
Amazon EMR on PowerScale installation
Amazon EMR on PowerScale installation
-
The main objective of this solution is to install Amazon EMR big data cluster on PowerScale. PowerScale supplies the HDFS storage for the EMR compute cluster.
Prerequisites
Set up Amazon EMR
Before you launch an Amazon EMR cluster, ensure you complete the tasks in Setting Up Amazon EMR.
Set up PowerScale for HDFS storage
- Create a Faction subscription.
- Enable the HDFS service on the PowerScale.
- Set up the HDFS access zone. See the Cloudera CDP on PowerScale install guide.
- Set up users and groups described in Create users and groups on the OneFS cluster using Tools for Using Hadoop with OneFS.
Amazon EMR tasks
Step 1: Plan and configure
In this step, plan for and launch a simple Amazon EMR cluster with selected service like Apache Spark, hive, hbase, and other services installed. The setup process includes creating a PowerScale HDFS storage area to store a sample script like pySpark and others, an input dataset, and cluster output.
- Prepare storage for cluster input and output:
The PowerScale setup with HDFS access zone is used here to store scripts jobs like PySpark script, input data, and output data.
- Develop and prepare an application for Amazon EMR:
This step uploads a sample script or jobs like PySpark script to the PowerScale HDFS location. This is the most common way to prepare an application for Amazon EMR. EMR lets you specify the PowerScale HDFS location of the script when you submit work to your cluster. You can also upload sample input data to PowerScale HDFS for the script to process.
- Launch an Amazon EMR cluster:
Now that you have completed the prework, you can launch a sample cluster with services like Apache Spark installed using the latest Amazon EMR release.
Launch a cluster with Spark installed using Quick Options:
- Sign in to the AWS Management Console and open the Amazon EMR console at https://console.aws.amazon.com/elasticmapreduce/.
- Choose Create cluster to open the Quick Options wizard.
- On the Create Cluster > Quick Options page, note the default values for Release, Instance type, Number of instances, and Permissions. These fields automatically populate with values chosen for general-purpose clusters. For more information about the Quick Options configuration settings, see Summary of Quick Options.
- Enter a Cluster name to help you identify the cluster. For example, My First EMR Cluster.
- Leave Logging enabled, but replace the S3 folder value with the Amazon S3 bucket you created, followed by /logs. For example, s3://DOC-EXAMPLE-BUCKET/logs. This will create a folder called logs in your bucket, where EMR will copy the log files of your cluster. PowerScale hdfs path can also be used here to place the logs.
- Under Applications, choose the services you want example Spark option to install Spark on your cluster. Quick Options lets you select from the most common application combinations.
Note: Choose the applications that you want to run on your Amazon EMR cluster before you launch the cluster. You cannot add or remove applications from a cluster after it has been launched.
- Under Security and access, choose the EC2 key pair that you designated or created in Create an Amazon EC2 Key Pair for SSH.
Note: The following step is important to make this solution functional. Here we change the default file system of Amazon EMR to PowerScale HDFS file system and use the same for different services like yarn, spark, hive, and others.
- Override the default configurations.
This is important because it replaces the default HDFS file system to PowerScale HDFS. To make this change, you can supply a configuration object. You can either use a shorthand syntax to provide the configuration, or reference the configuration object in a JSON file. Configuration objects consist of a classification, properties, and optional nested configurations. Properties correspond to the application settings you want to change. You can specify multiple classifications for multiple applications in a single JSON object.
The following is an example JSON file for a list of configurations.
[
{
"Classification": "core-site",
"Properties": {
"fs.defaultFS": "hdfs://powerscale_fqdn:8020"
}
},
{
"Classification": "hive-site",
"Properties": {
"fs.defaultFS": "hdfs://powerscale_fqdn:8020"
}
}
]
- Choose Create cluster to launch the cluster and open the cluster status page.
