
Microsoft SQL Server 2019
Microsoft SQL Server 2019
-
To optimize the use of Intel Optane PMem capabilities, applications must be modified to handle underlying data in a non-traditional manner (using file system APIs). At the time of this publication, few applications have completed the required changes to their code base.
Application code modifications became necessary with SQL Server 2016 SP1. Microsoft has added significant features for placing “persisted log buffer” to persistent memory that is configured in App Direct Mode with Direct Access (DAX) formatting.
SQL Server 2019 adds significant features—Tail of Log, enlightenment, and the hybrid buffer pool—that enable better use of PMem modules in a more transparent and consistent way to meet the ever-increasing performance demand.
The following sections describe each of these features.
Tail of Log
During normal database transactions, at any given time, various log blocks are in the process of moving to stable media. This volatile portion of the log is considered the “Tail of Log”. Tail of Log (or log buffer) is a portion of the log (LDF) file that is still in log cache. This portion of the log is actively receiving transactions and has yet to be flushed to persistent media.
The following figure shows that the SQL Server Log Cache is in memory:
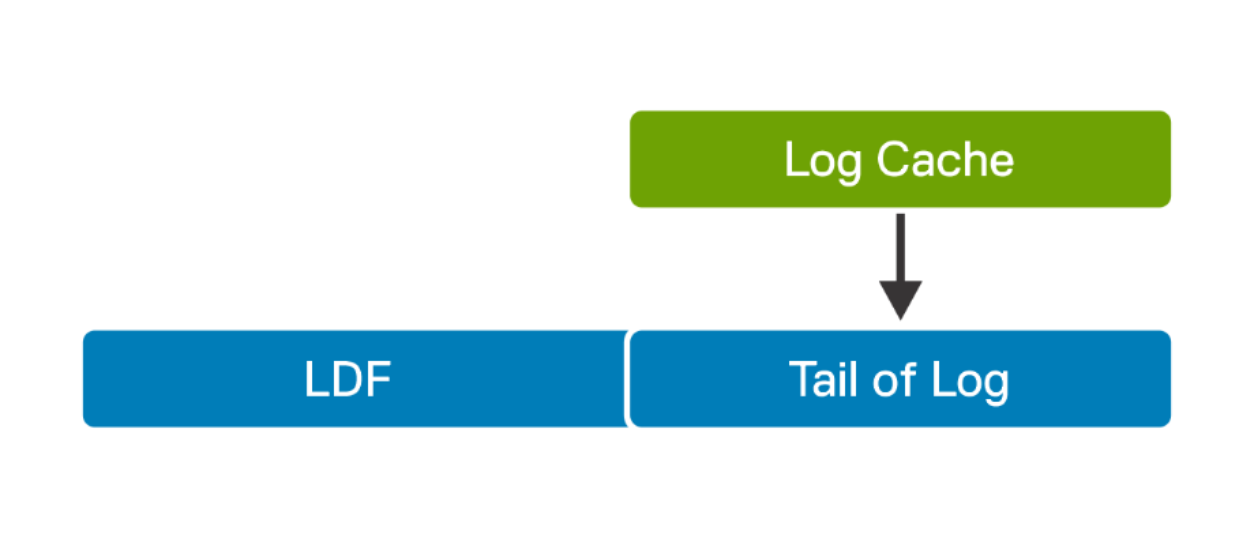
Figure 5. SQL Server log file
During crash recovery, SQL Server uses techniques such as parity bits to determine if the blocks in the Tail of Log have been successfully written.
Nonvolatile storage can be directly mapped into the process address space. This method means that SQL Server can use the memcpy function to copy the log record directly to nonvolatile storage at near DRAM speeds, avoiding the block storage stack (drivers, filter managers, anti-virus, and so on). The primary design behind the capabilities of SQL Server, Persistent Memory, and Direct Access is to use PMem as a stable cache for the Tail of Log write activities.
For more details, see the Microsoft blog about Tail of Log.
SQL Server enlightenment mode
When Intel Optane PMem devices are formatted with the DAX option in App Direct Mode, PMem offers byte-addressable storage that bypasses the Kernel I/O stack. SQL Server 2019 uses this feature (called enlightenment mode), which enables data and log file storage directly on the DAX-formatted volumes (see Create DAX volumes). Enlightenment mode enables placement of data and logs on faster PMEM storage. It accesses data and log files through direct memory access, which provides better transactional throughput.
