowerFlex storage bottlenecks were seen anywhere during the testing.
Riva TTS workload
To run the Riva ASR test, start an interactive session with Riva client container, and run the following command:
root@riva-client-668dd7594b-cr68q:/opt/riva#
riva_tts_client --text="PowerFlex software-defined infrastructure enables broad consolidation across the data center, encompassing almost any type of workload and architecture."
--audio_file =/opt/riva/wav/output.wav --voice_name=English-US.Male-1 --riva_uri=traefik.default.svc.cluster.local:80
Riva TTS service converts the text into a .wav file which is published at /opt/riva/wav/output.wav.
I0525 04:23:41.519158 265654 riva_tts_client.cc:99] Using Insecure Server Credentials
Request time: 0.261046 s
Got 776704 bytes back from server
The testing team carried out performance testing on the Riva TTS service. The Riva TTS performance client riva_tts_perf_client, which is provided in the Riva image, measures the performance.
The following command is used to measure validation:
riva_tts_perf_client \
--num_parallel_requests=<num_streams> \
--voice_name=English-US.Female-1 \
--num_iterations=<20*num_streams> \
--online=true \
--text_file=$test_file \
--write_output_audio=false
Where test_file is a path to the ljs_audio_text_test_filelist_small.txt file.
The preceding command is run for various streams starting with 1. Then, for each run, the stream is changed to 4, 6, 8, and 10 as shown in the following graph. During the performance test, the average latency is calculated along with the throughput.
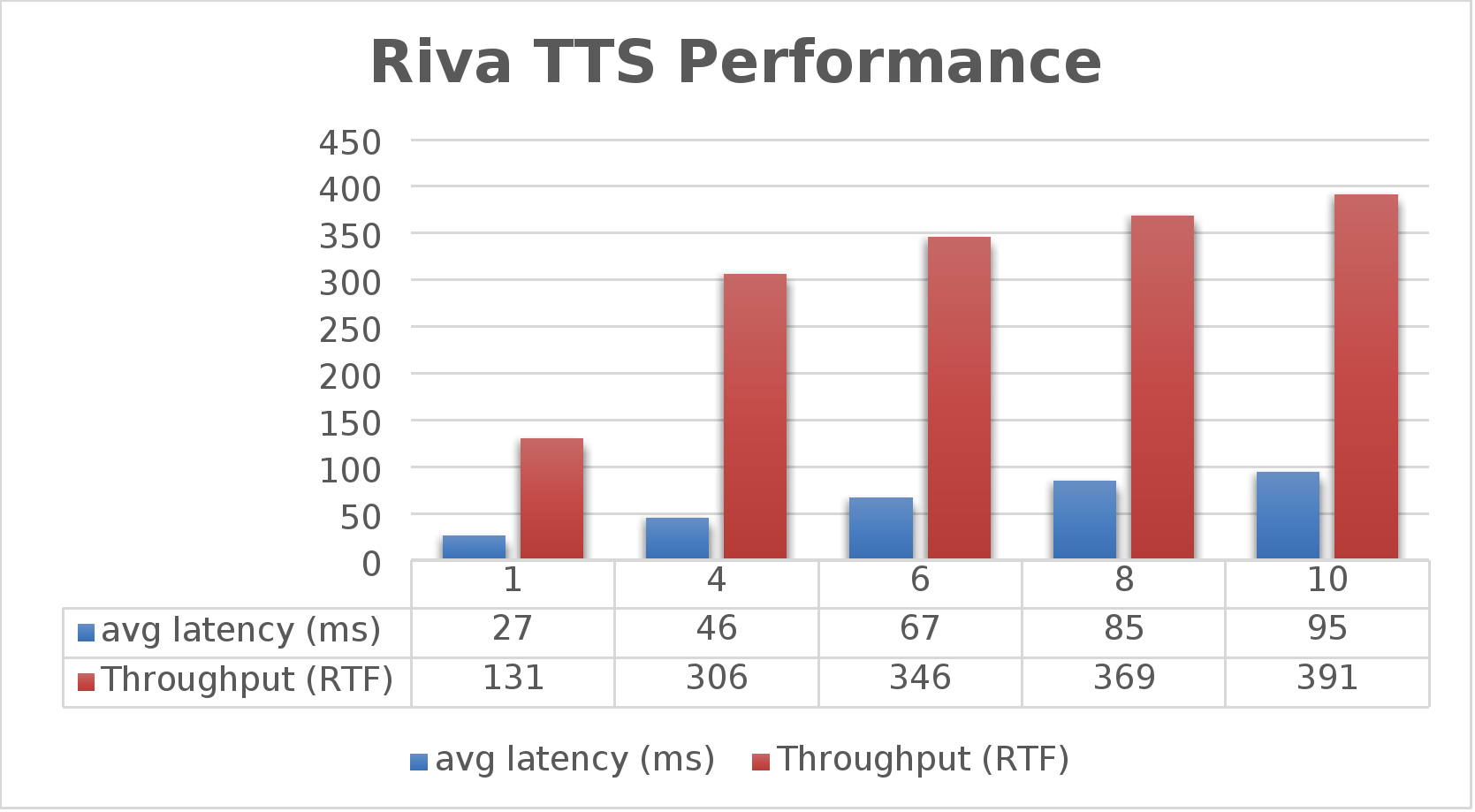
Figure 9. Riva TTS performanceTo measure the performance of GPU on the PowerFlex CO node, the NVIDIA GPU administration dashboard is enabled. The OpenShift Console NVIDIA GPU plugin is a dedicated administration dashboard for NVIDIA GPU usage visualization in the OpenShift Container Platform (OCP) console.
Note: During the test for every stream, the GPU utilization observed was approximately 82 percent. No PowerFlex storage bottlenecks were seen anywhere during the testing.