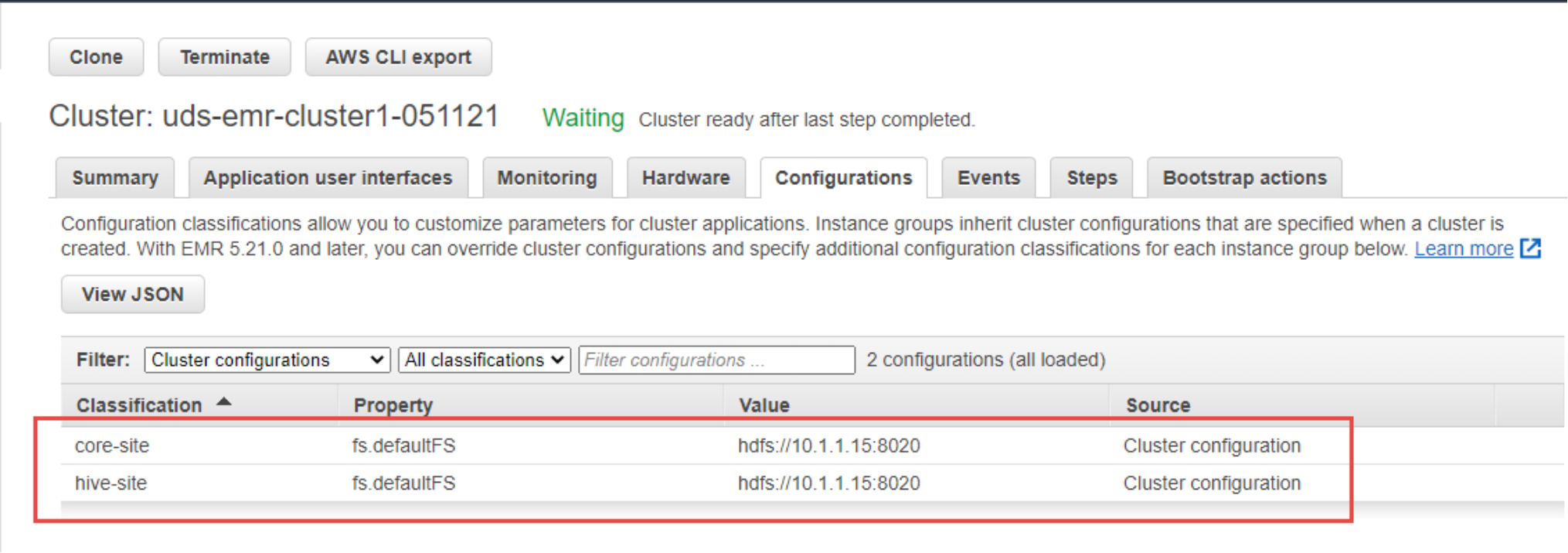
Figure 5. Amazon EMR updated configuration
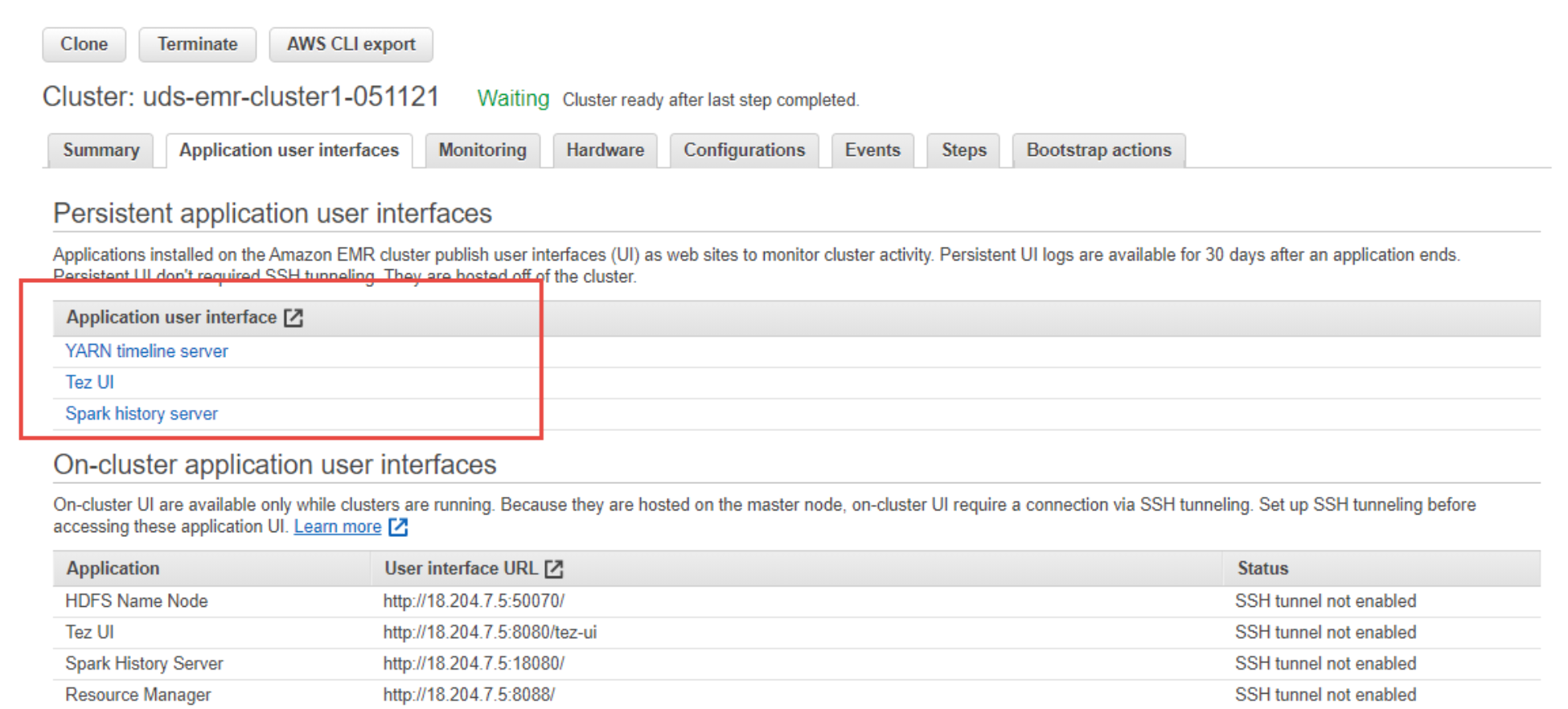
Figure 6. Amazon EMR Application user interface
- On the cluster status page, find the Status next to the cluster name. The status should change from Starting to Running to Waiting during the cluster creation process. You may need to choose the refresh icon on the right or refresh your browser to receive updates.