The following figure shows the enlightenment mode architecture:
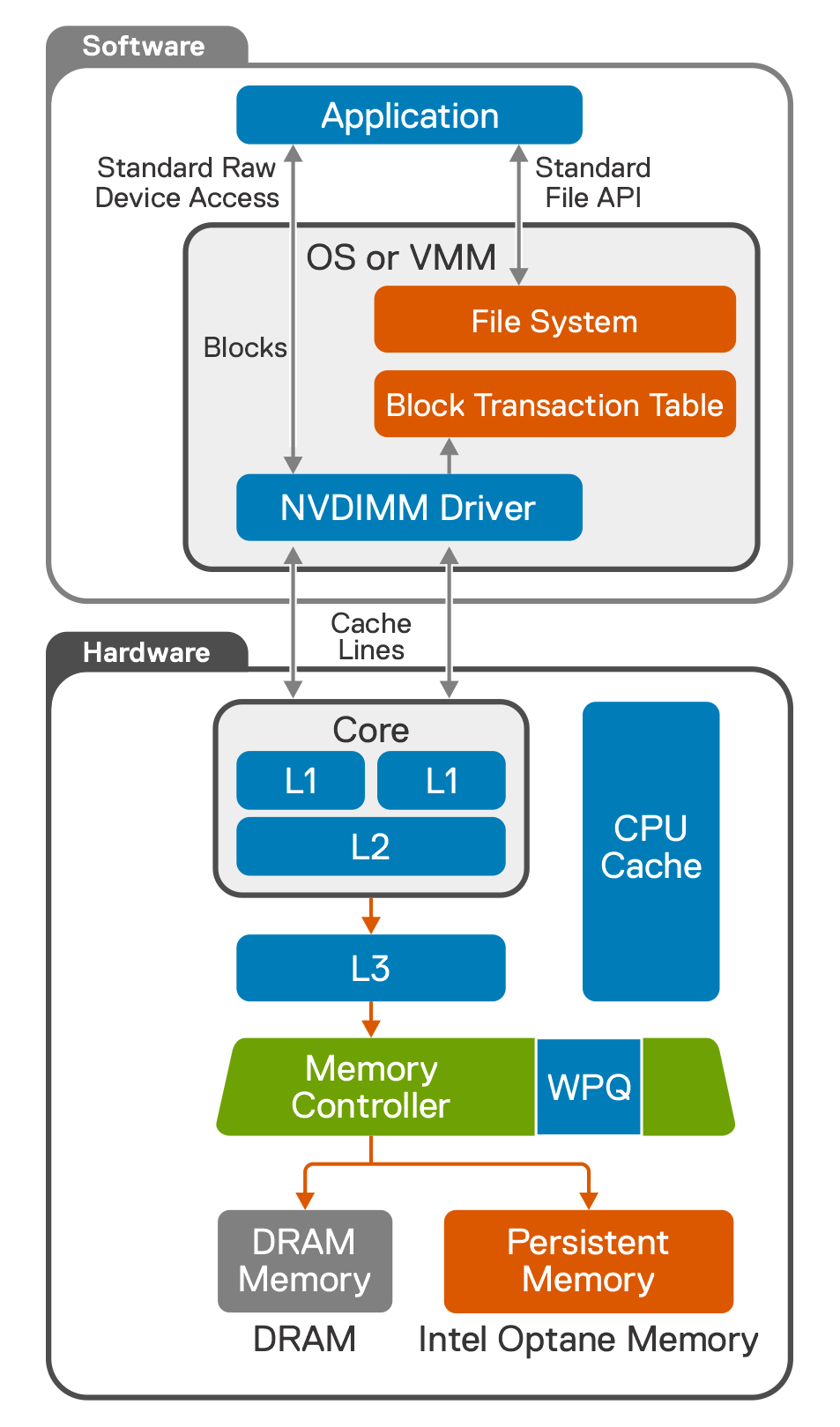
Figure 6. Enlightenment mode architecture
Enlightenment mode is fully supported only on Linux operating systems. Code backporting is not available on Windows Server. To use this feature, create a database on DAX-formatted volumes. The database is automatically enabled for enlightenment mode.
SQL Server hybrid buffer pool
SQL Server 2019 introduced the hybrid buffer pool feature, which requires PMem devices to be formatted with the DAX option. This feature is available for both Windows and Linux operating systems.
