
Data reduction read path and caching integration
Data reduction read path and caching integration
-
In the diagram below, an NFS client attaches to node 1 and issues a read request for a file. Node 1, the captain, gathers all the chunks of data from the various nodes in the cluster and presents it in a cohesive way to the requesting client. Since the file’s data has been stored in a compressed form on nodes’ SSDs, node 1 needs to gather all the constituent chunks and decompress the data so the file can be sent across the wire to the client in its original form.
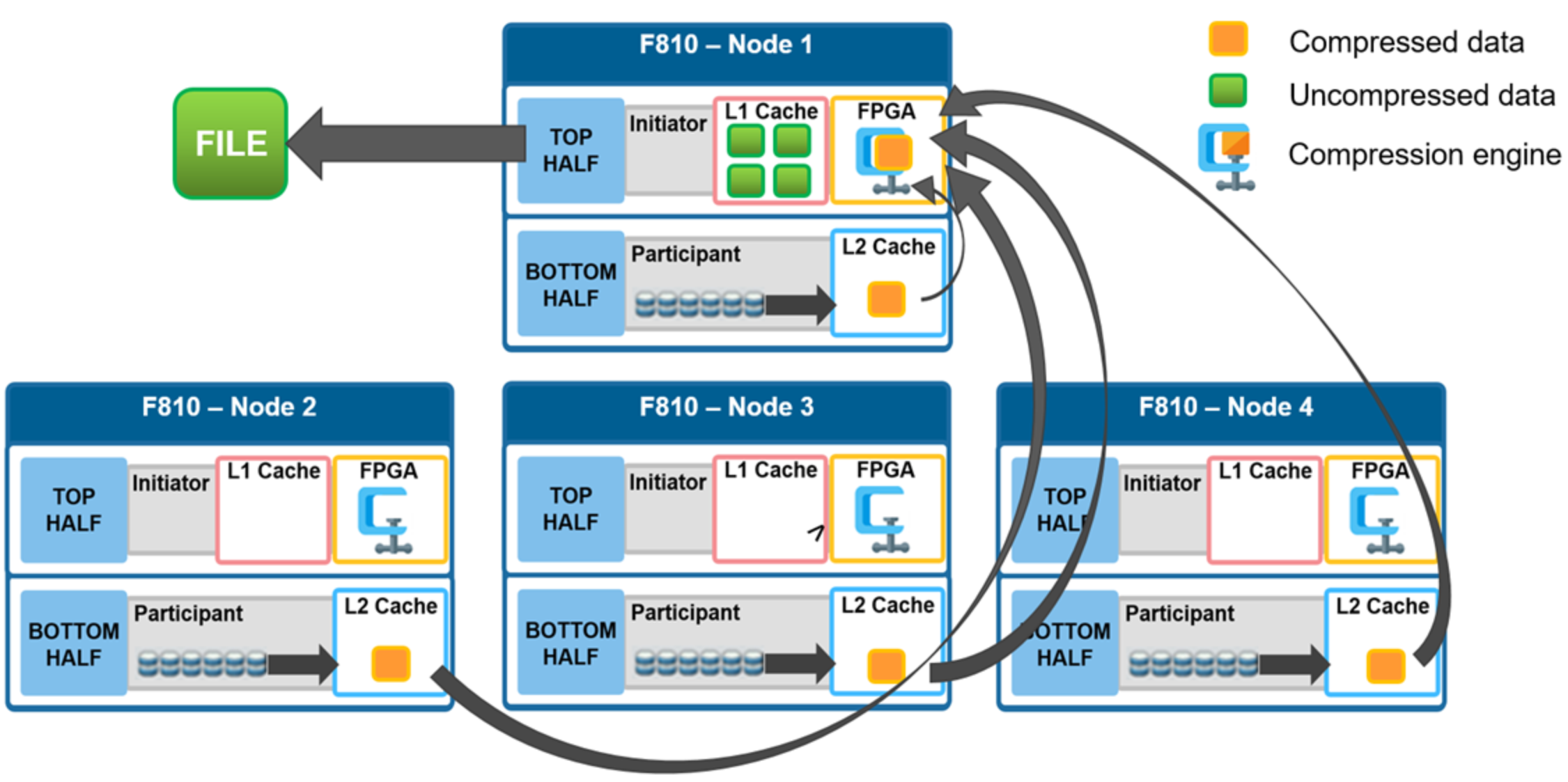
Figure 8. File reads with compression
During this read process, the L2 read cache on the participant nodes (nodes 2-4) is populated with the compressed data chunks that are sent to node 1. This means that any additional read requests for this file can be served straight from low latency cache, rather than reading again from the drives. This process both accelerates read performance and reduces wear on the SSDs.
To support OneFS inline compression, a node’s L1, or client-side, read cache is divided into separate address spaces so that both the on-disk compressed data and the logical uncompressed data can be cached. The address space for the L1 cache is already split for data and FEC blocks, so a similar technique is used to divide it again. Data in the uncompressed L1 cache is fed from data in the compressed L1 cache which, in turn, is fed from disk.
OneFS prefetch caching has also been enhanced to accommodate compressed data. Since reading part of a compressed chunk results in the entire compression chunk being cached, it will effectively mean that prefetch requests are rounded to compression chunk boundaries. Since a prefetch request is not complete until the uncompressed data is available in cache, the callback used for prefetch requests performs the decompression.