
Data reduction write path
Data reduction write path
-
In a PowerScale cluster, data, metadata, and inodes are all distributed across multiple drives on multiple nodes. When reading or writing to the cluster, a client is directed by SmartConnect to the desired protocol head on a particular node, or initiator. This node then acts as the ‘captain’ for the operation. It performs the chunking and data compression, orchestrates the layout of data and metadata, creates erasure codes, and performs normal operations of lock management and permissions control.
For example, assume you have a four-node F810 cluster. A Windows client connects to the top half, or initiator, on node 1 to write a file. After the SMB session is established and write request granted, the client begins to send the file data across the front-end network to the cluster where it is initially buffered in the coalescer, or OneFS write cache. The purpose of the coalescer is to build up a large contiguous range of data that will make the write operation more efficient.
When the coalescer is flushed, data chunks, typically sized on protection group boundaries, are passed through the data reduction pipeline. First, if inline deduplication is enabled, the incoming data is scanned for zero block removal and deduplication opportunities. When found, any zero blocks are stripped out and any matching blocks are deduplicated. Next, chunks that meet the ‘compressibility’ criteria described above are compressed by the FPGA. Finally, the initiator runs its ‘write plan’ for the file data. This action optimizes for layout efficiency and the selected protection policy, and the chunks/stripes are written to SSDs on the bottom half of the participant nodes.
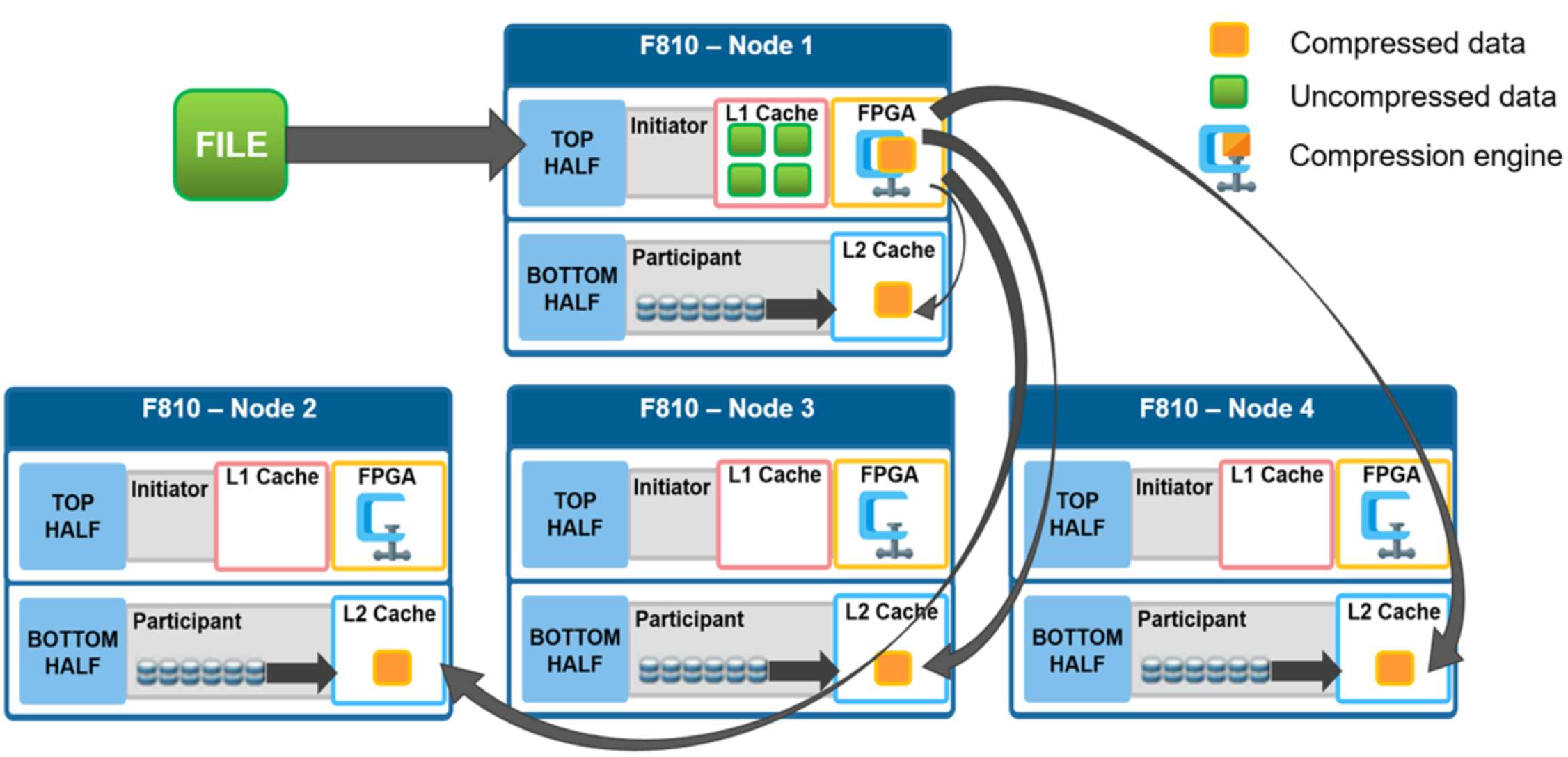
Figure 7. File writes with compression
OneFS stripes data across all nodes—and not simply across disks—and protects the files, directories, and associated metadata using software erasure-code or mirroring technology. Erasure coding can provide beyond 80% efficiency on raw disk with five nodes or more, and on large clusters can even do so while providing quadruple-level redundancy. For any given file, the stripe width is the number of nodes (not disks) that a file is written across. For example, on the 4-node F810 cluster above with the recommended +2d:1n protection level, OneFS will use a stripe width of 8 and protection level of 6+2, where each node is used twice: Two data stripe units are written to each of three nodes, and two FEC units to the remaining node.
For further details about OneFS data protection, see the OneFS Technical Overview white paper.