None
None
-
We tested the performance of Llama 3 models with 8 billion (8B) and 70 billion (70B) parameters on PowerEdge XE9680 and R760xa servers under different concurrency levels to assess latency and throughput. The input sequence length and output sequence length are 128 input tokens and 128 output tokens.
Use case 1 PowerEdge XE9680 1x H100 GPU running Llama 3 8B FP16
Table 3.
XE9680-1xH100-Llama3-8B
Concurrency
Throughput (Tokens per second)
TTFT (milliseconds)
Request Latency (milliseconds)
1
161.24
13.54
910.25
5
739.52
18.15
980.23
10
1,432.17
20.20
995.33
25
3,157.75
30.34
1,114.61
50
5,259.70
55.36
1,300.56
100
6,446.96
279.76
2,131.47
250
6,162.70
970.54
5,295.10
500
10,024.80
4,428.95
7,069.01
1,000
10,926.83
6,838.69
8,864.83
Analysis:
The XE9680 with 1xH100 and Llama 3-8B model exhibited increasing throughput and manageable latency at lower concurrency levels (1-50 users), making it suitable for applications with moderate user activity. As concurrency increased to medium levels (100-250 users), throughput continued to rise, but latency also increased significantly, indicating the need to monitor and potentially scale the system. At high concurrency levels (500-1000 users), the model achieved high throughput levels. However, latency rose sharply, highlighting the system's limits in handling extensive concurrent requests without performance degradation.
Use case 1 XE9680 4x H100 GPU running Llama 3 70B model FP16
Table 4.
XE9680-4xH100-Llama3-70B
Concurrency
Throughput (Tokens per second)
TTFT (milliseconds)
Request Latency (milliseconds)
1
62.34
31.42
2,363.74
5
299.29
61.95
2,465.51
10
556.69
104.45
2,636.30
25
1,187.33
166.58
3,087.02
50
2,182.24
292.64
3,369.25
100
3,201.82
556.08
4,561.61
250
4,936.80
1,706.98
7,431.99
500
4,265.86
3,263.57
15,487.53
1000
5,611.07
11,542.23
22,678.19
Analysis:
For the XE9680 with 4xH100 running the Llama 3 70B model, initial throughput was lower compared to the 8B model due to the increased complexity of the 70B model, resulting in higher latency. This configuration is suitable for high-value tasks that can tolerate some delay. At medium concurrency levels, significant improvements in throughput with manageable latency increases were observed, indicating that this setup can handle more complex tasks efficiently. However, at high concurrency levels, throughput remained substantial, but latency increased sharply, highlighting the system's limits for handling high concurrent loads without impacting performance.
Use case 1 R760xa 1x L40S GPU running Llama 3 8B model FP16
Table 5.
R760xa-1xL40S-Llama3-8B
Concurrency
Throughput (Tokens per second)
TTFT (milliseconds)
Request Latency (milliseconds)
1
53.71
33.46
2,698.30
5
249.31
54.28
2,854.27
10
479.67
78.09
2,912.61
25
1,086.27
141.52
3,284.64
50
1,854.96
299.20
3,641.89
100
2,905.39
533.51
4,508.08
250
4,626.81
1,685.32
7,569.94
500
4,528.44
7,317.11
14,084.20
1000
4,478.56
18,309.85
25,196.30
Analysis:
The R760xa with 1xL40S running the Llama 3-8B model showed moderate throughput and higher latency compared to the XE9680, reflecting the differences in hardware configuration. This setup is suitable with fewer concurrent users. Throughput improved at medium concurrency levels, but latency increased, making it good for moderate workloads. However, at high concurrency levels, high latency was observed, indicating the system's upper limits and suggesting the need for scaling or load balancing.
Use case 1 R760xa with 4x L40S GPU running Llama 3 70B model with quantization of FP8.
Table 6.
R760xa-4xL40S-Llama3-70B
Concurrency
Throughput (Tokens per second)
TTFT (milliseconds)
Request Latency (milliseconds)
1
33.39
80.64
4,554.13
5
126.85
173.73
5,475.03
10
234.16
330.41
5,882.94
25
471.05
817.30
7,239.88
50
730.19
1,411.97
9,280.34
100
1078.76
3,069.40
13,486.35
250
1174.84
9,219.88
26,403.18
500
1198.33
26,148.34
43,852.62
1000
1192.26
36,372.65
54,219.16
Analysis:
The throughput and latency metrics for the R760xa with 4xL40S running the Llama 3-70B model with FP8 quantization provided an interesting contrast. At low concurrency (1-50 users), the system showed lower throughput and higher latency compared to the 8B model configurations, reflecting the increased computational demand of the 70B model. As concurrency increased, throughput improved significantly, but latency also rose sharply, especially at higher concurrency levels (250-1000 users). This suggests that while the system can handle high-volume tasks, managing latency carefully is essential to avoid performance bottlenecks.