The hybrid buffer pool feature enables database engines to access data pages directly in database files that are stored on persistent memory devices, as shown in the following figure:
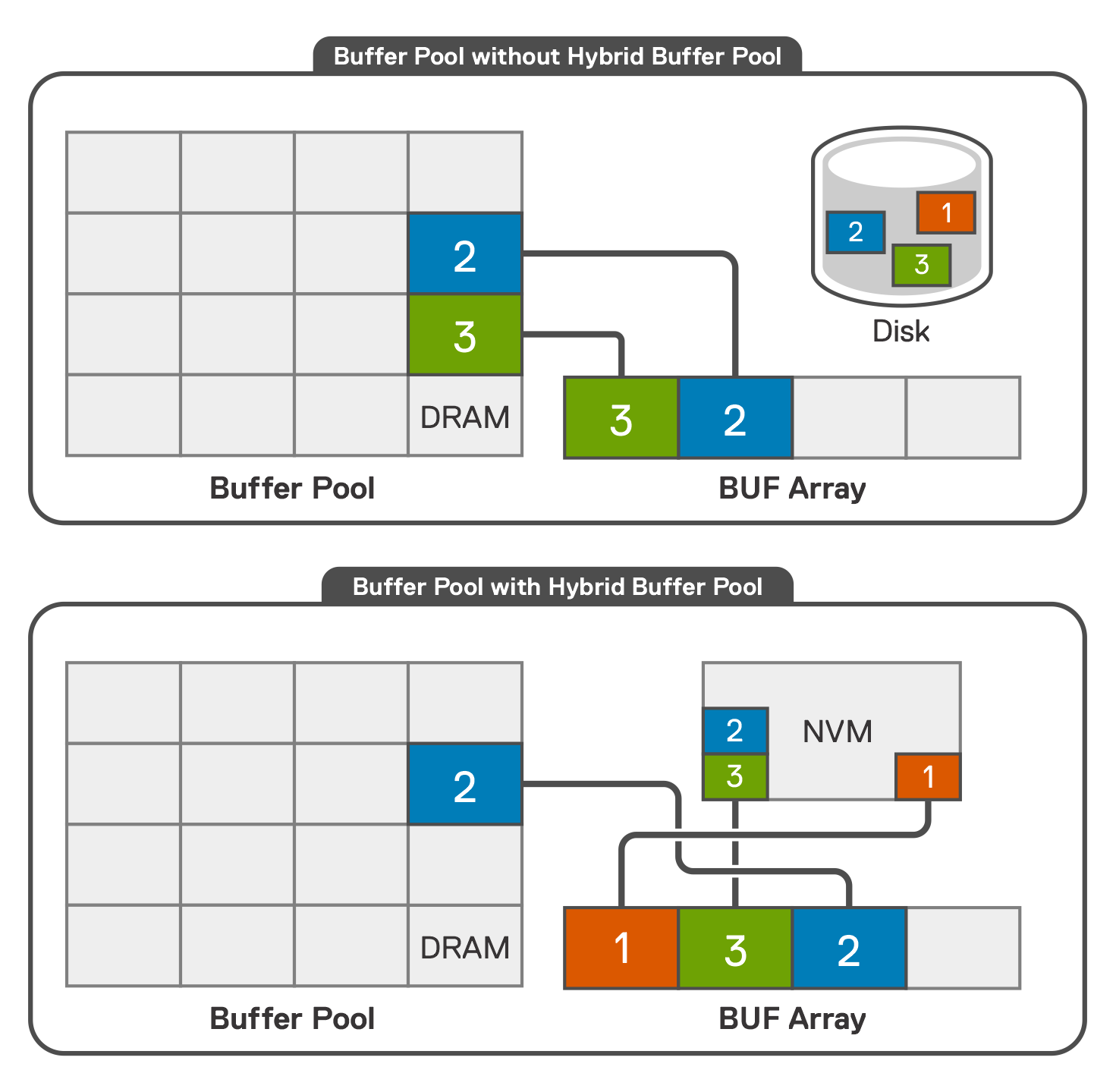
Figure 7. Hybrid buffer pool feature
NTFS, XFS, and EXT4 files systems support this feature.
When databases files are stored on PMem devices, SQL Server automatically detects if datafiles reside on an appropriately formatted PMem device and performs memory mapping in a user space. This mapping occurs during startup when a new database is attached, restored, or created, or when the hybrid buffer pool feature is enabled for a database.
In a traditional system without PMem, SQL Server caches data pages in the buffer pool. With hybrid buffer pool, SQL Server skips copying the page into the DRAM-based portion of the buffer pool. Instead, it accesses the page directly on the database file that resides on a PMem device. Read access to datafiles on PMem devices for hybrid buffer pool is performed directly by following a pointer to the data pages on the PMem device.
Only clean pages can be accessed directly on a PMem device. When a page is marked as dirty, it is copied to the DRAM buffer pool before eventually being written back to the PMem device and marked as clean again. This process occurs during regular checkpoint operations. Read-heavy workloads with a larger working set, which require more memory, often benefit from this feature.