
Experiment Results
Experiment Results
-
The latency (throughput) and FLOPS (FWD FLOPS per GPU) were measured by passing batch size and prompts (each prompt has a constant token size of 11) to the model with the results plotted. We found that the throughput of the model had a near perfect linear relationship with the number of prompts provided (Figure 4). The plot shows the trendline with a Pearson correlation coefficient (R2) as 1. The mean latency can be calculated by extrapolating this linear trend and is calculated as follows:
Latency = 79.081× (Number of prompts) + 212.7
Furthermore, the average efficiency of the model (a direct function of TFLOPS) increased rapidly to reach an inflection point, after which, the efficiency remained nearly constant (Figure 5). This inflection point is directly related to the computational capability of the underlying hardware. Computational efficiency is typically calculated by dividing the total FLOPS by the theoretical max FLOPS of the underlying hardware. The throughput of the A100 accelerator is measured in tokens per second. The results can be found in the following table.
Table 4. Throughput and latency of tokens as processed by the accelerator.
Number of Prompts
Latency (ms)
TFLOPS
Tokens
Latency (s)/ token
Throughput (Tokens)
1
340.58
14.97
11
0.03096
32
2
372.52
23.21
22
0.01693
59
4
463.74
35.11
44
0.01054
95
8
873.87
44.53
88
0.00993
101
16
1490.00
52.51
176
0.00847
118
24
2030.00
55.85
264
0.00769
130
100
8180.00
60.67
1,100
0.00744
134
1,000
79290.00
62.29
11,000
0.00721
139
Conversely, when the number of prompts was kept constant (in our case, 1) and the batch size was varied there was no correlation found in the latency (Figure 6) and efficiency (Figure 7) of the model. This is shown in the plots by the trendlines along with the Pearson correlation coefficient (R2).
