
Inline deduplication
Inline deduplication
-
While OneFS has offered a native file-system deduplication solution for several years, until OneFS 8.2.1, this ability was accomplished by scanning the data after it was written to disk, or post-process. With inline data reduction, deduplication is now performed in real time, as data is written to the cluster. Storage efficiency is achieved by scanning the data for identical blocks as it is received and then eliminating the duplicates.
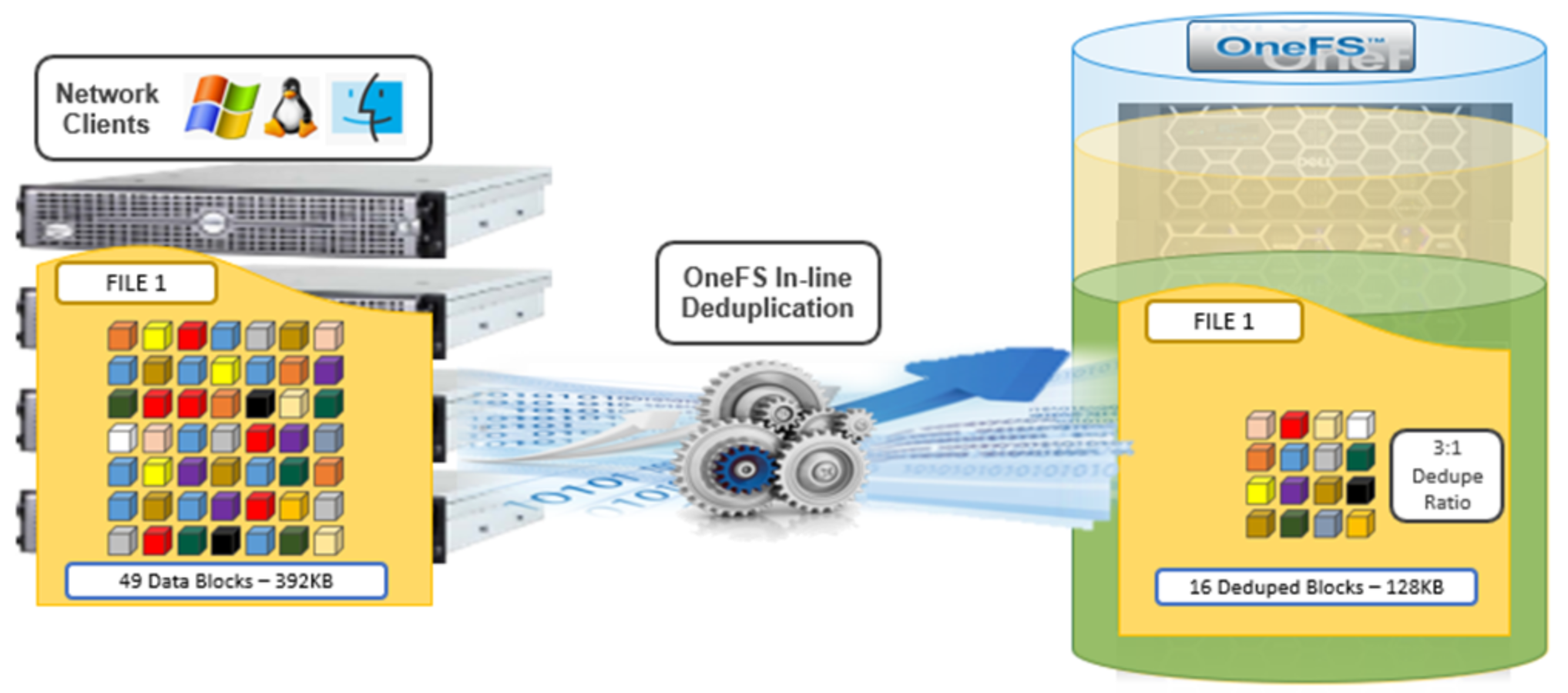
Figure 3. OneFS inline deduplication
When a duplicate block is discovered, inline deduplication moves a single copy of the block to a special set of files known as shadow stores. OneFS shadow stores are file system containers that allow data to be stored in a shareable manner. As such, files on OneFS can contain both physical data and pointers, or references, to shared blocks in shadow stores.
Shadow stores were first introduced in OneFS 7.0, initially supporting OneFS file clones, and there are many overlaps between cloning and deduplicating files. The other main consumer of shadow stores is OneFS Small File Storage Efficiency. This feature maximizes the space utilization of a cluster by decreasing the amount of physical storage required to house the small files that consist of a typical healthcare dataset.
Shadow stores are similar to regular files but are hidden from the file system namespace, so they cannot be accessed by a pathname. A shadow store typically grows to a maximum size of 2 GB, which is around 256 K blocks, with each block able to be referenced by 32,000 files. If the reference count limit is reached, a new block is allocated, which may or may not be in the same shadow store. Also, shadow stores do not reference other shadow stores. And snapshots of shadow stores are not permitted because the data contained in shadow stores cannot be overwritten.
When a client writes a file to a node pool configured for inline deduplication on a cluster, the write operation is divided up into whole 8 KB blocks. Each of these blocks is hashed, and its cryptographic ‘fingerprint’ is compared against an in-memory index for a match. At this point, one of the following operations will occur:
- If a match is discovered with an existing shadow store block, a byte-by-byte comparison is performed. If the comparison is successful, the data is removed from the current write operation and replaced with a shadow reference.