Key Observations
Latency and throughput are crucial in determining the scalability and efficiency of AI models. At 500 concurrent users, the 8B model using 1xH100 on the XE9680 showed the lowest latency (<30ms), making it ideal for real-time applications. The 8B model on the R760xa exhibited approximately 40ms latency, indicating slightly less efficiency but still suitable for many real-time tasks. The 70B model on the XE9680 showed around 80ms latency, reflecting its increased computational complexity, and suggesting this configuration for less latency-sensitive applications.
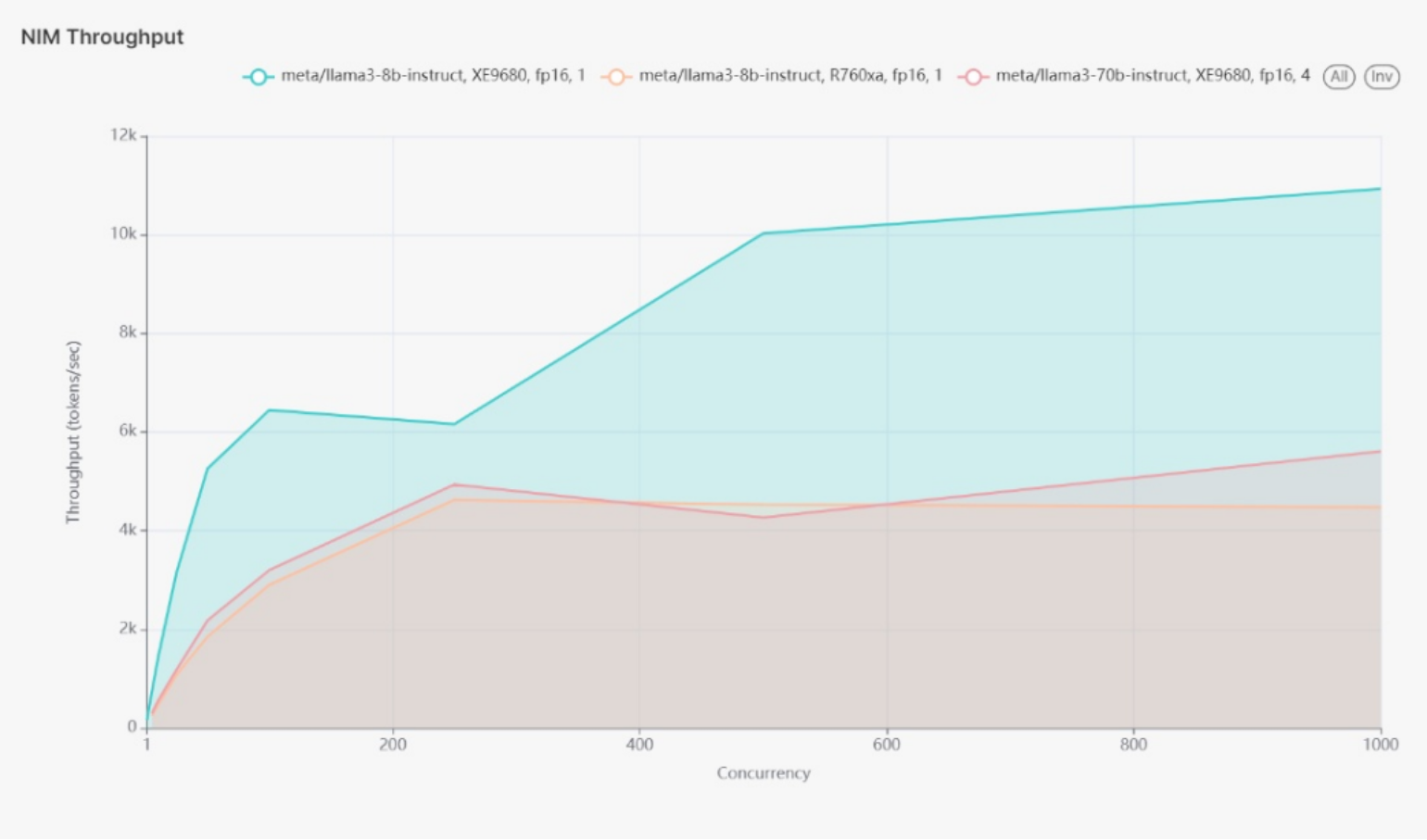
In terms of throughput, the highest throughput (~10k tokens/sec) was achieved by the 8B model on the XE9680 at 500 concurrent users, demonstrating its capability to handle high-volume tasks efficiently. Other models had a throughput of around 5k tokens/sec with 500 active users, which is still substantial but highlights the impact of model complexity on performance.