When the status progresses to Waiting, your cluster is running and ready to accept work.
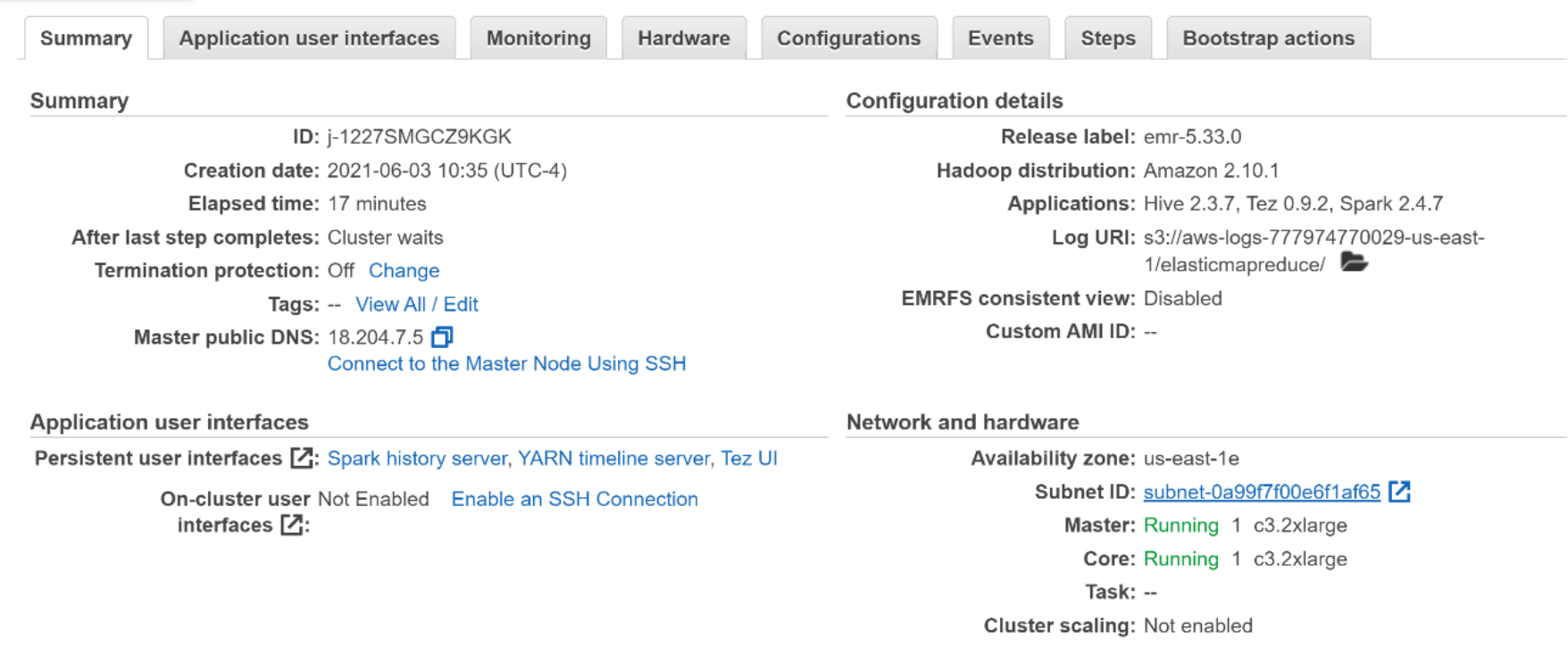
Figure 7. Amazon EMR cluster with PowerScale HDFS as default file system summary
Step 2: Manage
Now that your cluster is running, connect to it and manage it. You can also submit work to your running cluster to process and analyze data.
- Submit work to Amazon EMR:
With your cluster up and running, you can submit health_violations.py as a step. A step is a unit of cluster work made up of one or more jobs. For example, you might submit a step to compute values, or to transfer and process data.
You can submit multiple steps to accomplish a set of tasks on a cluster when you create the cluster, or after it is already running. For more information, see Submit Work to a Cluster.
- View results:
After a step runs successfully, you can view its output results in the PowerScale HDFS output folder you specified when you submitted the step.
- (Optional) set up cluster connections:
This step is not required, but you can connect to cluster nodes with Secure Shell (SSH) for tasks like issuing commands, running applications interactively, and reading log files.
Step 3: Clean up your Amazon EMR resources
Now that you have submitted work to your cluster and viewed the results of your sample application, you can shut the cluster down. You have option to retain or delete the data from the PowerScale HDFS cluster.
- Shut down your cluster:
Shutting down a cluster stops all its associated Amazon EMR charges and Amazon EC2 instances.
- Delete PowerScale HDFS resources:
This is optional since you can delete or retain the input dataset, cluster output, script, and log files.