- When a match is found with another LIN, the data is written to a shadow store instead and replaced with a shadow reference. Next, a work request is generated and queued that includes the location for the new shadow store block, the matching LIN and block, and the data hash. A byte-by-byte data comparison is performed to verify the match, and the request is processed.
- If no match is found, the data is written to the file natively and the hash for the block is added to the in-memory index.
In order for inline deduplication to be performed on a write operation, the following conditions need to be true:
- Inline deduplication must be globally enabled on the cluster.
- The current operation is writing data (not a truncate or write zero operation).
- The ‘no_dedupe’ flag is not set on the file.
- The file is not a special file type, such as an alternate data stream (ADS) or an EC (endurant cache) file.
- Write data includes fully overwritten and aligned blocks.
- The write is not part of a ‘rehydrate’ operation.
- The file has not been packed (containerized) by SFSE (small file storage efficiency).
OneFS inline deduplication uses the 128-bit CityHash algorithm, which is both fast and cryptographically strong. This contrasts with the OneFS post-process SmartDedupe, which uses SHA-1 hashing.
Each F910, F900, F810, F600, F200, F700/7000, H5600, or A300/3000 node in a cluster with inline deduplication enabled has its own in-memory hash index that it compares block ‘fingerprints’ against. The index is in system RAM, is allocated using physically contiguous pages, and is accessed directly with physical addresses. This system avoids the need to traverse virtual memory mappings and does not incur the cost of translation lookaside buffer (TLB) misses, minimizing deduplication performance impact.
The maximum size of the hash index is governed by a pair of sysctl settings, one of which caps the size at 16 GB, and the other which limits the maximum size to 10% of total RAM. The strictest of these two constraints applies. While these settings are configurable, the recommended best practice is to use the default configuration. Any changes to these settings should only be performed under the supervision of Dell support.
Since inline deduplication and SmartDedupe use different hashing algorithms, the indexes for each are not shared directly. However, the work performed by each deduplication solution can be used by each other. For instance, if SmartDedupe writes data to a shadow store, when those blocks are read, the read hashing component of inline deduplication will see those blocks and index them.
When a match is found, inline deduplication performs a byte-by-byte comparison of each block to be shared to avoid the potential for a hash collision. Data is prefetched before the byte-by-byte check and then compared against the L1 cache buffer directly, avoiding unnecessary data copies and adding minimal overhead. Once the matching blocks have been compared and verified as identical, they are shared by writing the matching data to a common shadow store and creating references from the original files to this shadow store.
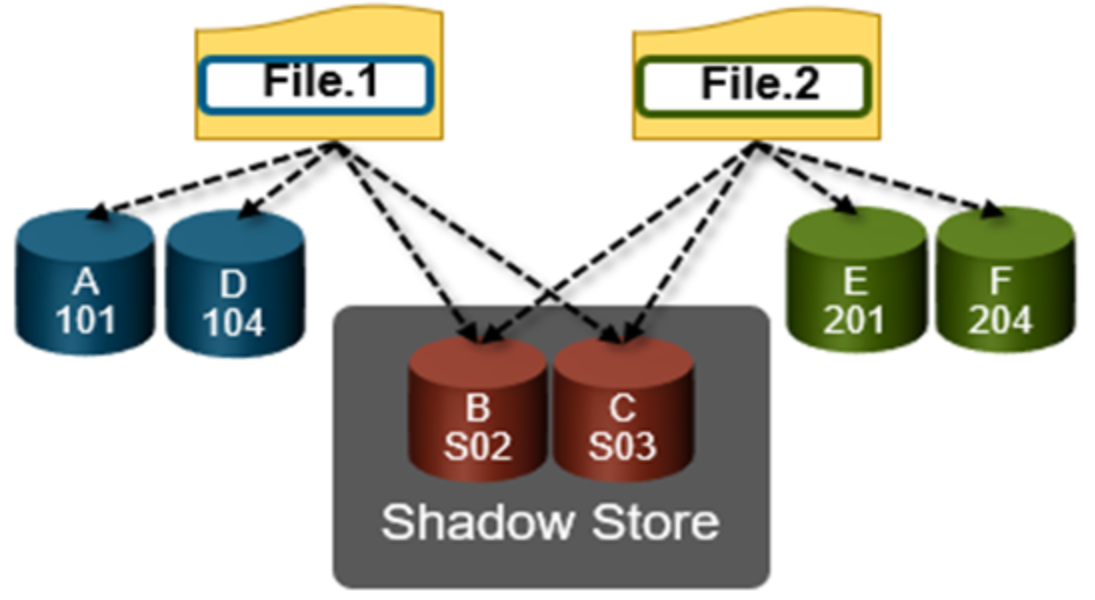
Figure 4. OneFS duplicate block sharing
Inline deduplication samples every whole block written and handles each block independently, so it can aggressively locate block duplicity. If a contiguous run of matching blocks is detected, inline deduplication will merge the results into regions and process them efficiently.
Inline deduplication also detects deduplication opportunities from the read path, and blocks are hashed as they are read into L1 cache and inserted into the index. If an existing entry exists for that hash, inline deduplication detects there is a block-sharing opportunity between the block that it most recently read and the one previously indexed. It combines that information and queues a request to an asynchronous deduplication worker thread. As such, it is possible to deduplicate a dataset purely by reading it all. To help mitigate the performance impact, the hashing is performed out-of-band in the prefetch path, rather than in the latency-sensitive read path.