
Data reduction and tiering in a mixed cluster
Data reduction and tiering in a mixed cluster
-
Consider a mixed cluster consisting of an F810 flash performance tier and an A2000 archive tier. SmartPools is licensed, and a file pool policy is crafted to move data over three months old from the F810 flash tier to the archive tier. Files are stored in a compressed form on the F810 tier.
When SmartPools runs, decompression occurs as the files targeted for down-tiering are restriped from the F810 tier to the A2000 tier inside the SmartPools job. The SmartPools job runs across all the nodes in the cluster, both the F810 and A2000, and the availability of hardware assisted decompression depends on which node or nodes are running the job worker threads. After files are on the A2000 tier, they remain uncompressed.
If a file has been deduplicated, whether by inline or post process deduplication, the deduplicated state of the file will remain unchanged when tiered. This is true even if the file is moved from a disk pool that supports data reduce to a disk pool that does not.
If another file pool policy is created to up-tier files from the A2000 back up to the F810, the file chunks will be compressed when they are restriped onto the F810 nodes. Once again, all nodes in the cluster will participate in the SmartPools job.
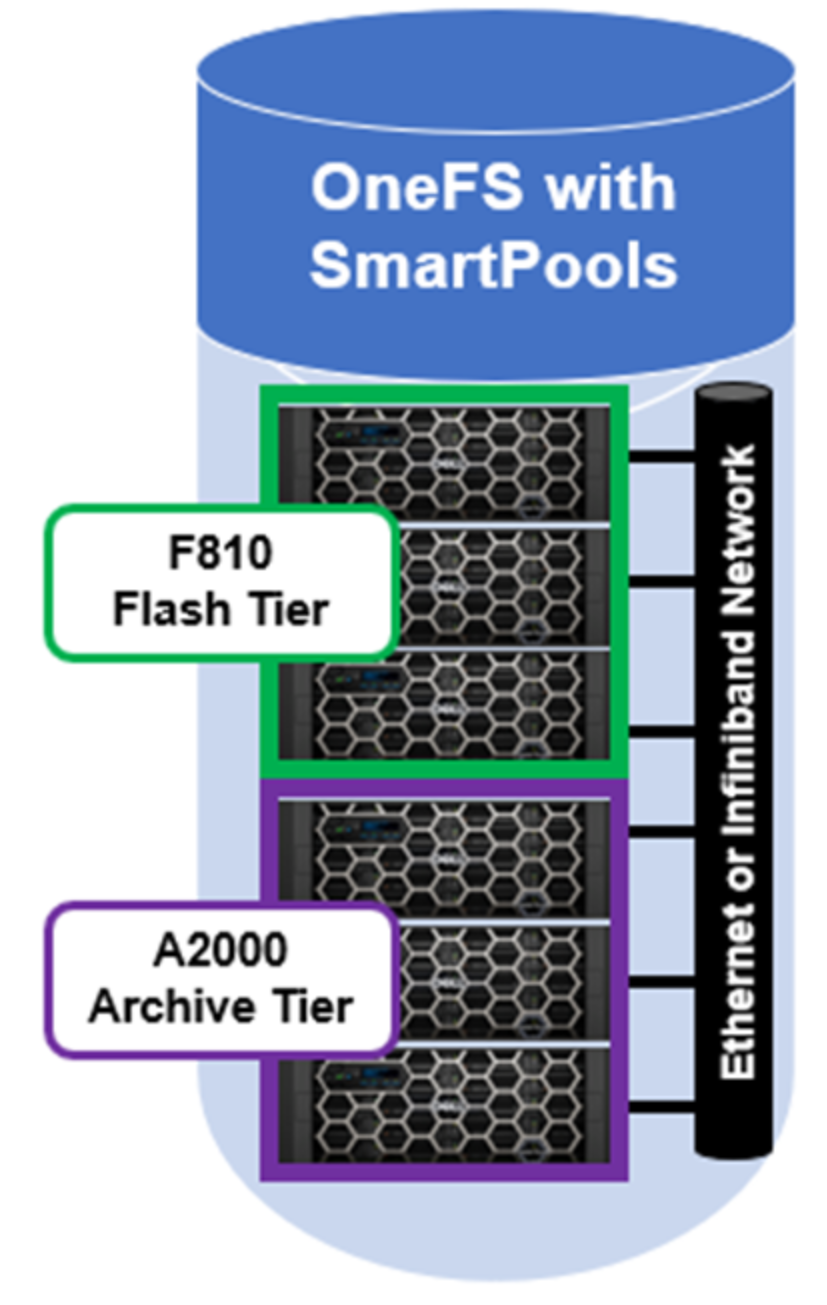
Figure 11. A SmartPools cluster with an all-flash performance tier and an archive tier
As data moves between tiers in a mixed cluster, it must be re-written from the old to new drives. If the target tier has a different ‘data-reduce’ setting than the source tier, data is compressed or decompressed as appropriate. The sizing of the F810 pool should be independent of whether it is participating in a mixed cluster or not. However, because up-tiering using the job-engine can run job tasks on the lower tier nodes, the achievable compression ratios may be slightly less efficient when software compression is used.