
Machine Learning Using Red Hat OpenShift Container Platform
Distributed versus non-distributed training
Distributed versus non-distributed training
-
Performance comparison
We compared the performance results from running the TensorFlow benchmark on a single application node (non-distributed training) with using training on two application nodes (one PS node and two worker nodes). The following figure shows the results:
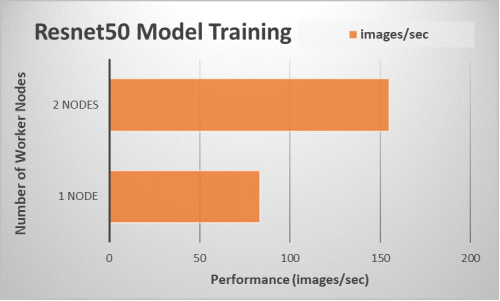
Figure 10. Performance scaling for model training using multiple server nodes
The throughput shows that a training job using two application nodes is almost 1.9 times faster than a training job using a single application node. Using the optimized Tensorflow framework distribution from Intel and applying the appropriate parameters when launching a training job enables the ML practitioner to run their Tensorflow jobs efficiently on Intel Xeon Scalable processors.