We also found when the maximum batch size was set to 68, an out of memory error occurred (Table 5). By running the model (prompt = 1, token size = 11) several times using the maximum batch size parameter, we found that an average of 0.39 GiB (Gigabyte) is reserved for each batch on an A100. For a maximum batch size of 68, 26.52 GiB (68 x 0.39 GiB) of free memory is required to run the model. However, the free memory available for this allotment is only 25.92 GiB after the model is loaded (Figure 3).

Figure 3. Screenshot showing system out-of-memory error when a batch size of 68
Table 5. GPU utilization and memory usage is captured by varying the maximum batch size parameter
Max. Batch Size
GPU Utilization (%)
Total Memory (GiB)
Free Memory (GiB)
Used Memory (GiB)
1
50
40.00
25.92
14.08
2
50
40.00
25.48
14.52
67
50
40.00
0.10
39.90
68
Out of Memory Error
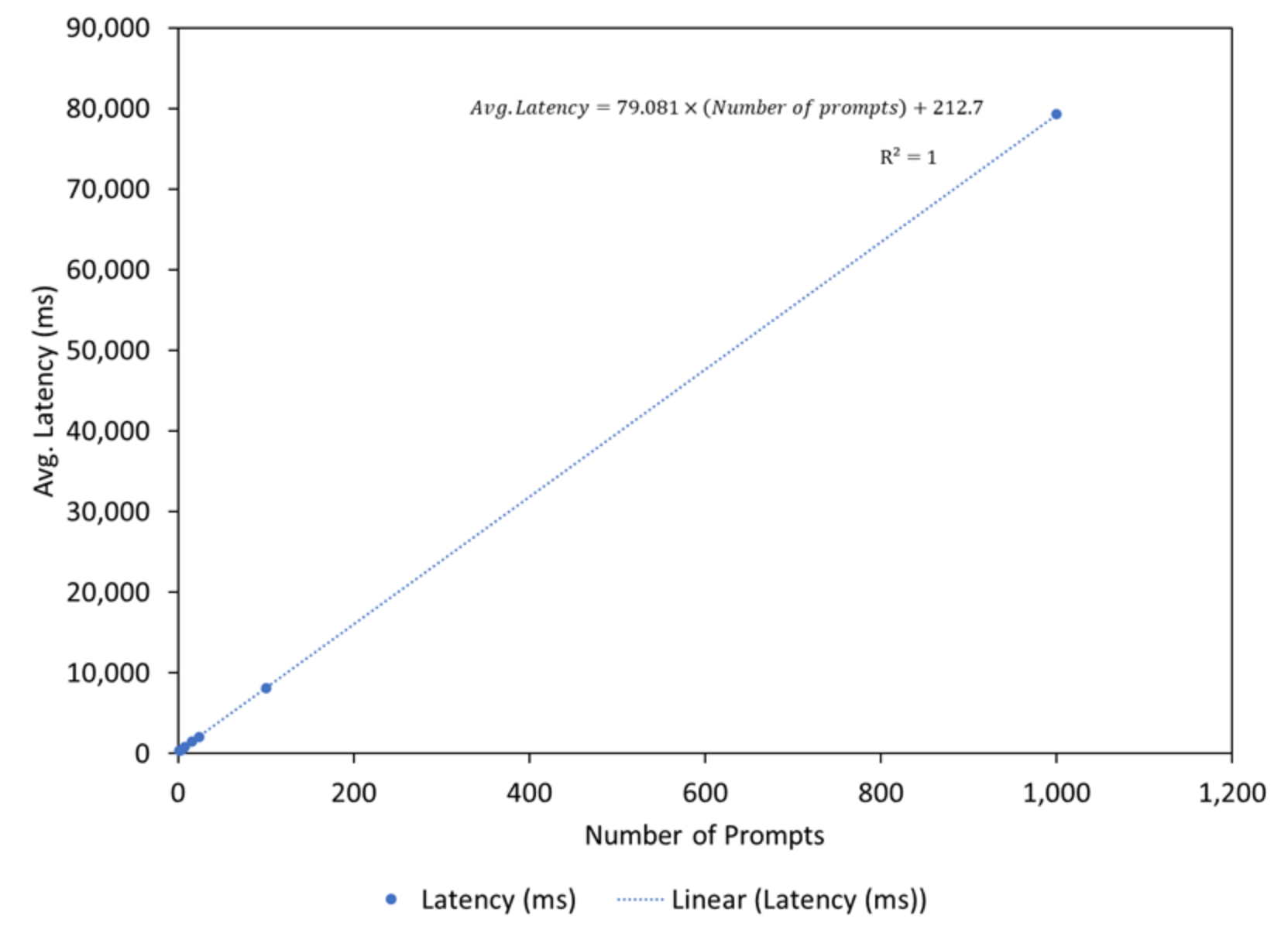
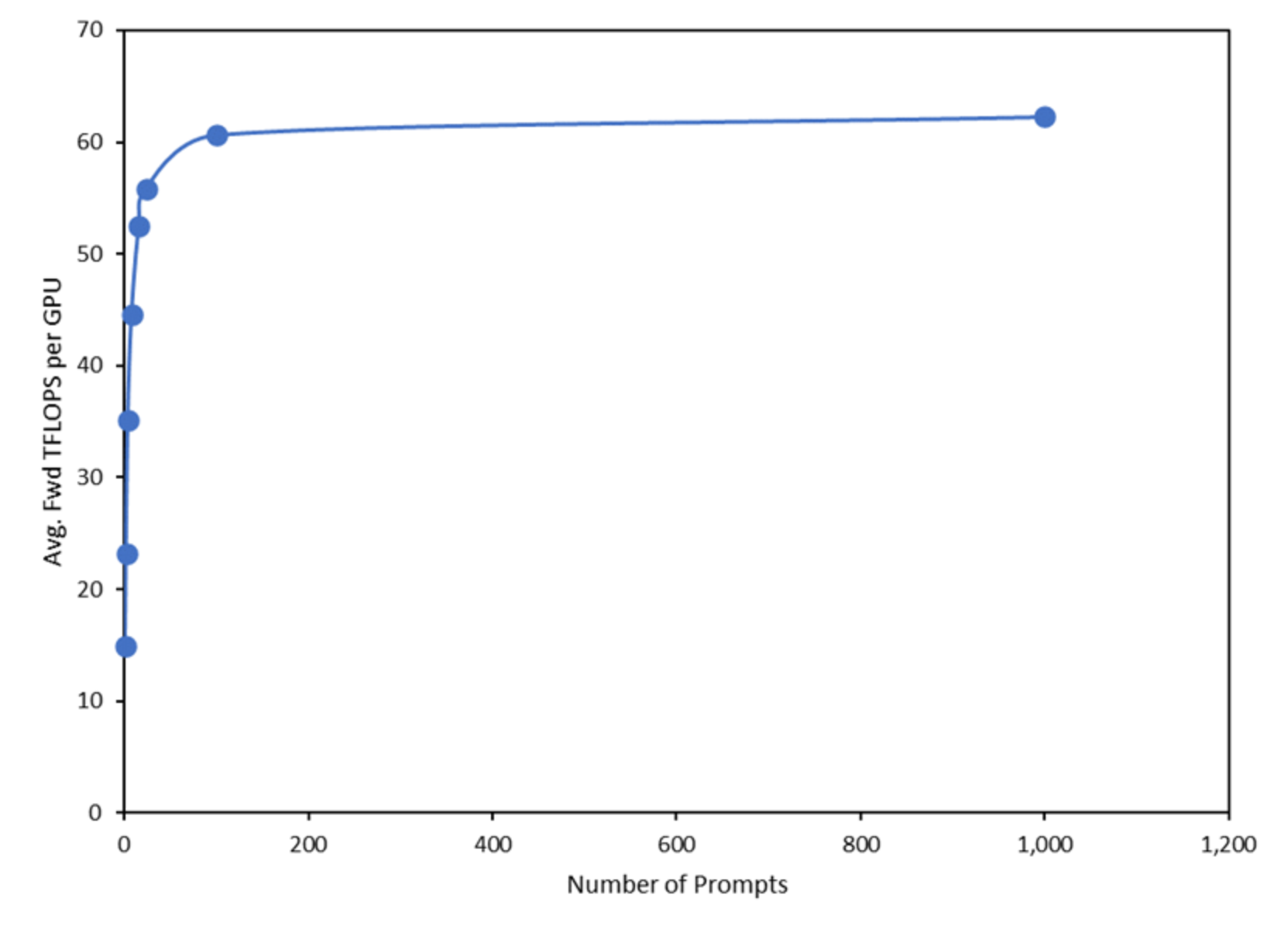
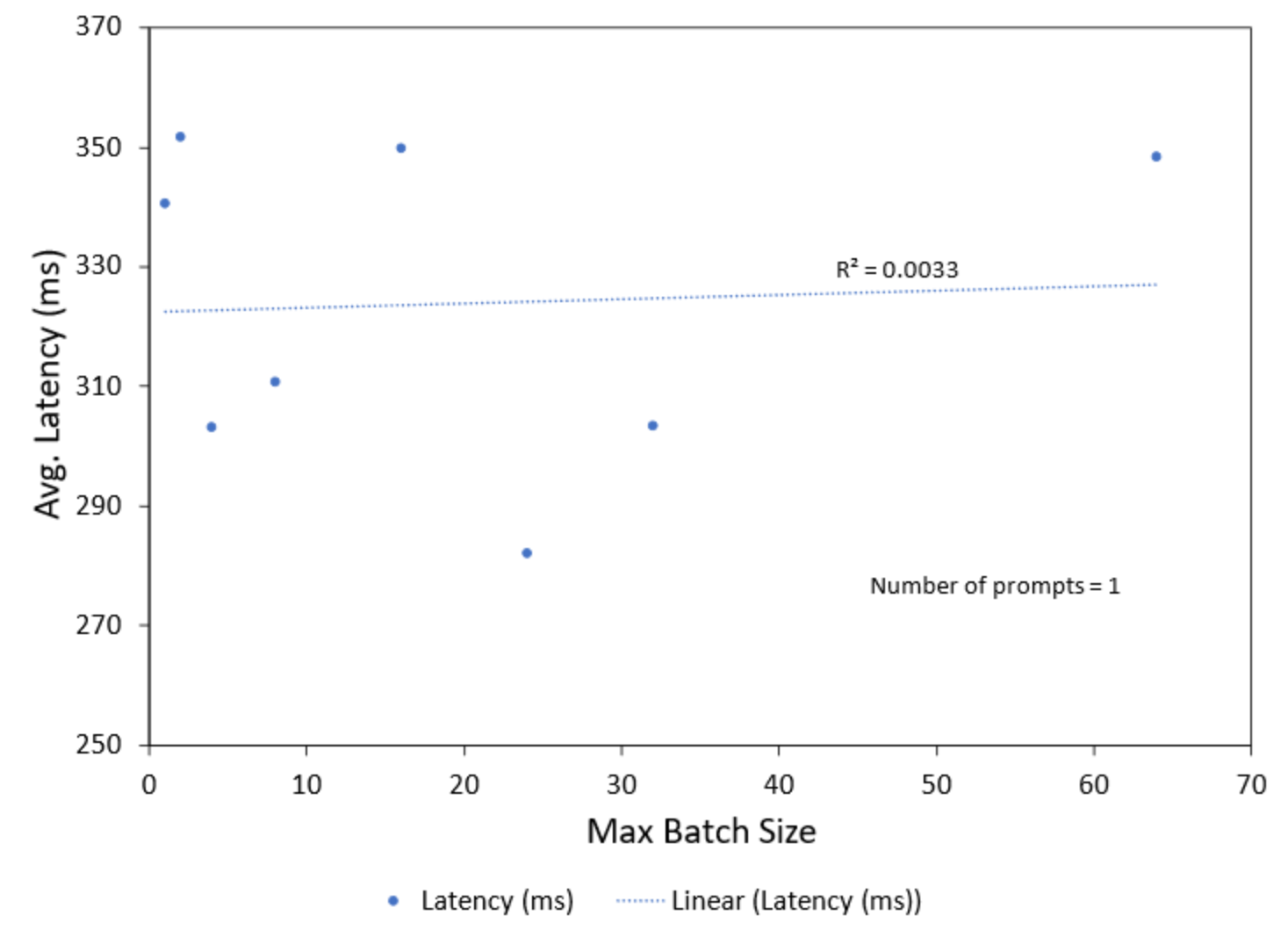
Figure 6. Latency of the model with varying batch size