Figure 1 shows graph of latency for three instances for use case 1 running FP16. Note, the 70B model in figure 1 has 4 GPUs assigned.
Figure 1.
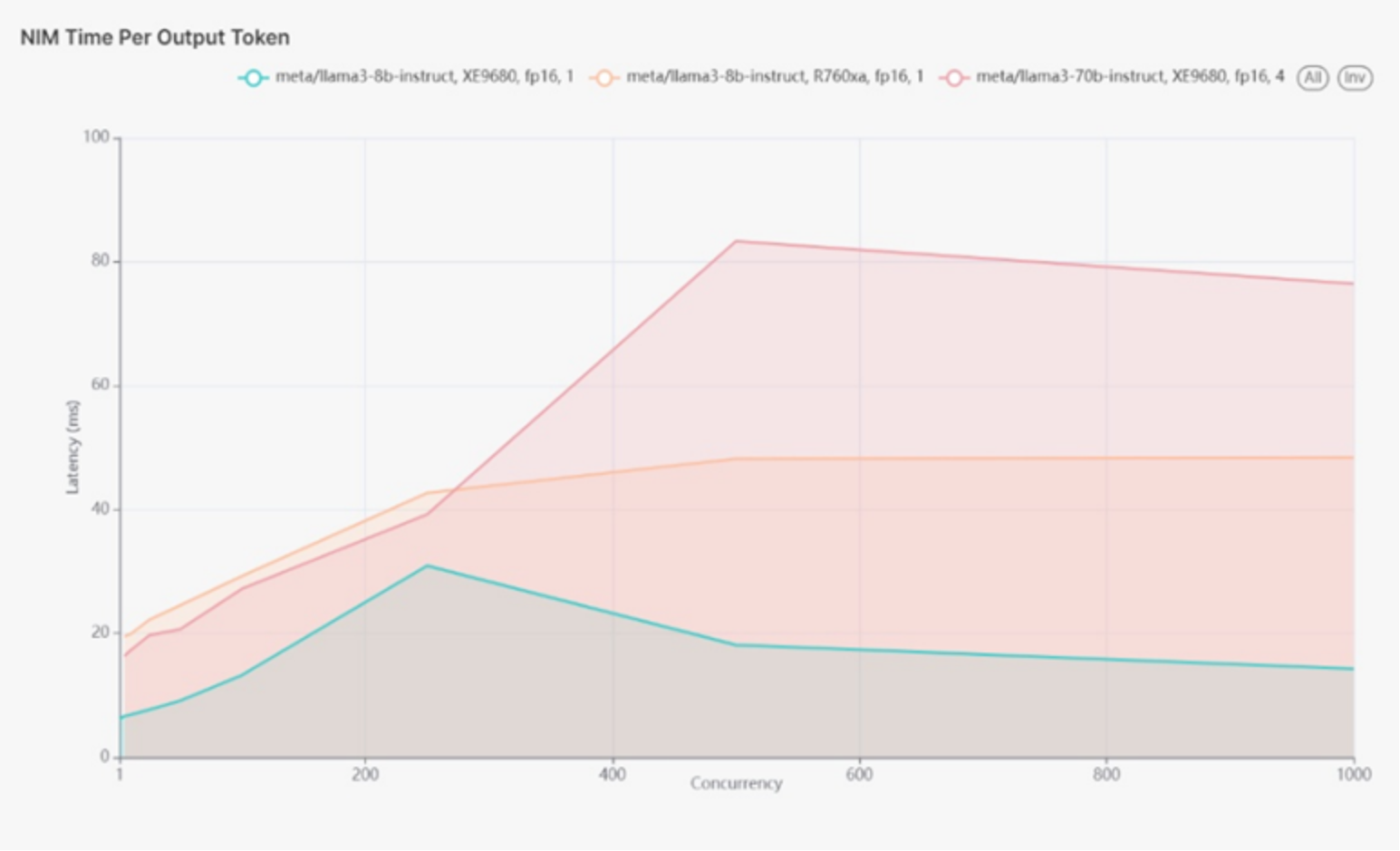
Figure 2 shows graph of use case 1 Throughput (Tokens per second)
Figure 2.